Command Palette
Search for a command to run...
تدريب وكلاء هندسة البرمجيات والمحققين باستخدام SWE-Gym
تدريب وكلاء هندسة البرمجيات والمحققين باستخدام SWE-Gym
Jiayi Pan Xingyao Wang Graham Neubig Navdeep Jaitly Heng Ji Alane Suhr Yizhe Zhang
الملخص
نقدّم SWE-Gym، البيئة الأولى المخصّصة لتدريب وكلاء الهندسة البرمجية (SWE). يحتوي SWE-Gym على 2,438 حالة مهمة واقعية، تشمل كل منها قاعدة كود بلغة Python مع بيئة تنفيذ قابلة للتشغيل، واختبارات الوحدة (unit tests)، ومهمة مُصاغَة بلغة طبيعية. نستخدم SWE-Gym لتدريب وكلاء SWE المعتمدين على النماذج اللغوية الكبيرة (LLMs)، ونحقق تحسّناً مطلقاً يصل إلى 19 نقطة مئوية في معدل الحل على مجموعتي الاختبار الشريحتين SWE-Bench Verified و Lite. كما نجري تجارب على توسيع التكلفة الحسابية أثناء الاستدلال (inference-time scaling) باستخدام مدقّقات (verifiers) مُدرَّبة على مسارات الوكلاء (agent trajectories) التي تم أخذ عينات منها من SWE-Gym. وعند دمج هذه المدقّقات مع وكلاء SWE المُدقَّقين لدينا، نحقق نتائج قدرها 32.0% و 26.0% على SWE-Bench Verified و Lite على التوالي، مما يعكس حالة فنية جديدة (state-of-the-art) لوكلاء SWE ذات الأوزان المفتوحة. وتيسيراً لإجراء المزيد من الأبحاث، نطلق علناً SWE-Gym، والنماذج، ومسارات الوكلاء.
One-sentence Summary
SWE-Gym, the first environment for training software engineering agents, contains 2,438 real-world Python tasks with executable runtimes, unit tests, and natural language specifications; fine-tuned agents achieve up to 19% absolute resolution rate gains on SWE-Bench Verified and Lite, and augmenting them with verifier-based inference-time scaling achieves a new open-weight state-of-the-art of 32.0% and 26.0% on SWE-Bench Verified and Lite, respectively.
Key Contributions
- SWE-Gym is introduced as the first training environment for software engineering agents, providing 2,438 real-world Python tasks with executable runtimes, unit tests, and natural language descriptions.
- Fine-tuning language model agents on SWE-Gym yields up to 19% absolute improvement in resolution rate on the SWE-Bench Verified and Lite benchmarks.
- Training verifiers on agent trajectories from SWE-Gym enables inference-time scaling, and combining them with the fine-tuned agents achieves a new open-weight state of the art with 32.0% on SWE-Bench Verified and 26.0% on Lite.
Introduction
The authors address the challenge of training language model agents for software engineering: although evaluation benchmarks like SWE‑Bench exist, they only measure performance without providing the executable environments, repository‑level context, and test suites needed to improve agents through learning. They introduce SWE‑Gym, the first training environment that supplies 2,438 real‑world Python tasks with pre‑configured runtimes, unit tests, and natural‑language instructions. By fine‑tuning agents on these tasks and training verifiers on collected agent trajectories for inference‑time scaling, they achieve a new open‑weight state‑of‑the‑art on SWE‑Bench Verified and Lite, with resolution rates of 32.0% and 26.0% respectively.
Dataset
SWE-Gym: A Training Environment for Software Engineering Agents
The authors introduce SWE-Gym, a dataset and training environment built from real-world GitHub pull requests and issues. It provides executable tasks with verified test suites for training and evaluating LLM-based software engineering agents.
-
Main SWE-Gym
- 2,438 tasks collected from merged pull requests across 11 popular Python repositories (distinct from SWE-Bench).
- Each task pairs a natural language issue description with a pre-configured executable environment and expert-validated unit tests for verification.
- Repositories include sophisticated projects like pandas and MONAI; the distribution is long-tailed.
-
SWE-Gym Lite
- A curated subset of 230 easier, self-contained tasks.
- Filtered from the main set following the SWE-Bench Lite pipeline: excludes tasks that edit multiple files, have poorly described problem statements, involve overly complex ground-truth patches, or use tests that only check error messages.
-
SWE-Gym Raw
- A much larger collection of 64,689 Python GitHub issues from 358 repositories.
- These instances lack pre-installed executable environments and are intended for research on automatic dataset synthesis.
-
How the paper uses the data
- The authors sample interaction trajectories by running strong frontier models (GPT-4o, Claude 3.5 Sonnet) inside the executable environments.
- They vary decoding temperatures and maximum turns, keeping only trajectories that pass the unit tests.
- From SWE-Gym Lite and the full SWE-Gym set, they gather 491 successful trajectories (denoted D₂).
- These trajectories serve as supervised fine-tuning data for software engineering agents, and the test outcomes provide reward signals for training verifiers.
-
Processing and construction details
- No additional cropping or preprocessing is applied; tasks are used as provided by the SWE-Gym environment.
- Each instance includes a repository snapshot, the issue text, and an executable test suite that automatically validates a generated git patch.
- During trajectory collection, the maximum number of agent turns is capped at 30 or 50 depending on the experiment.
- The environment closely mirrors SWE-Bench’s format, ensuring compatibility while using disjoint repositories to avoid contamination.
Method
The authors leverage the SWE-Gym environment to scale agent performance, primarily focusing on inference-time scaling through the use of learned verifiers. The trajectories sampled from the environment are utilized not only for training a policy but also for training an outcome-supervised reward model. This verifier model takes the relevant context of the task execution as input, which includes the problem statement, the agent trajectory, and the current git diff. It then generates a score that estimates the probability of the agent having successfully solved the problem. During inference, the authors experiment with using this model to rerank candidate trajectories sampled from the agent policy, demonstrating that such learned verifiers enable effective scaling for further performance improvement.
For the specific implementation of the MoatlessTools verifier, the authors design a specialized prompt generation process. Unlike prior methods that rely on proprietary models for context extraction, this approach obtains context directly from the agent trajectory being evaluated. The system prompt establishes the model as an expert in Python for software engineering and code review, tasking it with reviewing patches and providing feedback on code quality. The user prompt instructs the model to evaluate a candidate patch intended to resolve a specific issue. To assist in this evaluation, the prompt provides the issue text from a GitHub repository, along with identified code spans relevant to the issue. These code spans include file paths, unique span identifiers, and line numbers to provide adequate context. Furthermore, the prompt includes the candidate patch itself, presenting the hunks of the original code and the code after applying the patch using distinct tags. The verifier is then prompted to respond with a binary output indicating whether the patch has successfully resolved the issue.
Experiment
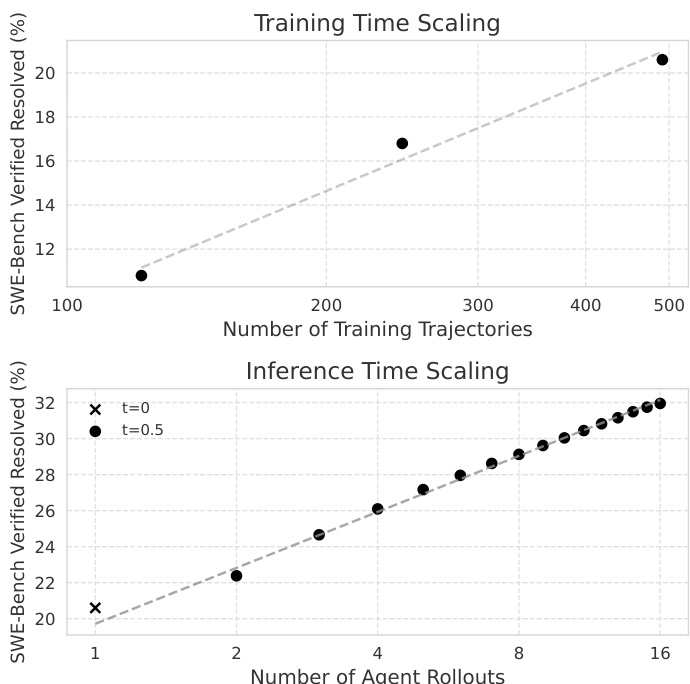
SWE-Gym provides executable training environments with real-world Python tasks from GitHub issues, enabling fine-tuning of language model agents and verifiers. Agent training on only 491 sampled trajectories delivers substantial resolution-rate improvements on SWE-Bench, greatly reduces stuck-in-loop behavior, and scales well with model size and dataset volume. A trained verifier selects the best from multiple candidate solutions, setting a new state-of-the-art for open-weight systems and demonstrating log-linear gains with inference compute. The findings suggest that performance is currently limited by sampling compute rather than environment diversity, and that specialized workflows permit effective self-improvement while mitigating easy-task bias through per-instance capping.
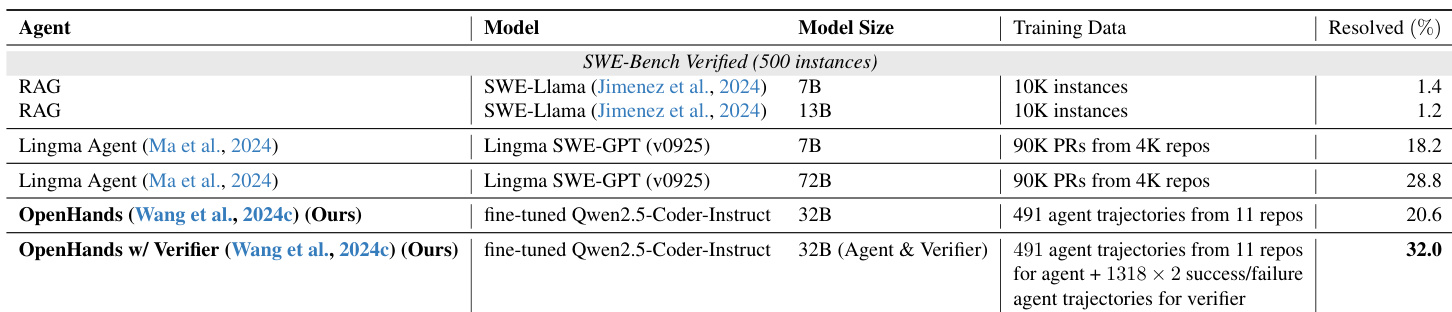
The authors compare their SWE-Gym agent and verifier system against concurrent works, demonstrating that their approach achieves competitive performance on SWE-Bench benchmarks despite using a significantly smaller model size. While a concurrent work by Golubev et al. achieves the highest performance on the Verified split, it relies on a much larger model and does not release the model weights. In contrast, the authors' system fully open-sources both the model weights and the environment, offering a more complete solution. The authors' 32B model outperforms the 72B model from Ma et al. on both SWE-Bench Lite and Verified splits. The authors' approach is the only listed method that provides full openness by releasing both the model weights and the execution environment. Golubev et al. achieve the highest performance on SWE-Bench Verified but do not release their model weights.

The provided the the table compares the resolution rates of various software engineering agents on the SWE-Bench Verified benchmark. The authors' proposed system, which integrates a verifier with an OpenHands agent, achieves the highest performance among the listed methods. This result demonstrates that their approach can outperform larger models from concurrent works while utilizing significantly less training data. The authors' OpenHands agent combined with a verifier achieves the top resolution rate, surpassing RAG baselines and larger models like Lingma SWE-GPT. The proposed method shows strong data efficiency, outperforming a 72B model trained on a large dataset using a 32B model trained on a small set of trajectories. The inclusion of a verifier model substantially boosts the performance of the base agent, leading to the best overall results in the comparison.
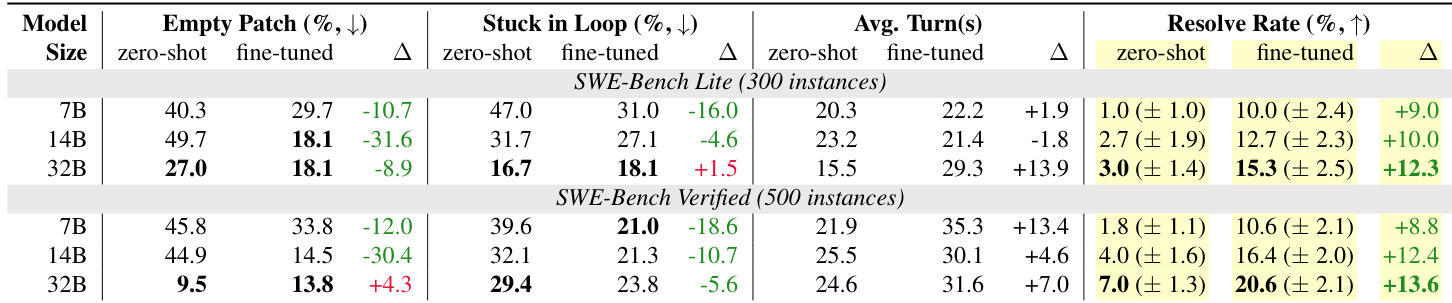
The authors investigate per-instance capping strategies to mitigate data bias during self-improvement training for a model using a specialized workflow scaffold. Results demonstrate that limiting the number of successful trajectories per task instance improves performance, with a specific threshold achieving the best resolution rate and lowest empty patch rate. This method outperforms training on the full uncapped dataset, suggesting that unfiltered data introduces bias toward easier tasks. Applying a moderate per-instance cap yields the highest resolution rate and the lowest empty patch rate compared to higher caps and the uncapped dataset. Training on the full dataset without capping results in slightly lower resolution rates than the optimal cap, likely due to a bias toward easier tasks. Fine-tuning significantly reduces the empty patch rate compared to the zero-shot baseline, indicating the model learns to generate code edits more effectively.

The authors fine-tune Qwen-2.5-Coder models of varying sizes on agent-environment interaction trajectories from SWE-Gym to improve software engineering capabilities. Results show that fine-tuning substantially increases the resolution rate on SWE-Bench benchmarks while generally reducing empty patch and stuck-in-loop rates. Additionally, larger base models consistently achieve higher resolution rates, demonstrating that performance scales with model size both before and after fine-tuning. Fine-tuning on SWE-Gym trajectories leads to significant improvements in task resolution rates across all evaluated model sizes. The training process effectively reduces the frequency of empty patches and stuck-in-loop behaviors for most models. Larger models consistently achieve better resolution rates and lower error rates compared to smaller models in both zero-shot and fine-tuned settings.
The the the table presents statistics on the length of agent trajectories, distinguishing between resolved and unresolved attempts. While the average message and token counts are comparable, unsuccessful trajectories exhibit much higher variance and maximum token limits. This suggests that failed attempts tend to be more erratic and lengthy compared to the more consistent successful trajectories. The collected dataset contains a significantly higher number of unsuccessful trajectories than successful ones. Successful trajectories demonstrate lower standard deviation in both message and token counts, indicating more consistent behavior. Unsuccessful trajectories reach much higher maximum token counts, suggesting that failing agents often produce excessively long responses.

The authors evaluate their SWE-Gym agent system on SWE-Bench benchmarks, demonstrating that an open-source 32B model combined with a verifier achieves state-of-the-art performance on the Verified split, surpassing larger concurrent models and RAG baselines while using substantially less training data. Per-instance capping during self-improvement training mitigates data bias, leading to higher resolution rates and fewer empty patches compared to using the full unfiltered dataset. Fine-tuning on SWE-Gym agent trajectories consistently improves resolution rates and reduces empty‑patch and stuck‑in‑loop errors across model sizes, with larger models scaling better, and a trajectory analysis reveals that successful attempts are more consistent, whereas unsuccessful attempts tend to be more erratic and lengthy.