Command Palette
Search for a command to run...
التنبؤ بالسلاسل الزمنية الاحتمالية متعددة المتغيرات باستخدام إنفورمر
الملخص
Please provide the title and abstract you would like me to translate.
One-sentence Summary
Trained within a Bayesian framework, the proposed TweedieGP model couples Gaussian process latent functions with a fully parameterized Tweedie likelihood to probabilistically forecast intermittent time series, accurately capturing a point mass at zero and heavy tails without simplifying assumptions and consistently outperforming negative binomial baselines across thousands of count series, particularly in high quantile estimation.
Key Contributions
- The framework employs Gaussian Processes as latent functions within a Bayesian forecasting setup for intermittent time series, coupling the latent variable with a negative binomial distribution to propagate parameter uncertainty directly into the forecast distribution.
- The study introduces TweedieGP, the first probabilistic model for intermittent demand to utilize a fully parameterized Tweedie distribution, which accurately represents a point mass at zero and heavy tails without relying on the unimodal restrictions of prior approaches.
- Evaluations across approximately 40,000 supply chain time series demonstrate that both Gaussian Process-based models consistently outperform existing competitors, with the Tweedie variant yielding the most accurate estimates for the highest quantiles due to its bimodal structure.
Introduction
Intermittent time series forecasting is essential for supply chain inventory management, where accurate probability distributions are required to compute critical quantiles and optimize stock levels. Prior probabilistic models typically rely on unobserved latent processes to track demand parameters over time, yet they generally ignore the uncertainty surrounding these variables. This oversight, combined with the use of standard distributions that cannot capture zero mass or heavy right tails, limits forecast reliability. The authors leverage Gaussian Processes to explicitly quantify and propagate latent variable uncertainty into the prediction distribution. They introduce two new frameworks, Neg-BinGP and TweedieGP, with the latter representing the first fully parameterized Tweedie distribution model for intermittent series. By pairing Gaussian Processes with a bimodal Tweedie likelihood, they deliver more accurate probabilistic forecasts, particularly at high quantiles, while maintaining training efficiency comparable to established local models.
Dataset

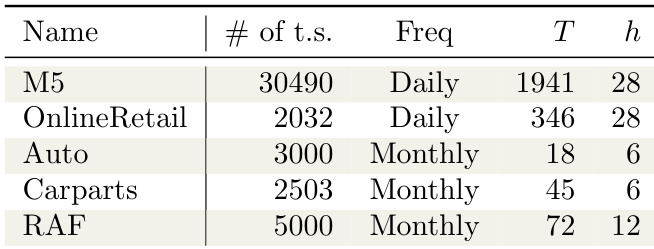
The authors evaluate their forecasting models across five publicly available intermittent time series datasets, totaling over 40,000 series. They define a series as intermittent when the average demand interval exceeds 1, ensuring each contains at least one zero observation. The dataset composition, subset details, and processing workflow are outlined below:
- M5: Daily Walmart sales data sourced from a major forecasting competition. Contains 30,490 series, features the longest training length (T = 1,941), and exhibits the most heterogeneous zero proportions with narrow demand sizes.
- OnlineRetail: Daily sales records from a British online retailer. The authors aggregate daily sales per item and apply a filtering rule to retain only series with at least one positive demand within the first 200 days. These series are approximately five times longer than the RAF dataset.
- Auto: Short monthly time series for automobile parts. It shows the lowest proportion of zeros and the shortest training length (T = 18).
- Carparts: Longer monthly time series for automotive spare parts, classified as strongly intermittent.
- RAF: Monthly time series for British Royal Air Force aircraft spare parts, characterized by a high proportion of zeros and shorter series than OnlineRetail.
- Usage & Splits: The authors use these datasets to benchmark model performance across varying intermittency levels. They track the training length (T) and forecast horizon (h) for each dataset split to evaluate forecasting accuracy without specifying mixture ratios, treating each series as an independent evaluation unit.
- Processing & Metadata: Demand size distributions are visualized and analyzed using a base-10 logarithmic scale. The authors monitor zero proportions to quantify dataset heterogeneity and apply the ADI > 1 threshold to standardize the intermittent series definition across all subsets.
Method
The authors leverage Gaussian Processes (GPs) as a non-parametric Bayesian framework to model the latent function governing intermittent time series forecasting. The core of the approach is to define a prior distribution over functions f:R+→R, which represents the latent variable influencing the mean of the forecast distribution. This prior is specified as a GP with a mean function m(⋅) and a positive definite kernel k(⋅,⋅), where the mean is set to a constant learnable parameter c and the kernel is a Radial Basis Function (RBF) that encodes smoothness assumptions over time. The RBF kernel is defined as k(ti,tj)=σ2exp(−2ℓ2∣ti−tj∣2), with learnable hyper-parameters σ2 (outputscale) and ℓ (lengthscale) that control the range and temporal variation of the latent function. The prior distribution over the latent function values at the observed time points, f1:T, is a multivariate Gaussian, N(m1:T,KT,T), where the mean vector m1:T is (c,…,c)⊤ and KT,T is the covariance matrix constructed from the kernel evaluations.
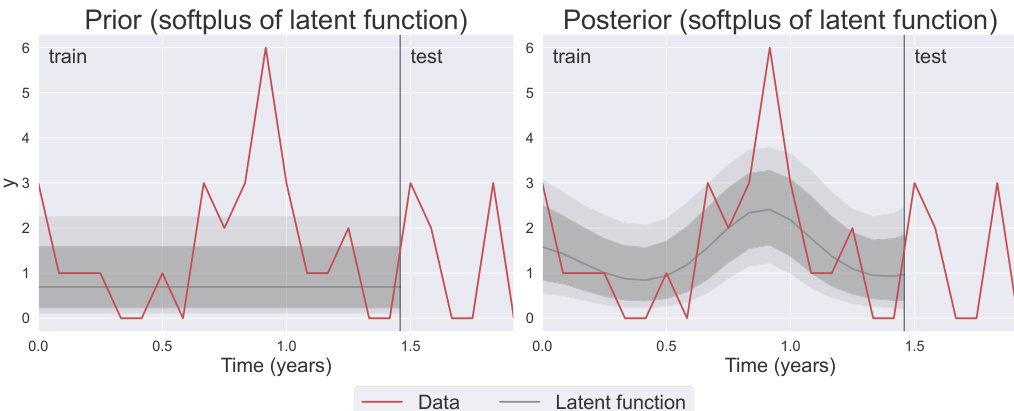
The latent function f is transformed via the softplus function, softplus(x)=log(1+ex), to ensure positivity, as the likelihoods require a positive mean parameter. This transformation results in a non-negative latent process with asymmetric credible intervals. The model couples this latent GP variable with a probabilistic forecast distribution to generate predictions. The likelihood function is conditioned on the transformed latent function, plik(yi∣softplus(fi),θlik), where fi=f(ti) and θlik are hyper-parameters. Two distinct likelihoods are considered: the negative binomial (NegBinGP) and the Tweedie (TweedieGP). For the negative binomial, the number of successes r is modeled as r=softplus(f), while the success probability p is a learnable hyper-parameter. For the Tweedie, the mean μ is set to softplus(f), and the dispersion parameter ϕ and power parameter ρ are optimized hyper-parameters.
After observing the training data y1:T, the posterior distribution over the latent function, p(f1:T∣y1:T), is obtained via Bayes' theorem. Since the likelihoods are non-Gaussian, the exact posterior is intractable, and the authors employ a variational inducing point approximation to approximate it with a Gaussian density q(f1:T∣y1:T). This approximation allows for tractable optimization of the model parameters. The forecast distribution for future time points yT+1:T+h is derived by marginalizing the posterior over the latent function, p(fT+1:T+h∣y1:T), and then sampling from this distribution and passing the samples through the likelihood function. This process propagates the uncertainty in the latent function into the final forecast distribution, enabling the generation of probabilistic forecasts without requiring autoregressive sampling. The framework allows for direct inference of the latent process and its uncertainty, providing a principled way to model intermittent time series with complex distributions.
Experiment
The evaluation framework assesses the proposed NegBinGP and TweedieGP models against established local forecasting baselines using scale-independent scoring rules tailored for intermittent demand. Baseline comparisons validate that the proposed methods effectively handle sparse time series, while ablation studies demonstrate that median-based scaling is critical for numerical stability and that the full Tweedie likelihood significantly outperforms simplified approximations by preserving heavier tails for reliable high-quantile predictions. Collectively, these results confirm that properly scaled Gaussian process models offer a robust solution for intermittent forecasting challenges.
The authors compare the performance of NegBinGP and TweedieGP against several baselines using multiple metrics, including scaled quantile loss, scaled RPS, and RMSSE. Results show that TweedieGP achieves competitive performance across different datasets, with lower error values compared to other methods in most cases. The ablation study indicates that scaling the data improves performance and that the full Tweedie likelihood outperforms simplified versions. TweedieGP achieves lower error values compared to other models across multiple datasets. NegBinGP shows higher error values compared to TweedieGP and other baselines in most cases. Scaling the data improves the performance of TweedieGP, as indicated by the ablation study.
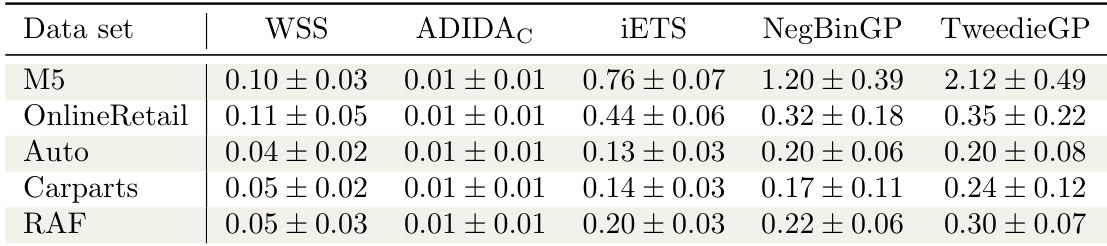
The authors compare the performance of their proposed models, NegBinGP and TweedieGP, against several baselines using multiple metrics across different datasets. Results show that TweedieGP generally achieves competitive or superior performance compared to other methods, particularly in terms of scaled quantile loss and ranked probability score, while NegBinGP performs well in specific scenarios. The ablation study indicates that scaling and the choice of likelihood approximation significantly affect model accuracy, with unscaled data leading to degraded performance. TweedieGP achieves competitive or better performance than baselines across most metrics and datasets. NegBinGP performs well in certain cases, particularly on the M5 dataset where it outperforms other models in some metrics. The ablation study shows that scaling the data improves model performance and that the choice of likelihood approximation impacts higher quantile estimation.
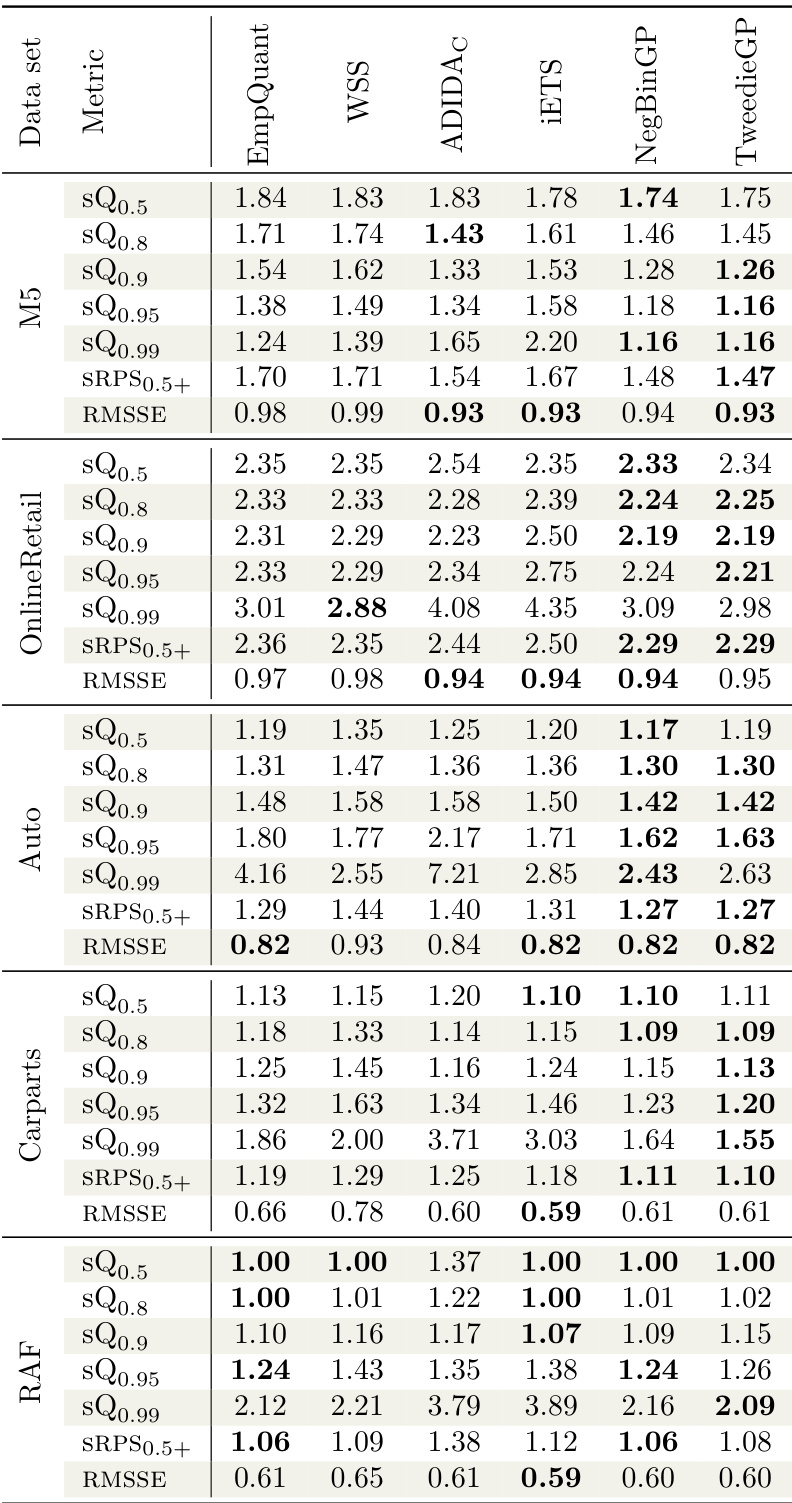
The authors compare the performance of their proposed models, NegBinGP and TweedieGP, against several baselines using multiple metrics across different datasets. Results show that TweedieGP consistently achieves competitive or superior performance in terms of scaled quantile loss and ranked probability score, particularly on high quantiles, while NegBinGP performs well on certain metrics like RMSSE. The ablation study confirms that data scaling and the full Tweedie likelihood are important for optimal performance. TweedieGP achieves the best or near-best performance on most metrics, especially for high quantiles and ranked probability scores. NegBinGP shows strong performance on RMSSE and some quantile loss metrics, particularly on the M5 and OnlineRetail datasets. The ablation study indicates that data scaling and the full Tweedie likelihood are crucial for accurate high-quantile estimation and overall model performance.
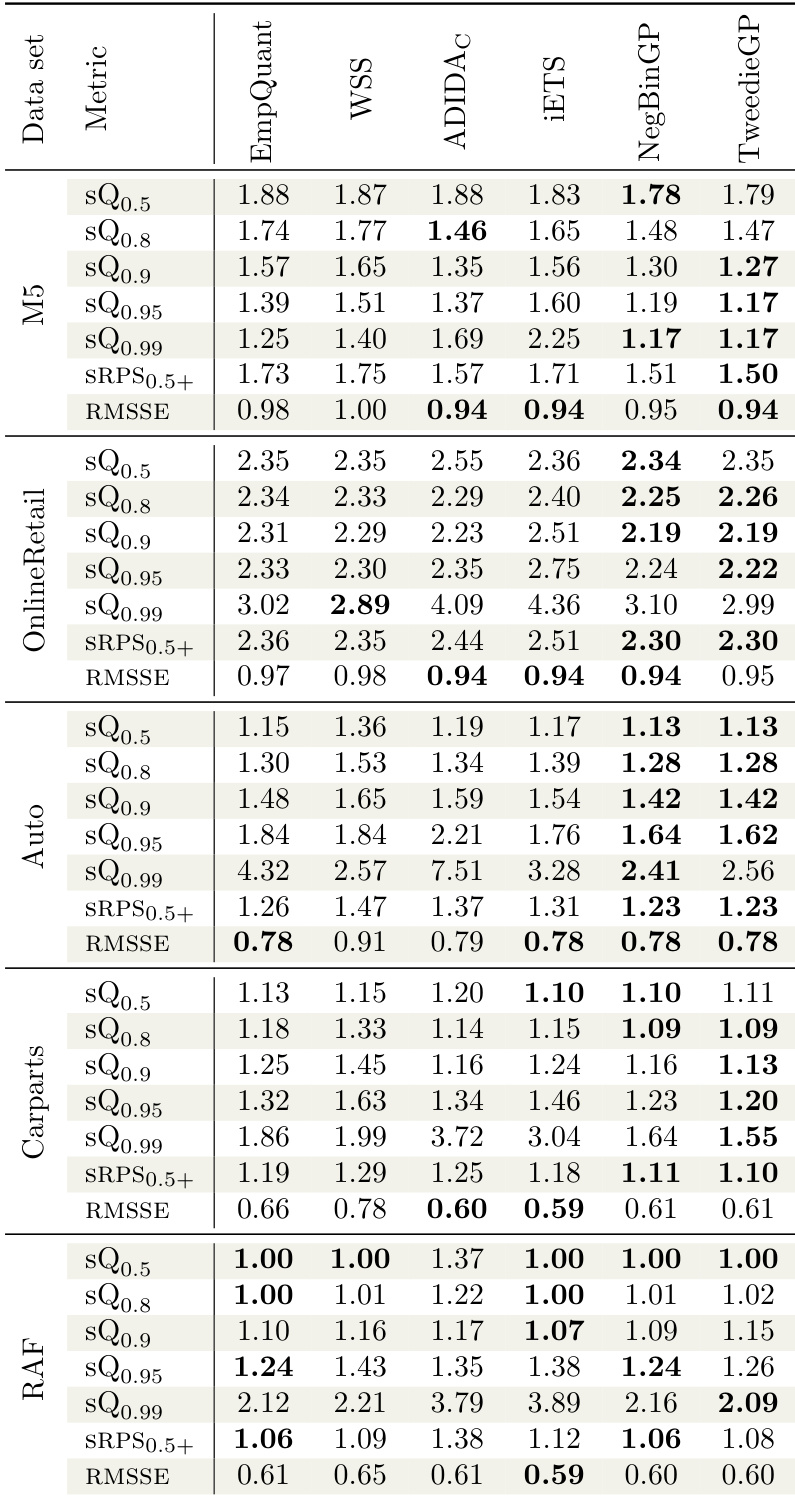
The authors conduct experiments on multiple time series datasets with varying frequencies and lengths, comparing their proposed models against several baselines using a range of metrics including scaled quantile loss, ranked probability score, and root mean squared scaled error. Results show that the performance of the models depends on data scaling and the choice of likelihood, with unscaled data leading to numerical issues and approximated likelihoods affecting higher quantile estimates. The experiment involves multiple time series with different frequencies and lengths, including daily and monthly data. The authors compare their models against baselines using scaled quantile loss, ranked probability score, and root mean squared scaled error. Scaling the data improves model performance, and the choice of likelihood affects the estimation of higher quantiles.
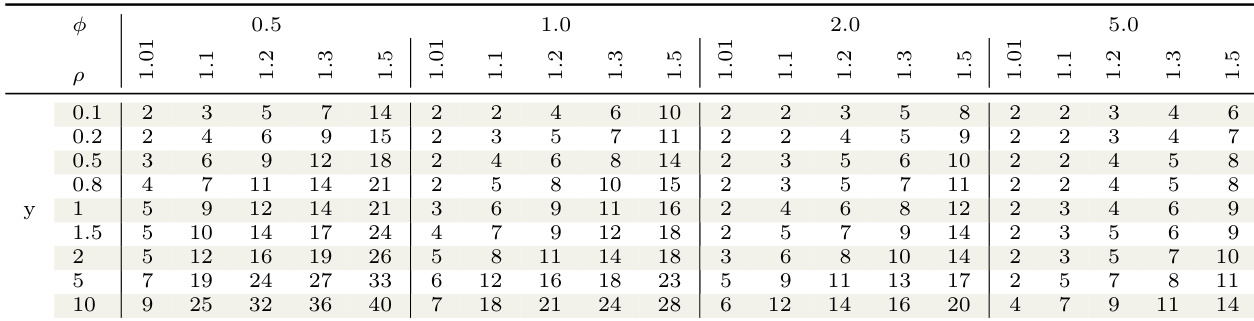
The authors conduct an ablation study to evaluate the impact of data scaling and likelihood approximation on the performance of a Gaussian process model for intermittent time series. The results show that scaling the data improves performance, while using an approximated likelihood leads to poorer estimates of higher quantiles. The study compares different configurations of the model under varying parameter settings. Scaling the data improves the performance of the Gaussian process model. An approximated likelihood leads to poorer estimates of higher quantiles. The model's performance varies across different parameter configurations, indicating sensitivity to these settings.
The authors evaluate their proposed NegBinGP and TweedieGP models against multiple baselines across diverse time series datasets to assess their overall forecasting capabilities. The primary comparison validates that TweedieGP consistently delivers robust performance across most scenarios, particularly for high quantiles, while NegBinGP demonstrates targeted strengths on specific datasets. A subsequent ablation study validates that proper data scaling is essential for numerical stability and that utilizing the full likelihood function significantly improves tail estimation compared to simplified approximations. Collectively, these experiments establish that likelihood specification and data preprocessing are critical determinants of model efficacy, positioning TweedieGP as the more reliable general-purpose solution.