Command Palette
Search for a command to run...
الاستدلال الطبي في نماذج اللغات الكبيرة: تحليل متعمق لـ DeepSeek R1
الاستدلال الطبي في نماذج اللغات الكبيرة: تحليل متعمق لـ DeepSeek R1
Birger Moëll Fredrik Sand Aronsson Sanian Akbar
نشر DeepSeek R1 7B باستخدام vLLM
الملخص
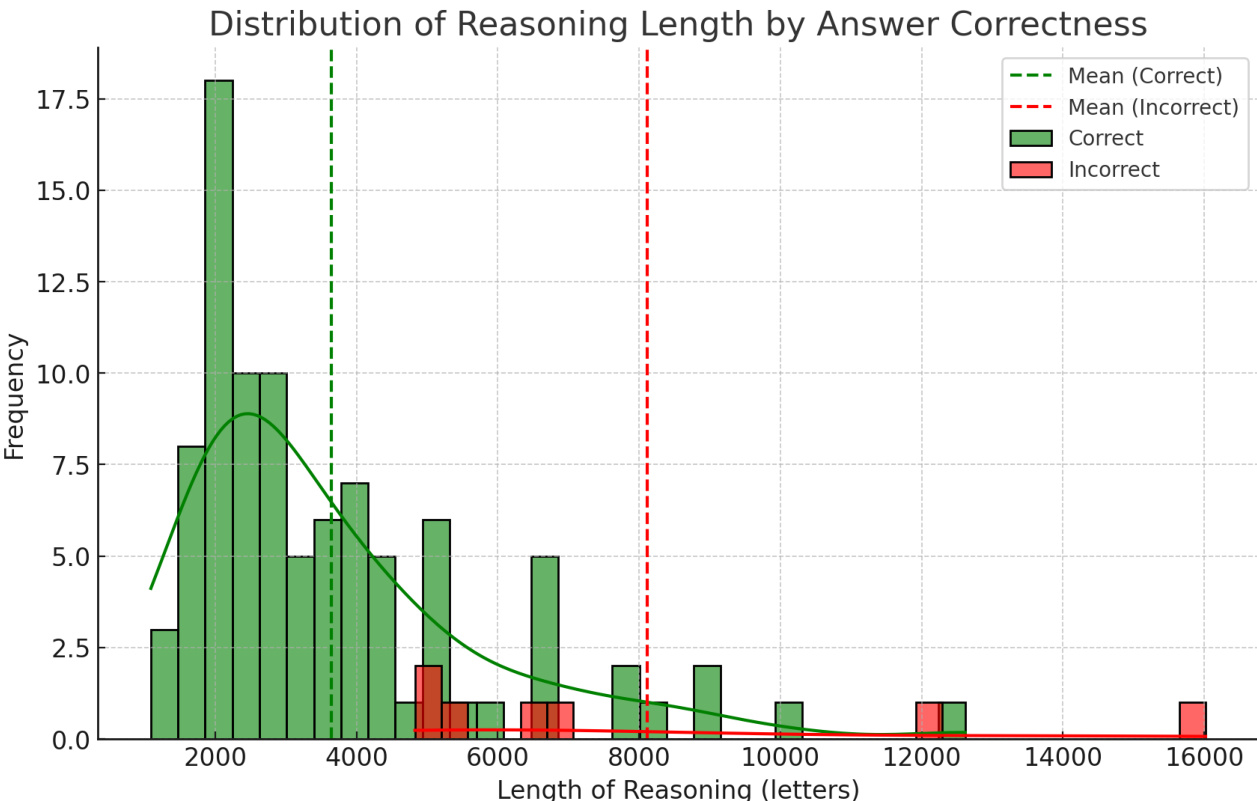
يتمتع دمج النماذج اللغوية الكبيرة (LLMs) في مجال الرعاية الصحية بإمكانيات هائلة، لكنه يثير أيضاً تحديات حاسمة، لا سيما فيما يتعلق بقدرة هذه النماذج على تفسير عمليات الاستدلال الخاصة بها وموثوقيتها. وعلى الرغم من أن نماذج مثل DeepSeek R1، التي تدمج خطوات استدلال صريحة، تُظهر وعوداً بتحسين الأداء والقدرة على الشرح، إلا أن مواءمتها مع أنماط الاستدلال المتبعة من قبل الخبراء في المجال الطبي لا تزال غير مدروسة بشكل كافٍ. تهدف هذه الورقة البحثية إلى تقييم قدرات الاستدلال الطبي لدى نموذج DeepSeek R1، ومقارنة مخرجاته بأنماط الاستدلال المتبعة من قبل خبراء المجال الطبي. ومن خلال إجراء تحليلات نوعية وكمية لـ 100 حالة سريرية متنوعة من مجموعة بيانات MedQA، نوضح أن نموذج DeepSeek R1 يحقق دقة تشخيصية تبلغ 93%، ويُظهر أنماطاً من الاستدلال الطبي. وكشف تحليل الحالات السبع التي احتوت على أخطاء عن عدة أخطاء متكررة، وهي: تحيز التثبيت (anchoring bias)، وصعوبة دمج البيانات المتضاربة، وقلة النظر في التشخيصات البديلة، والإفراط في التفكير (overthinking)، وعدم اكتمال المعرفة، والأولوية للعلاج الحاسم على الخطوات الوسطى الحاسمة. وتسلط هذه النتائج الضوء على المجالات التي تحتاج إلى تحسين في عمليات الاستدلال الخاصة بالنماذج اللغوية الكبيرة لتطبيقاتها الطبية. وتجدر الإشارة إلى أن طول عملية الاستدلال كان أمراً مهماً، حيث كانت الاستجابات الأطول تحمل احتمالاً أعلى لحدوث الأخطاء.
One-sentence Summary
Through a qualitative and quantitative analysis of 100 MedQA clinical cases compared to medical expert reasoning patterns, this study evaluates DeepSeek R1, revealing 93% diagnostic accuracy alongside recurring errors identified in seven cases and demonstrating that longer reasoning responses significantly increase error probability.
Key Contributions
- This paper introduces a systematic evaluation framework that aligns the explicit reasoning steps of DeepSeek R1 with established medical domain expert patterns.
- Qualitative and quantitative analyses of 100 diverse clinical cases from the MedQA dataset demonstrate that the model achieves 93% diagnostic accuracy while exhibiting coherent medical reasoning. The evaluation further reveals that extended reasoning length correlates with a higher probability of errors.
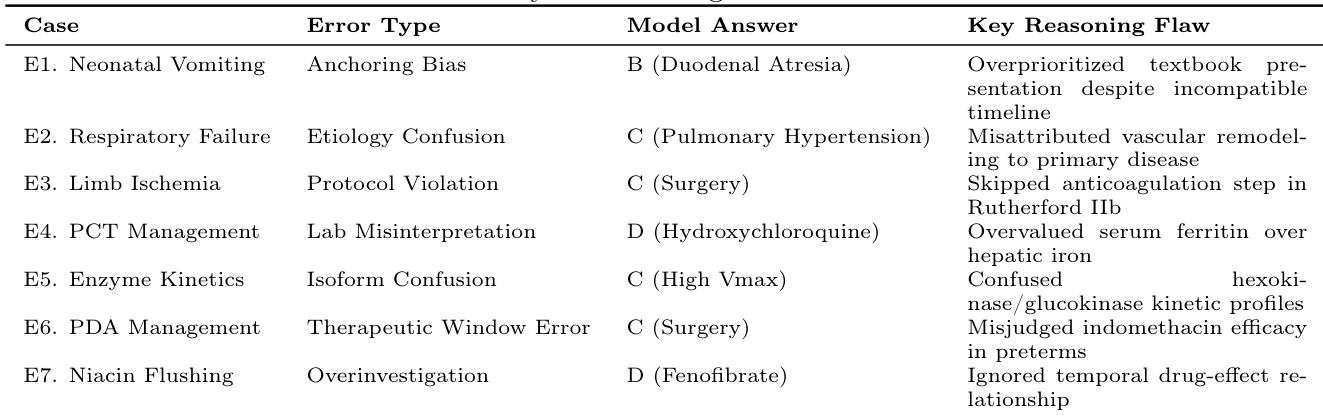
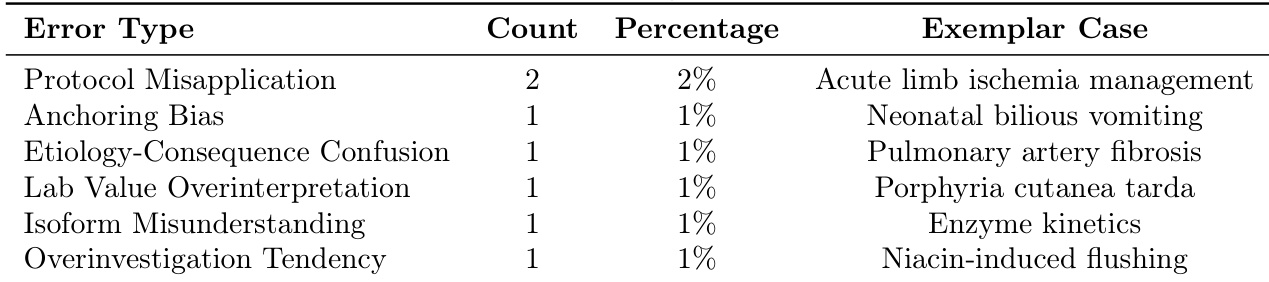
- The study identifies seven recurring clinical reasoning failure modes, including anchoring bias, difficulty integrating conflicting data, and the prioritization of definitive treatments over crucial intermediate steps. These findings delineate specific limitations in current model reasoning and highlight targeted areas for improvement in medical LLM applications.
Introduction
The accelerating deployment of large language models in healthcare aims to mitigate diagnostic errors and support strained clinical workforces, yet safe integration requires systems that replicate the nuanced cognitive processes of expert practitioners. Previous models typically operate as black boxes that prioritize factual recall over transparent, multi-step inference, leaving clinicians unable to verify reasoning pathways or identify dangerous cognitive biases. The authors leverage the open-source DeepSeek R1 architecture to audit its explicit chain-of-thought outputs against established clinical reasoning frameworks. By evaluating how the model navigates dual-process cognition and isolates specific error patterns, they introduce a fidelity-focused assessment methodology that shifts evaluation beyond answer accuracy and establishes a foundation for clinically aligned AI development.
Dataset
-
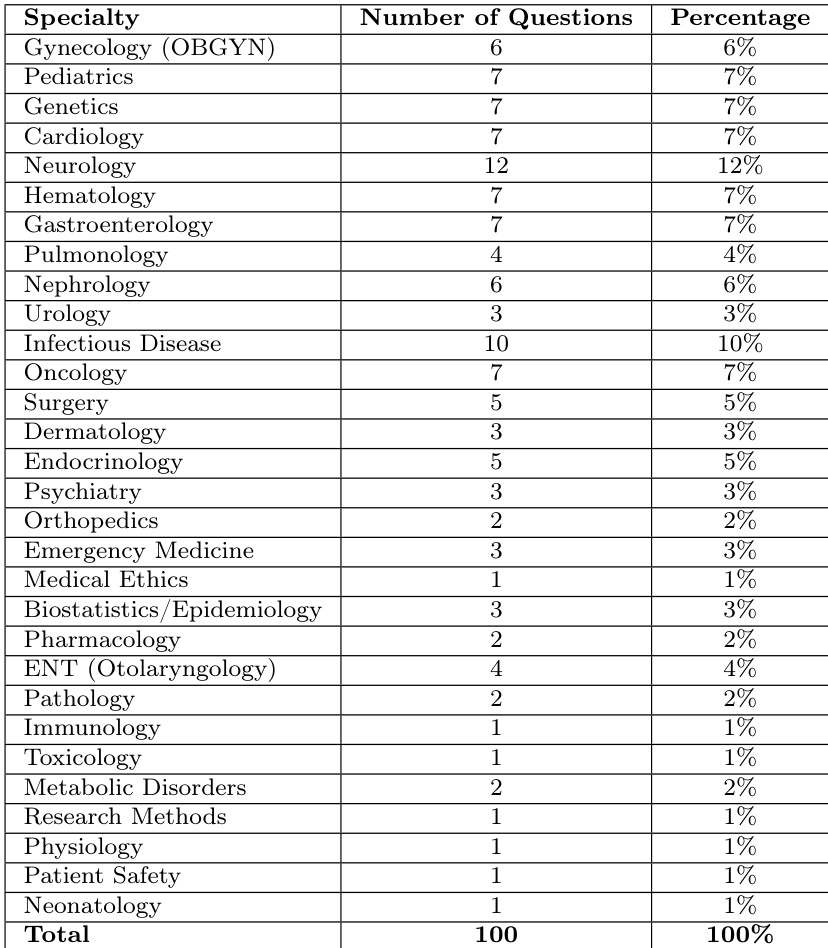
Dataset Composition and Sources: The authors evaluate their model using a curated subset of 100 questions drawn from the MedQA benchmark. MedQA is a rigorously validated collection derived from professional medical licensing examinations across multiple countries and formatted according to United States Medical Licensing Examination standards.
-
Subset Details: The evaluation corpus consists of a single subset containing 100 multiple-choice questions. Questions were randomly sampled to guarantee broad coverage across various medical specialties. Each item presents a clinical vignette that tests diagnostic reasoning, including patient history interpretation, diagnostic test selection, therapeutic guideline application, and pathophysiology integration. Answers are structured as single-letter choices.
-
Usage and Processing: Rather than using the data for training or mixture blending, the authors deploy it exclusively as a held-out evaluation benchmark. The model processes each question using a standardized system prompt that instructs it to carefully analyze the clinical scenario, apply relevant medical knowledge and logical reasoning, and output only the selected letter.
-
Evaluation and Error Analysis Pipeline: Post-generation, the outputs undergo a structured three-step classification protocol. First, the model's final answer is compared against the official MedQA reference for ground truth alignment. Second, the reasoning chain is decomposed into specific diagnostic and treatment decision points, then mapped to a clinical reasoning taxonomy. Finally, a clinician reviews all identified errors to validate them against established medical reasoning best practices.
Method
The authors leverage a structured reasoning framework inspired by the hypothetico-deductive model commonly employed in clinical medicine to guide the model’s diagnostic and treatment decision-making process. This approach begins with information gathering, where patient demographics, symptoms, vital signs, and physical exam findings are systematically synthesized. The model then represents the clinical problem in a concise, hypothesis-driven format—such as “pregnant woman with dysuria, no systemic signs, likely cystitis”—enabling focused differential diagnosis. The differential is prioritized based on clinical likelihood, with conditions such as pyelonephritis being ruled out due to absence of key signs like costovertebral angle tenderness.
Following differential prioritization, the model evaluates treatment options through a rigorous process of elimination and comparison. For each candidate intervention, the model assesses efficacy, resistance patterns, and safety profiles, particularly in context-specific scenarios such as pregnancy. For example, in the case of a pregnant patient with uncomplicated cystitis, the model rules out ampicillin due to resistance, ceftriaxone for being overly broad, and doxycycline for contraindication during pregnancy. This critical appraisal leads to the selection of nitrofurantoin as the optimal choice, supported by its proven efficacy and safety in the second trimester.
The model’s reasoning is grounded in guideline-based decision-making, incorporating evidence from clinical practice standards to ensure alignment with best practices. This integration of safety, efficacy, and guideline adherence allows the model to produce clinically sound recommendations. The structured workflow ensures that each step—from data synthesis to final decision—is logically connected and transparent, enabling both consistency and interpretability in medical reasoning.
[[IMG:]]
Experiment
This study evaluated DeepSeek R1 on a curated set of clinical cases to validate its capacity for expert-like medical reasoning and diagnostic alignment with human professionals. Qualitative analysis demonstrated that the model consistently applies structured clinical judgment and systematically evaluates patient data, closely mirroring established medical thought processes. However, error investigations revealed recurring cognitive biases, gaps in pathway understanding, and a strong association between extended reasoning traces and incorrect conclusions. Ultimately, the findings confirm that the model offers significant potential for augmenting clinical decision-making, provided that reasoning length and cognitive alignment are carefully monitored for safe integration.
{"summary": "The authors evaluated the medical reasoning capabilities of DeepSeek R1 using 100 clinical cases from the MedQA dataset, achieving high diagnostic accuracy. The analysis revealed recurring reasoning errors such as anchoring bias, incomplete consideration of alternative diagnoses, and misattribution of symptoms, with longer reasoning responses being associated with incorrect answers.", "highlights": ["The model achieved high diagnostic accuracy with 93% on 100 clinical cases from diverse medical specialties.", "Recurring reasoning errors included anchoring bias, misattribution of symptoms, and skipping crucial diagnostic steps.", "Longer reasoning responses were significantly associated with incorrect answers, suggesting a potential indicator of unreliability."]
The authors analyze the medical reasoning capabilities of DeepSeek R1 using 100 clinical cases from the MedQA dataset, achieving high diagnostic accuracy while identifying recurring reasoning errors. The model demonstrates sound clinical reasoning in correct cases but exhibits specific cognitive flaws in erroneous ones, with longer reasoning lengths associated with incorrect answers. The findings suggest that reasoning length could serve as a practical indicator of reliability in clinical applications. The model shows high diagnostic accuracy but exhibits recurring cognitive biases and reasoning flaws in error cases. Longer reasoning responses are significantly associated with incorrect answers, suggesting a potential indicator of unreliability. The model's reasoning patterns reflect clinical decision-making processes, including differential diagnosis and treatment selection, despite specific errors in pathway understanding.
{"summary": "The authors analyze the medical reasoning capabilities of DeepSeek R1, achieving high diagnostic accuracy while identifying recurring patterns of reasoning errors in a subset of cases. The analysis reveals that longer reasoning responses are associated with a higher likelihood of errors, suggesting that response length may serve as an indicator of model uncertainty.", "highlights": ["The model exhibits high diagnostic accuracy but shows recurring reasoning errors such as anchoring bias and protocol misapplication.", "Longer reasoning responses are statistically linked to incorrect answers, indicating potential uncertainty in extended explanations.", "The model's reasoning demonstrates medical logic in both correct and incorrect cases, highlighting its ability to perform structured clinical reasoning."]
The authors evaluated the medical reasoning capabilities of DeepSeek R1 by analyzing its diagnostic responses to 100 clinical cases from the MedQA dataset. The assessment reveals that while the model demonstrates strong diagnostic accuracy and structured clinical logic, it frequently exhibits cognitive biases such as anchoring and symptom misattribution when errors occur. Extended reasoning chains were consistently linked to incorrect answers, indicating that verbose explanations may reflect underlying uncertainty rather than analytical thoroughness. These qualitative patterns suggest that reasoning length could serve as a practical indicator of reliability when deploying the model in clinical decision-making contexts.