Command Palette
Search for a command to run...
ReaderLM-v2: نموذج لغوي صغير لتحويل HTML إلى Markdown و JSON
ReaderLM-v2: نموذج لغوي صغير لتحويل HTML إلى Markdown و JSON
Feng Wang Zesheng Shi Bo Wang Nan Wang Han Xiao
نشر Reader-LM بنقرة واحدة: تحويل سريع من HTML إلى Markdown
الملخص
نقدم ReaderLM-v2، وهو نموذج لغوي مضغوط يتكون من 1.5 مليار معلمة، صُمم لاستخراج محتوى الويب بكفاءة. يعالج نموذجنا المستندات التي تصل إلى 512 ألف token، محوّلاً أكواد HTML غير المنتظمة إلى تنسيقات Markdown أو JSON نظيفة ودقيقة للغاية، مما يجعله أداة مثالية لتأسيس النماذج اللغوية الكبيرة (grounding). تنبع فعالية النموذج من ابتكارين رئيسيين: (1) خط إنتاج لتوليد البيانات يتكون من ثلاث مراحل، يولّد بيانات تدريب عالية الجودة ومتنوعة من خلال المسودة التكرارية، والتحسين، ومراجعة محتوى استخراج الويب؛ و(2) إطار تدريب موحد يجمع بين التدريب المسبق المستمر والتحسين متعدد الأهداف. تُظهر التقييمات المكثفة أن ReaderLM-v2 يتفوق على GPT-4o-2024-08-06 والنماذج الأكبر حجماً بنسبة تتراوح بين 15-20% على معايير تقييم مُنتقاة بعناية، مع تفوق ملحوظ في معالجة المستندات التي تتجاوز 100 ألف token، مع الحفاظ على متطلبات حسابية أقل بكثير.
One-sentence Summary
ReaderLM-v2 is a 1.5 billion parameter language model that efficiently converts HTML into Markdown or JSON for grounding large language models, leveraging a three-stage data synthesis pipeline and a unified training framework combining continuous pre-training with multi-objective optimization to process up to 512K tokens while outperforming GPT-4o-2024-08-06 and larger models by 15 to 20 percent on curated benchmarks, particularly on documents exceeding 100K tokens, with substantially lower computational requirements.
Key Contributions
- ReaderLM-v2 is a 1.5 billion parameter language model engineered to process documents up to 512,000 tokens and convert unstructured HTML into clean Markdown or JSON formats. This architecture delivers a computationally efficient solution for grounding large language models in web content.
- The method implements a three-stage data synthesis pipeline that iteratively drafts, refines, and critiques web content to produce high-quality training samples. These samples optimize a unified framework that combines continuous pre-training with multi-objective optimization for instructed Markdown extraction and schema-guided JSON mapping.
- Benchmark evaluations demonstrate that ReaderLM-v2 surpasses GPT-4o-2024-08-06 and larger models by 15-20% on curated benchmarks, with superior accuracy on documents exceeding 100,000 tokens. This performance is achieved while maintaining significantly lower computational overhead.
Introduction
The authors address the growing demand for structured content extraction, a critical capability that converts messy HTML into clean JSON or Markdown formats to power downstream applications like knowledge retrieval and automation. Prior LLM-based approaches struggle with hallucination, inference bottlenecks, and limited context handling, while their heavy computational requirements and misalignment with HTML structuring tasks make them impractical for scalable deployment. To overcome these barriers, the authors develop ReaderLM-v2, a 1.5 billion parameter fine-tuned small language model that matches or exceeds larger proprietary models in extraction accuracy. They achieve this through a novel Draft-Refine-Critique data synthesis pipeline and a multi-phase training strategy that extends context windows to 512k tokens, ultimately delivering a resource-efficient, open-source solution for long-document content structuring.
Dataset
-
Dataset composition and sources: The authors build the training corpus from two primary sources: a curated real-world collection and synthetically generated data. The foundation is WebMarkdown-1M, comprising one million web pages randomly sampled from the top 500 domains in the Common Crawl URL Index. Because no existing public datasets cover the specific HTML-to-Markdown and schema-guided HTML-to-JSON tasks, the authors supplement this with synthetic examples produced through a multi-step generation pipeline.
-
Key details for each subset:
- WebMarkdown-1M is converted into Markdown and JSON using Jina Reader. The authors apply language detection to exclude documents outside Qwen2.5’s 29 supported languages, leaving a corpus dominated by English (62.7%) and Chinese (20%) with an average length of 56,000 tokens.
- WebData-SFT-Filtered contains 250,000 high-quality instruction pairs that successfully pass the final quality review.
- WebData-SFT-Critique holds 100,000 training examples pairing each input with a critique assessment and explanation, maintaining a strict 1:2 ratio of negative to positive evaluations.
- WebData-DPO-Preference comprises 150,000 preference triplets linking each HTML input to a validated desired output and an initial draft undesired output.
- The evaluation set is a held-out collection of 500 HTML-to-Markdown and 300 HTML-to-JSON documents, explicitly excluded from all training phases.
-
How the paper uses the data: The synthetic subsets drive the Stage 2, Stage 3, and Stage 4 tuning phases. The authors process all raw HTML through a Draft-Refine-Critique pipeline where the draft step generates format-aligned samples, the refine step removes redundancy and enforces structural consistency via LLM review, and the critique step applies prompt-based binary judgments with explanatory feedback. Training splits are strictly separated, with the evaluation set reserved exclusively for final validation. The authors maintain specific mixture ratios, such as the 1:2 negative-to-positive balance in the critique dataset, to optimize both instruction tuning and direct preference optimization.
-
Processing details and metadata construction: The authors construct dataset metadata by tracking language distributions, token length statistics, and binary critique outcomes to categorize and balance the subsets. Rather than cropping documents, they retain the full average length of 56,000 tokens to train the model for robust long-context structured extraction. The evaluation set undergoes rigorous verification protocols, including manual mapping of HTML tags to Markdown syntax, confirmation of content preservation, and automated grammar checking combined with manual spot-checks to validate JSON structure and prevent hallucination.
Method
The authors leverage a multi-stage training pipeline designed to iteratively improve the performance of ReaderLM-v2, a 1.5 billion parameter language model for web content extraction. The overall framework integrates both a three-stage data synthesis process and a comprehensive training strategy, with each stage building upon the previous to enhance model accuracy and robustness.
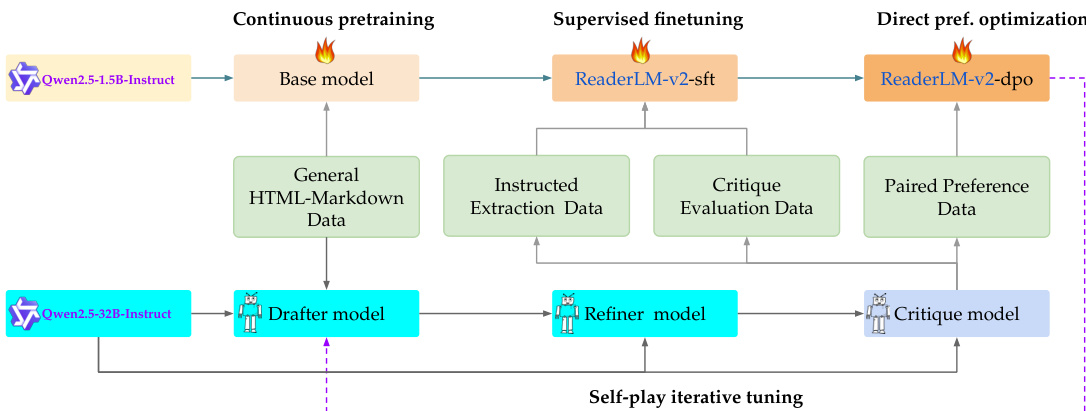
Refer to the framework diagram to understand the training process. The pipeline begins with a base model, Qwen2.5-1.5B-Instruct, which undergoes continuous pretraining. During this initial phase, the model is trained on HTML-to-Markdown conversion data to extend its context length. This stage employs a progressive strategy, expanding the context length through three phases—32,768, 125,000, and ultimately 256,000 tokens—using ring-zag attention and a RoPE base frequency of 5,000,000. The training data is curated to maintain a 40% proportion of sequences at the current maximum length and 60% shorter sequences, ensuring stable adaptation to longer inputs. The model's ability to extrapolate enables inference on sequences up to 512,000 tokens despite being trained on 256,000 tokens.
Following continuous pretraining, the model proceeds to supervised fine-tuning (SFT). This stage utilizes synthetic data generated via the DRAFT-REFINE-CRITIQUE pipeline. The training is conducted on four specialized checkpoints, each focused on specific data types—HTML-to-Markdown and HTML-to-JSON tasks—using datasets such as WebData-SFT-Filtered and WebData-SFT-Critique. To mitigate repetitive token generation, contrastive loss is incorporated during training. After fine-tuning, the specialized checkpoints are combined into a unified model using linear parameter merging with weighted interpolation.
The next phase involves direct preference optimization (DPO), which uses paired preference data to refine the model's ability to distinguish between high- and low-quality outputs. This stage leverages the same synthetic data pipeline to generate preference pairs, enabling the model to learn from comparative feedback.
Finally, the model undergoes self-play iterative tuning, an additional training stage that mirrors the prior SFT and DPO steps. In this process, the model uses its own checkpoint from the previous stage to generate new draft data, which is then refined and critiqued to produce updated training datasets. This creates a feedback loop where the model autonomously generates improved training data and refines its own performance through successive iterations.
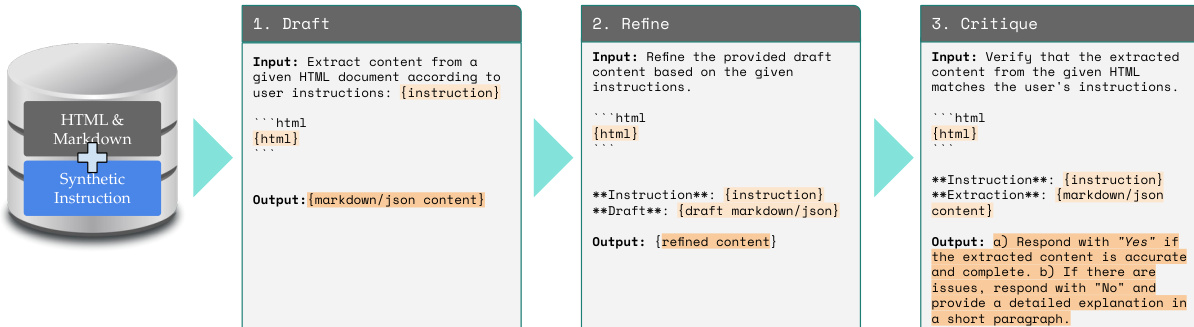
As shown in the figure below, the DRAFT-REFINE-CRITIQUE pipeline operates in three distinct stages. In the first stage, a drafter model takes an HTML document and a user instruction as input and generates an initial extraction. The second stage involves a refiner model, which takes the draft output and the original instruction to produce a refined version of the content. The third stage employs a critique model that evaluates the extracted content against the user's instructions, verifying its accuracy and completeness. If issues are identified, the critique model provides a detailed explanation in a short paragraph. This iterative process ensures the generation of high-quality, diverse training data that enhances the model's performance on complex extraction tasks.
Experiment
The evaluation converts predicted and ground truth JSON outputs into tree structures to systematically validate structural accuracy, completeness, and strict adherence to the target schema. Qualitatively, extraction performance remains stable across training stages, demonstrating that initial supervised fine-tuning effectively internalizes JSON formatting while preference optimization primarily improves output reliability. Despite its compact size, the model delivers solid results for structured data extraction, though it continues to trail larger architectures in handling this complex task.
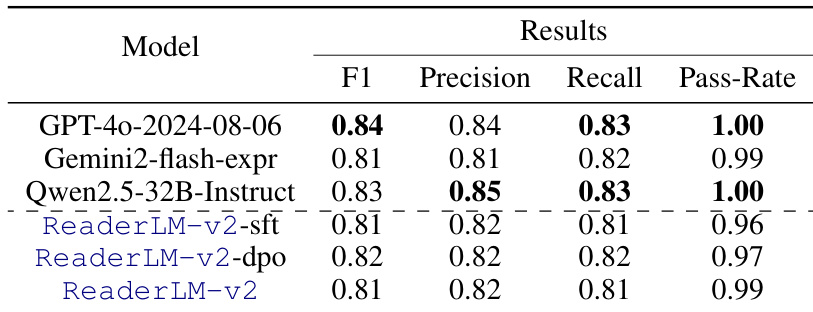
The authors evaluate JSON extraction performance using metrics such as F1, precision, recall, and pass rate, comparing multiple models. Results indicate that smaller models like ReaderLM-v2 achieve competitive performance, with stable results across training stages and notable pass rates, though larger models generally outperform them. ReaderLM-v2 achieves solid performance on structured JSON extraction despite having fewer parameters. Pass rates are high across all models, indicating strong syntactic and structural adherence in outputs. Performance remains relatively stable across different training stages, suggesting effective capture of JSON structure during initial fine-tuning.
The authors evaluate JSON extraction performance using multiple models across different tasks and datasets, focusing on structural accuracy and syntactic validity. Results show that ReaderLM-v2 achieves strong performance, particularly in content extraction, and maintains stable results across training stages, indicating effective capture of structured data patterns. ReaderLM-v2 demonstrates high performance in content extraction, outperforming other models in key metrics. The model maintains consistent performance across training stages, suggesting effective learning of structured data extraction. ReaderLM-v2 achieves strong results in instructed extraction, though with lower values compared to content extraction.
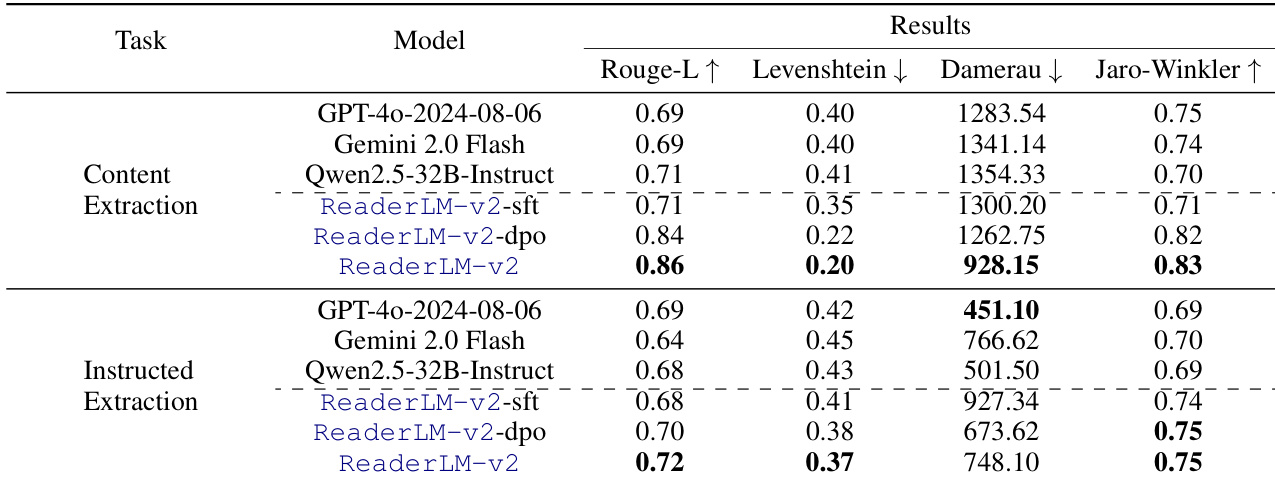
The experiments evaluate JSON extraction capabilities across multiple models and tasks, validating structural accuracy and syntactic adherence. Results demonstrate that smaller architectures like ReaderLM-v2 achieve highly competitive performance, particularly in content extraction, while maintaining consistent results across different training stages. Although larger models generally outperform them, the smaller variant effectively captures structured data patterns early in training, indicating that efficient parameter utilization and targeted fine-tuning are sufficient for robust extraction.