Command Palette
Search for a command to run...
Speech-FT: دمج نماذج تمثيل الكلام المُدرَّبة مسبقاً والمُعدَّلة للتخصيص من أجل التعميم عبر المهام
Speech-FT: دمج نماذج تمثيل الكلام المُدرَّبة مسبقاً والمُعدَّلة للتخصيص من أجل التعميم عبر المهام
Tzu-Quan Lin Wei-Ping Huang Hao Tang Hung-yi Lee
نشر نموذج TTS من نوع إنتاجي بدرجة عالية بضغطة واحدة: Step-Audio-TTS-3B
الملخص
العنوان: (فارغ)
الملخص: يمكن أن يؤدي ضبط نماذج تمثيل الكلام بشكل دقيق (Fine-tuning) إلى تحسين الأداء في مهام محددة، لكنه غالباً ما يضر بقدرتها على التعميم عبر المهام المختلفة. ينتج هذا التدهور عادةً عن التغيرات المفرطة في التمثيلات، مما يجعل من الصعب الاحتفاظ بالمعلومات التي تم تعلمها أثناء مرحلة التدريب المسبق. قد تفشل النهج الحالية، مثل تنظيم التغيرات في الأوزان أثناء الضبط الدقيق، في الحفاظ على تشابه كافٍ للسمات مع النموذج المدرب مسبقاً، وبالتالي قد تفقد قدرتها على التعميم عبر المهام. لمعالجة هذه المشكلة، نقترح Speech-FT، وهو إطار عمل جديد للضبط الدقيق يتكون من مرحلتين، مصمم للحفاظ على التعميم عبر المهام مع الاستفادة من مزايا الضبط الدقيق. يطبق Speech-FT أولاً ضبطاً دقيقاً مصمماً خصيصاً لتقليل الانحراف التمثيلي، يليه استيفاء في فضاء الأوزان مع النموذج المدرب مسبقاً لاستعادة التعميم عبر المهام. تُظهر التجارب المكثفة على نماذج HuBERT وwav2vec 2.0 وDeCoAR 2.0 وWavLM Base+ أن Speech-FT يحسن الأداء بشكل متسق عبر مجموعة واسعة من سيناريوهات الضبط الدقيق الخاضع للإشراف، وغير الخاضع للإشراف، ومتعدد المهام. علاوة على ذلك، يحقق Speech-FT تعميماً متفوقاً عبر المهام مقارنة بأساسيات الضبط الدقيق التي تقيد التغيرات في الأوزان صراحةً، مثل التنظيم في فضاء الأوزان والضبط الدقيق باستخدام LoRA. يكشف تحليلنا أن Speech-FT يحافظ على تشابه أعلى للسمات مع النموذج المدرب مسبقاً مقارنة بالاستراتيجيات البديلة، على الرغم من السماح بتحديثات أكبر في فضاء الأوزان. ومن الجدير بالذكر أن Speech-FT يحقق تحسينات كبيرة على معيار SUPERB. على سبيل المثال، عند ضبط HuBERT بشكل دقيق على التعرف التلقائي على الكلام، يتمكن Speech-FT من تقليل معدل خطأ الهاتف من 5.17% إلى 3.94%، وخفض معدل خطأ الكلمة من 6.38% إلى 5.75%، وزيادة دقة تحديد المتحدث من 81.86% إلى 84.11%. يوفر Speech-FT حلاً بسيطاً وقوياً لمزيد من تحسين نماذج تمثيل الكلام بعد التدريب المسبق.
One-sentence Summary
Speech-FT is a two-stage fine-tuning framework that preserves cross-task generalization by reducing representational drift and interpolating weights with the pre-trained model, consistently outperforming weight regularization and LoRA baselines on HuBERT, wav2vec 2.0, DeCoAR 2.0, and WavLM Base+ across the SUPERB benchmark while significantly improving automatic speech recognition and speaker identification metrics.
Key Contributions
- Speech-FT is a two-stage fine-tuning framework that mitigates representational drift through an initial drift-reduction phase followed by weight-space interpolation with the pre-trained model to preserve cross-task generalization.
- Extensive evaluations on HuBERT, wav2vec 2.0, DeCoAR 2.0, and WavLM Base+ demonstrate consistent performance gains across supervised, unsupervised, and multitask scenarios, including SUPERB benchmark improvements that reduce phone error rates from 5.17% to 3.94% and increase speaker identification accuracy to 84.11%.
- Analysis demonstrates that the framework maintains higher feature similarity to pre-trained representations despite allowing larger weight updates, delivering these improvements without introducing additional computational overhead compared to standard fine-tuning.
Introduction
Pre-trained speech representation models serve as the foundation for modern speech processing, enabling robust performance across diverse applications like automatic speech recognition and speaker identification. Fine-tuning these architectures on specific targets significantly boosts task accuracy but frequently triggers representational drift that severely degrades cross-task generalization. Existing mitigation strategies, including weight-space regularization and parameter-efficient methods like LoRA, attempt to restrict parameter deviations yet often fail to preserve the high feature similarity required for broad transferability. To resolve this trade-off, the authors propose Speech-FT, a two-stage fine-tuning framework that first applies a stability-focused optimization to minimize representational drift and subsequently restores generalization through weight-space interpolation between the fine-tuned and pre-trained models. This strategy strategically permits larger parameter updates while actively maintaining feature alignment, delivering consistent performance gains across multiple speech architectures and benchmarks without introducing additional computational overhead.
Dataset
- Dataset Composition and Sources: The authors rely on the AISHELL-3 corpus, a standard Mandarin speech dataset released by Beijing Shell Shell Technology Co., Ltd., as their sole resource for unsupervised fine-tuning.
- Subset Specifications: The collection comprises approximately 63.17 hours of audio originally sampled at 44.1 kHz. The authors use the entire dataset without applying additional filtering rules or dividing it into separate training and validation splits.
- Data Processing and Target Generation: To align with the HuBERT architecture, all audio is resampled to 16 kHz. Because the original k-means target model is unavailable, the authors generate pseudo-targets by taking the argmax of HuBERT Base codeword logits, effectively turning the process into a self-training loop.
- Training Usage and Pipeline Details: The authors run continued pre-training for 100,000 steps using an effective batch size of 32 and a learning rate of 1e-5. The pipeline optimizes a simplified HuBERT loss via cross-entropy over masked time steps, which eliminates the need for a learnable codebook and ensures stable convergence. This approach adapts the model to Mandarin while preserving English capabilities, with no audio cropping or external metadata construction required.
Method
The authors present Speech-FT, a framework designed to improve the cross-task generalization of pre-trained speech representation models during fine-tuning. The overall pipeline consists of three main steps: stable fine-tuning on a target task, weight-space interpolation to merge the pre-trained and fine-tuned models, and evaluation of the merged model on the SUPERB benchmark. The framework aims to mitigate representational drift caused by fine-tuning, which can degrade the model’s ability to generalize across downstream tasks.
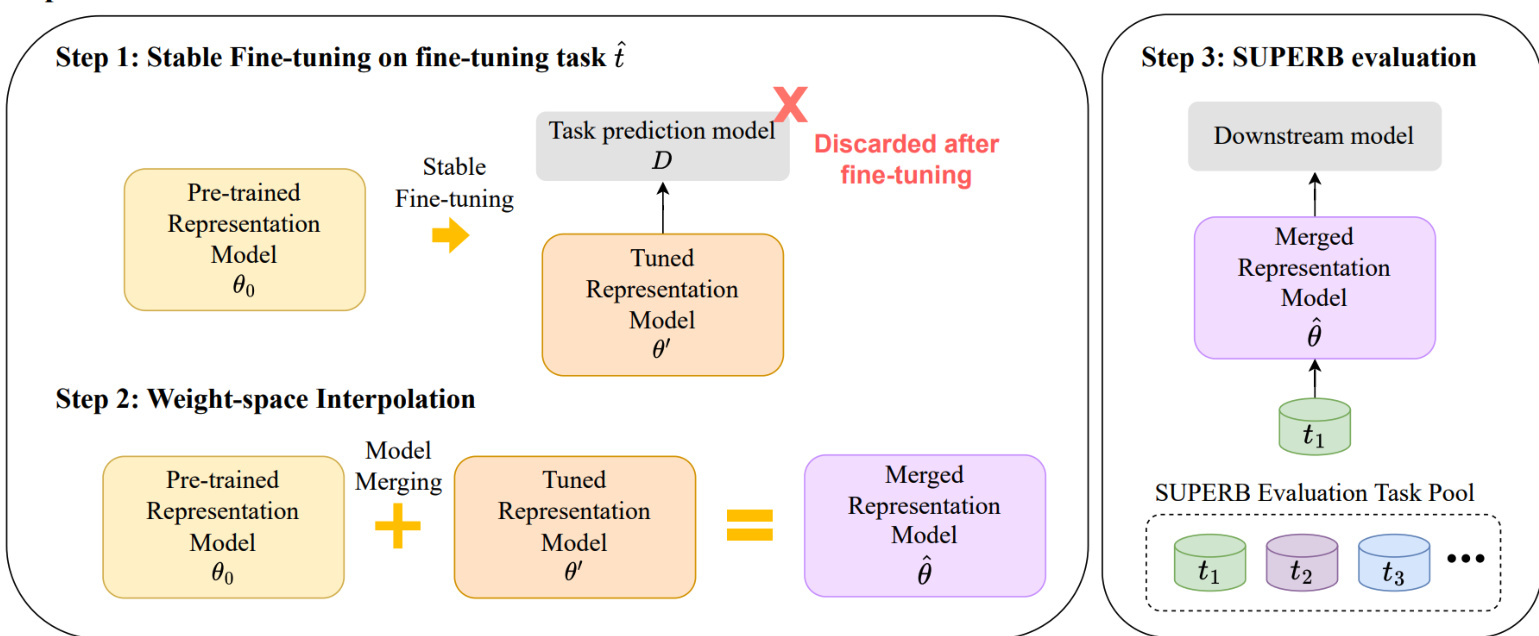
As shown in the figure below, the first step involves stable fine-tuning on a specific fine-tuning task t^. The process begins with a pre-trained representation model θ0, to which a task prediction model D is attached. During this phase, the downsampling module of the representation model is frozen to preserve low-level features critical for various applications. Fine-tuning proceeds in two stages: initially, only the task prediction model D is updated for the first β% of the total fine-tuning steps, allowing the model to adapt without immediately altering the representation weights. After this initial phase, the entire model, excluding the frozen downsampling module, is updated jointly with D for the remaining steps. This two-phase strategy stabilizes the fine-tuning process and reduces the risk of catastrophic forgetting or representational drift.
Following stable fine-tuning, the second step applies weight-space interpolation to combine the pre-trained model θ0 and the fine-tuned model θ′. The merged model θ^ is computed as a linear interpolation of the two sets of weights, defined by the equation θ^=(1−α)⋅θ0+α⋅θ′, where α is a scaling factor between 0 and 1. This merging process leverages the strong cross-task generalization ability of the pre-trained model while incorporating task-specific improvements from the fine-tuned model. Unlike weight-space regularization, which may fail to preserve feature similarity, interpolation helps maintain representational consistency with the original pre-trained model.
The final step evaluates the merged representation model θ^ on the SUPERB benchmark. This evaluation involves re-training task-specific downstream models on the merged representation, ensuring that the cross-task generalization performance is assessed using the representation model itself, rather than the discarded task prediction model D used during fine-tuning. This evaluation strategy provides a fair assessment of the model’s ability to generalize across diverse speech tasks.
Experiment
The experiments evaluate the proposed Speech-FT method across supervised, unsupervised, and multi-task fine-tuning scenarios using the SUPERB benchmark to assess cross-task generalization. Supervised evaluations validate that the method consistently enhances representation quality and outperforms alternative weight-constraint strategies by preserving feature similarity to pre-trained models. Unsupervised and multi-task experiments confirm that weight-space interpolation effectively mitigates representational forgetting during cross-lingual adaptation while seamlessly integrating diverse task objectives without significant interference. Collectively, these findings demonstrate that the proposed interpolation framework provides a robust mechanism for balancing specialized learning with broad generalization across various speech representation architectures.
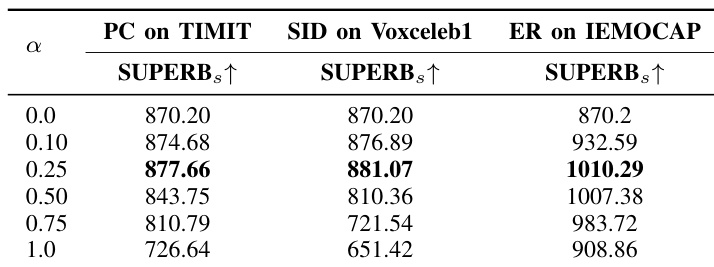
The authors investigate the impact of the interpolation hyperparameter alpha on model performance across different fine-tuning tasks. The results show that a specific value of alpha leads to the best overall performance, with improvements in cross-task generalization compared to both fully fine-tuned and pre-trained models. The optimal alpha value achieves the highest score on multiple evaluation tasks, indicating a balance between task-specific learning and preservation of general representation capabilities. A specific value of alpha achieves the highest performance across all evaluation tasks, outperforming both the pre-trained and fully fine-tuned models. The optimal alpha value leads to significant improvements in cross-task generalization, as reflected in the superior scores on unrelated tasks. The results demonstrate that interpolation effectively balances task-specific learning with the preservation of general representation capabilities.
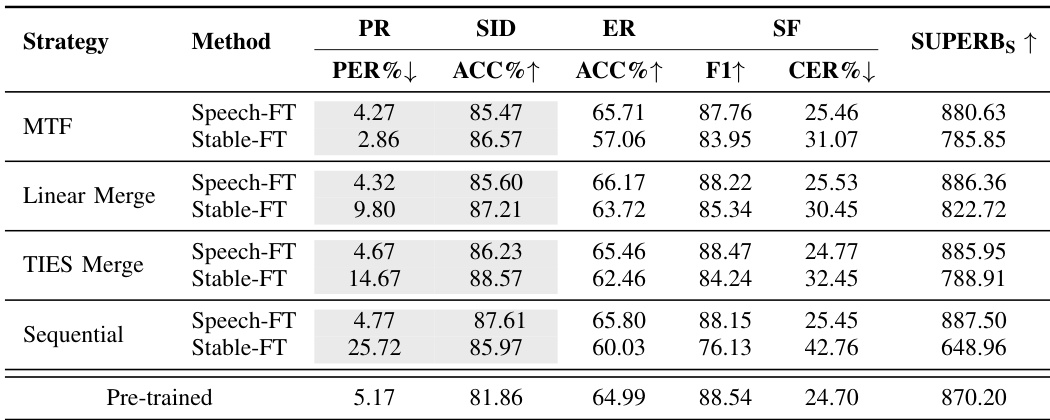
The authors evaluate multiple fine-tuning strategies, including Speech-FT and Stable-FT, across various speech tasks such as phoneme recognition, speaker identification, emotion recognition, and slot filling. Results show that Speech-FT consistently outperforms Stable-FT and achieves higher SUPERB scores, indicating better preservation of cross-task generalization. The effectiveness of Speech-FT is particularly evident in multitask settings, where it maintains strong performance across diverse tasks. Speech-FT consistently achieves higher SUPERB scores than Stable-FT across all evaluated tasks. Speech-FT maintains better cross-task generalization, especially in multitask fine-tuning scenarios. Speech-FT outperforms Stable-FT on both related and unrelated tasks, leading to improved overall representation quality.
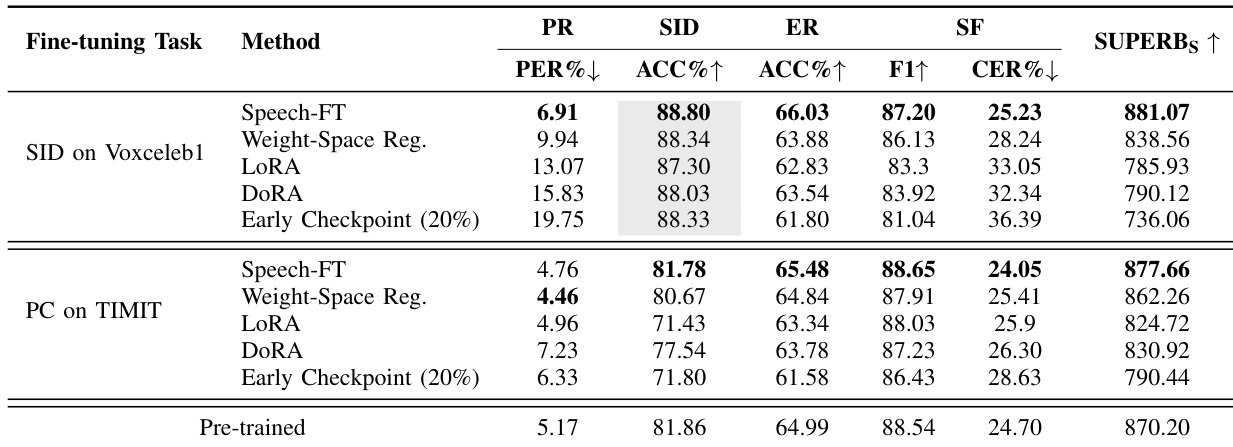
The authors evaluate the effectiveness of Speech-FT across different fine-tuning tasks and methods, comparing it against various baselines including weight-space regularization, LoRA, and early checkpoints. Results show that Speech-FT consistently outperforms these alternatives in preserving cross-task generalization, particularly on tasks unrelated to the fine-tuning objective, as evidenced by higher SUPERB scores and better feature similarity to the pre-trained model. The method demonstrates robust performance across different tasks, with notable improvements in speaker identification and emotion recognition, while maintaining strong performance on related tasks. Speech-FT achieves higher SUPERB scores compared to baselines like weight-space regularization and LoRA, especially on tasks unrelated to the fine-tuning objective. Speech-FT maintains better feature similarity to the pre-trained model than alternatives, contributing to improved cross-task generalization. Speech-FT shows consistent improvements in speaker identification and emotion recognition while preserving performance on related tasks.
The authors evaluate the effectiveness of Speech-FT in unsupervised fine-tuning scenarios across different languages, comparing it with Stable-FT and pre-trained models. Results show that Speech-FT maintains strong performance on English downstream tasks while improving adaptation to new languages, whereas Stable-FT leads to significant degradation in cross-lingual generalization. Speech-FT preserves English task performance while adapting to new languages, unlike Stable-FT which causes substantial degradation. Speech-FT achieves higher SUPERB scores on English tasks compared to Stable-FT in both cross-lingual and mono-lingual settings. Stable-FT significantly reduces cross-lingual generalization ability, as shown by lower SUPERB scores and increased error rates on Chinese and Spanish ASR tasks.
The the the table presents results from an experiment evaluating the impact of different interpolation parameters in the Speech-FT method. It compares the performance of Speech-FT with varying values of the scaling factor α against a baseline method using stable fine-tuning. The results show that Speech-FT consistently maintains high feature similarity to the pre-trained model, as indicated by the R² values, across different α settings. The performance of Speech-FT is stable across the tested values of α, with the 0.25 setting showing slightly higher similarity, suggesting a consistent ability to preserve feature representations. Speech-FT maintains high feature similarity to the pre-trained model across different interpolation parameters. The method shows stable performance with varying values of the scaling factor α, indicating robustness. Speech-FT outperforms the stable fine-tuning baseline in preserving feature similarity and maintaining cross-task generalization ability.
The experiments evaluate Speech-FT against Stable-FT and established baselines across diverse speech tasks and languages, systematically testing the method under varying interpolation parameters to validate its capacity to balance task-specific adaptation with representation preservation. These evaluations demonstrate that Speech-FT consistently outperforms alternatives by maintaining high feature similarity to the pre-trained model while effectively adapting to new objectives. The findings highlight the method's robust cross-task and cross-lingual generalization, showing that it successfully prevents performance degradation in multitask and unsupervised scenarios. Overall, the study establishes Speech-FT as a stable fine-tuning approach that reliably preserves general capabilities without sacrificing task-specific learning.