Command Palette
Search for a command to run...
MAKIEVAL: إطار عمل تلقائي متعدد اللغات يعتمد على ويكي بيانات لتقييم الوعي الثقافي في نماذج اللغة الكبيرة
MAKIEVAL: إطار عمل تلقائي متعدد اللغات يعتمد على ويكي بيانات لتقييم الوعي الثقافي في نماذج اللغة الكبيرة
Raoyuan Zhao Beiduo Chen Barbara Plank Michael A. Hedderich
الملخص
تُستخدم النماذج اللغوية الكبيرة (LLMs) على نطاق عالمي عبر العديد من اللغات، إلا أن تدريبها الأولي الذي يركز على اللغة الإنجليزية يثير مخاوف بشأن الفوارق بين اللغات في مستوى الوعي الثقافي، مما يؤدي غالباً إلى مخرجات متحيزة. ومع ذلك، يبقى التقييم متعدد اللغات الشامل تحدياً بسبب محدودية أدوات القياس (benchmarks) وجودتها التراجومية المشكوك فيها. وللتقييم الدقيق لهذه الفوارق، نقدم MAKIEVAL، وهو إطار عمل تلقائي متعدد اللغات لتقييم الوعي الثقافي في النماذج اللغوية الكبيرة عبر اللغات والمناطق والمواضيع المختلفة. يقيم MAKIEVAL توليد النصوص المفتوحة، ويسجل كيف تعبر النماذج عن المعرفة المستندة إلى السياق الثقافي بلغة طبيعية. واستناداً إلى البنية متعددة اللغات لمكتبة ويكي بيانات (Wikidata) كمرجعية عابرة للغات، يحدد الإطار تلقائياً الكيانات الثقافية في مخرجات النماذج ويربطها بمعرفة منظمة، مما يتيح تقييماً قابلاً للتوسع ولا يعتمد على لغة معينة دون حاجة إلىAnnotation يدوي أو ترجمة. ثم نقدم أربعة مقاييس تلتقط أبعاداً مكملة للوعي الثقافي: الدقة (granularity)، والتنوع، والخصوصية الثقافية، والإجماع عبر اللغات. وقيّمنا سبع نماذج لغوية كبيرة (LLMs) طُوّرت من مناطق مختلفة من العالم، وتشمل أنظمة مفتوحة المصدر وأنظمة مغلقة، عبر 13 لغة، و19 دولة ومنطقة، و6 مواضيع ذات دلالة ثقافية بارزة (مثل الطعام والملابس).
One-sentence Summary
MAKIEVAL, a multilingual automatic framework leveraging Wikidata’s structured knowledge, evaluates cultural awareness in LLMs by identifying culturally grounded entities in open-ended text, introducing four metrics for granularity, diversity, cultural specificity, and cross-lingual consensus, and assessing seven models across thirteen languages, nineteen countries and regions, and six cultural topics without manual annotation or translation.
Key Contributions
- MAKIEVAL is introduced as an automatic multilingual evaluation framework that uses Wikidata as a cross-lingual anchor to identify cultural entities in open-ended LLM outputs, enabling scalable assessment without manual annotation or translation.
- Four metrics are defined—granularity, diversity, cultural specificity, and cross-lingual consensus—to capture complementary dimensions of cultural awareness in generated text.
- Experiments across 7 LLMs, 13 languages, 19 countries/regions, and 6 cultural topics show that prompting language strongly influences cultural expression, and a public dataset of model outputs and extracted cultural entities is released to support further analysis.
Introduction
The authors address the challenge of evaluating cultural awareness in large language models (LLMs), a critical concern as these systems are deployed globally yet often exhibit biases rooted in their English-centric training. Prior evaluation methods are limited by their reliance on simplified test formats like multiple-choice questions, narrow monolingual or translation-dependent setups, and static benchmarks that cannot scale to capture the fluid nature of cultural expression in open-ended text generation. The authors introduce MAKIEVAL, an automatic and multilingual evaluation framework that leverages Wikidata’s structured knowledge base as a language-agnostic anchor. This approach enables the assessment of cultural awareness directly in generated text without manual annotation or translation, using four novel metrics that measure granularity, diversity, cultural specificity, and cross-lingual consensus.
Dataset
Here is a concise dataset description based on the provided paper paragraphs.
The authors construct a multilingual evaluation framework centered on open-ended text generation. The core dataset is not a static collection of texts but a structured set of prompts and a subsequent pipeline for extracting and enriching cultural entities from model responses.
Dataset Composition and Sources
- Prompts: The primary input data consists of structured text prompts across 13 languages and 6 cultural topics.
- Entity Metadata: Extracted entities are matched to Wikidata to retrieve structured metadata, including unique QIDs, descriptions, country of origin, and author/performer nationality.
Key Details for Each Subset
- Languages (13 total): Arabic, English, German, Hindi, Italian, Japanese, Korean, Persian, Simplified Chinese, Spanish, Thai, Traditional Chinese, and Turkish. These span multiple families, writing systems, and geographic regions.
- Topics (6 total): Food, beverages, clothing, books, music, and transportation, chosen as culturally meaningful aspects of daily life.
- Prompt Conditions (3 types):
- Explicit Contextualized: The cultural background is directly stated (e.g., "about a person from Spain").
- Implicit Contextualized: A culturally associated name is used as a hint (e.g., "about Juan").
- Neutral: No nationality, ethnicity, or location is mentioned, to assess the model's default cultural preferences.
How the Paper Uses the Data
- Generation: The prompts are used to elicit open-ended text from LLMs. For models exhibiting language misalignment (e.g., Mistral responding in English, Qwen in Chinese), a language-specific instruction is appended to enforce consistency.
- Entity Extraction: The authors use GPT-4o-mini to extract topic-relevant cultural entities from the generated text and classify them by semantic granularity (e.g., distinguishing a specific dish from an ingredient class).
- Entity Matching and Disambiguation: Extracted entities are matched to Wikidata entries using labels and aliases in the prompt's language, with a fallback to English. A recursive disambiguation procedure traverses ontological relations (instance of, subclass of) to resolve ambiguous labels by checking if any semantic path leads to a culturally relevant category.
Processing and Metadata Construction
- Prompt Validation: All prompt templates were reviewed by 15 native speakers, with at least one annotator per language, to ensure linguistic accuracy and cultural appropriateness.
- Metadata Table: All matched entities are compiled into a structured table supporting quantitative and qualitative analysis. Each entry contains the entity's QID, surface labels in multiple languages, granularity tags, and country/region-level information. Entities that fail disambiguation are discarded from evaluation.
Method
The authors introduceMAKIEVAL, an automatic and multilingual evaluation framework designed to assess cultural awareness in language models. As shown in the figure below, the pipeline operates through four sequential steps: text generation, cultural entity extraction, Wikidata-based entity matching, and metric-based analysis.
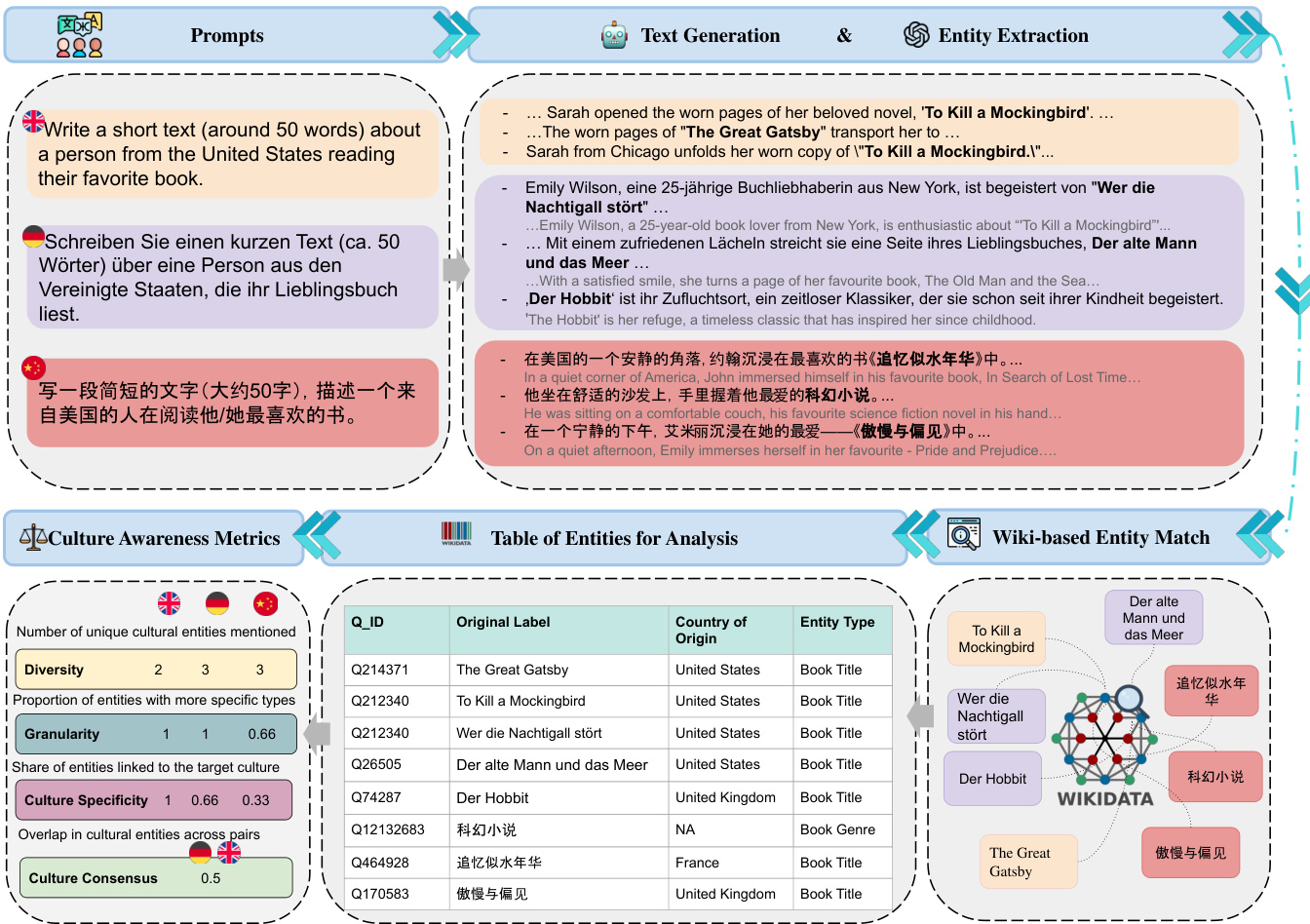
The process begins with text generation, where the model is prompted with the same query across different languages. Following generation, the system performs cultural entity extraction. The authors leverage dynamic prompts that switch branches based on the specific topic, extracting topic-specific entities alongside named entities like person names and geographic locations. Each extracted entity is also assigned a granularity label. Since Wikidata hierarchies proved inconsistent for this purpose, the authors employ ChatGPT-4-o-mini to infer granularity, categorizing entities into specific references (scored as 1) or general categories (scored as 0). The final granularity score is the average of these binary values.
Next, the extracted entities undergo Wikidata-based entity matching. Each entity is linked to a Wikidata QID to retrieve metadata such as country of origin and entity type, forming a comprehensive table of entities for analysis. Let E denote the union of all predicted entities across responses for a specific evaluated LLM and prompt.
Finally, the framework applies four metrics to evaluate different aspects of cultural awareness: Granularity, Diversity, Culture Specificity, and Culture Consensus. Culture Consensus quantifies the agreement between model outputs for the same topic and cultural context across different languages. Let QA and QB denote the sets of Wikidata QIDs extracted from responses to the same prompt in languages A and B, respectively. The authors compute their overlap using Jaccard similarity:
Consensus(A,B)=∣QA∪QB∣∣QA∩QB∣.Higher consensus indicates more stable cultural grounding across languages, suggesting the model maintains consistent cultural knowledge despite surface linguistic variation.
Experiment
The evaluation framework assesses seven multilingual language models across 13 languages and 6 cultural topics using four metrics: granularity, diversity, culture specificity, and cultural consensus. Experiments reveal that granularity remains stable for a given model-language pair regardless of the cultural context, while diversity varies widely by model and is often higher when prompting in a country's native language, though this is not guaranteed. Culture specificity increases when explicit cultural context is provided, with English prompts showing the highest gains, and cultural consensus highlights that European languages share more aligned entity representations, suggesting that both language and regional cultural connections shape model outputs. The findings emphasize that these metrics are complementary and their desirability depends on the downstream task, rather than prescribing universally optimal values.
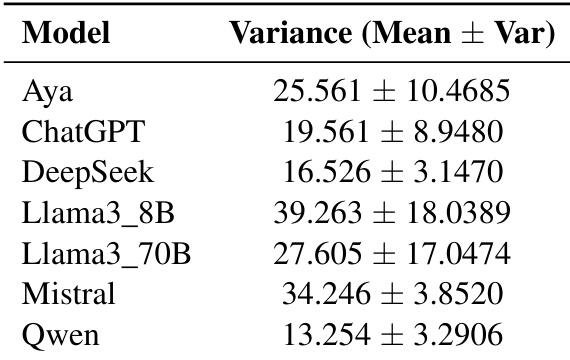
The authors evaluate cultural diversity across seven multilingual language models by measuring the number of unique cultural entities generated. Results indicate significant variation in diversity scores among models, with Llama3-8B and Mistral demonstrating higher diversity levels compared to others like DeepSeek and Qwen, which show more restricted output variation. Llama3-8B and Mistral achieve the highest average diversity, suggesting a richer generation of distinct cultural entities. DeepSeek and Qwen exhibit the lowest average diversity and variance, indicating more repetitive cultural outputs. Increasing model size from the 8B to the 70B parameter version of Llama3 results in a decrease in average diversity.
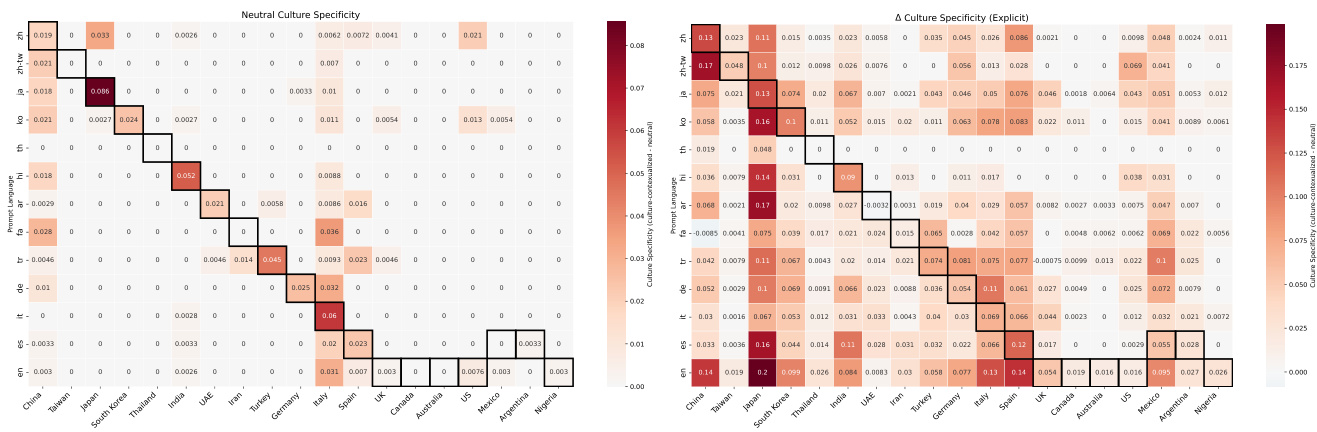
The authors evaluate cultural specificity by comparing model outputs for neutral prompts against those with explicit cultural contexts. Results indicate that neutral prompts naturally exhibit higher specificity when the prompt language matches the native language of the referenced country. Furthermore, adding explicit cultural context generally increases specificity across most combinations, with English prompts showing the most substantial gains. Neutral prompts produce higher cultural specificity when the prompt language matches the native language of the target country. Explicitly providing cultural context in the prompt increases cultural specificity across most language and country pairs. English prompts consistently achieve the largest specificity gains when cultural context is explicitly added.
The authors evaluate cultural consensus across various multilingual language models to measure how similarly cultural entities are represented across different prompt languages. Results indicate that larger models tend to achieve higher and more consistent consensus scores compared to smaller models. However, model size is not the sole determinant, as significant variations in consensus are observed among smaller models of comparable scale. The largest models in the evaluation achieve the highest and most consistent cultural consensus scores. There is substantial variation in consensus among smaller models, indicating that size is not the only influencing factor. Mistral records the lowest cultural consensus score across all tested models.
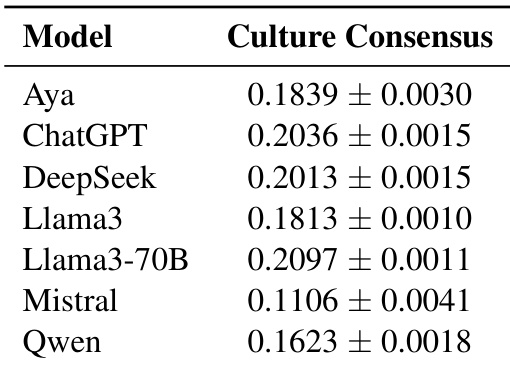
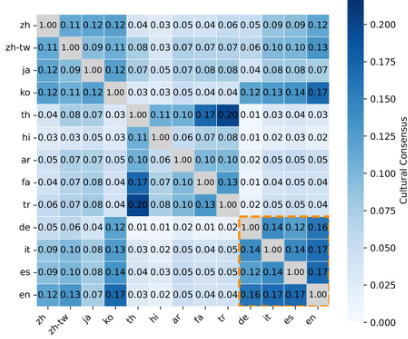
The authors evaluate cultural consensus to measure how similarly models represent cultural entities across different prompt languages. Results indicate that model size influences consensus levels, with larger models showing more consistent scores. Additionally, the analysis reveals strong intra-regional alignment, particularly among European languages and between Japanese and Korean, suggesting that shared cultural perspectives in training data shape cross-lingual representations. Model size appears to influence cultural consensus, with larger models achieving similar alignment scores across languages. European languages exhibit higher cultural consensus among themselves, suggesting shared regional perspectives in training data. Japanese and Korean show strong consensus, indicating that latent cultural connections shape cross-lingual entity representations.
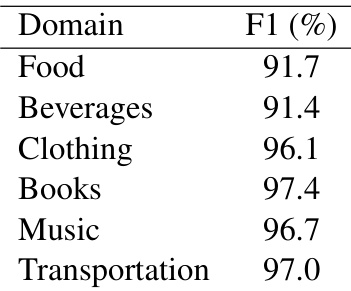
The authors evaluate the performance of their entity extraction pipeline across different cultural domains in English. The results indicate that the extraction model achieves consistently high accuracy across all tested categories, demonstrating the reliability of the method for identifying cultural entities. The entity extraction model performs strongly across all cultural domains, maintaining high accuracy throughout. Categories such as Books, Music, and Transportation achieve higher extraction accuracy compared to Food and Beverages. The overall results remain consistently strong despite slight variations in performance across different domains.
The evaluation measures cultural diversity, specificity, and consensus across seven multilingual language models using entity extraction from varied prompts. Models like Llama3-8B and Mistral generate more distinct cultural entities, while DeepSeek and Qwen produce more repetitive outputs, and scaling Llama3 from 8B to 70B parameters surprisingly reduces diversity. Cultural specificity improves when prompts include explicit cultural context, with English prompts benefiting most, and neutral prompts are more specific when the prompt language matches the target country's native language. Larger models achieve higher and more consistent cultural consensus scores, though smaller models vary widely, and analysis reveals strong intra-regional alignment among European languages and between Japanese and Korean, indicating shared cultural perspectives in training data.