Command Palette
Search for a command to run...
تمثيل مخصص من التوليد المخصص
تمثيل مخصص من التوليد المخصص
Shobhita Sundaram Julia Chae Yonglong Tian Sara Beery Phillip Isola
توصيات مخصصة
الملخص
النماذج البصرية الحديثة تتفوق في المهام الفرعية العامة. ومع ذلك، لا يزال من غير الواضح كيفية استخدامها في المهام البصرية المخصصة، والتي تتميز بأنها دقيقة للغاية وتفتقر إلى البيانات. لقد نجحت الأعمال الحديثة في تطبيق البيانات الاصطناعية على تعلم التمثيلات العامة، بينما مكّنت التطورات في نماذج الانتشار لتوليد الصور من النص (T2I) من إنشاء صور مخصصة بناءً على عدد قليل من الأمثلة الحقيقية فقط. هنا، نستكشف ارتباطاً محتملاً بين هذين المفهومين، ونصوغ تحدي استخدام البيانات الاصطناعية المخصصة لتعلم التمثيلات المخصصة، التي تشفر المعرفة حول كائن محل الاهتمام ويمكن تطبيقها بمرونة على أي مهمة فرعية تتعلق بالكائن المستهدف. نقدم مجموعة تقييم لهذا التحدي، تشمل إعادة صياغتين لمجموعتي بيانات موجودتين ومجموعة بيانات جديدة تم بناؤها خصيصاً لهذا الغرض، ونقترح نهجاً للتعلم التبايني يستخدم مولدات الصور بشكل إبداعي. نوضح أن منهجنا يحسّن تعلم التمثيلات المخصصة لمجموعة متنوعة من المهام الفرعية، بدءاً من التعرف على الأشياء وصولاً إلى التقسيم الدلالي، ونحلل خصائص أساليب توليد الصور التي تُعد أساسية لهذا التحسن.
One-sentence Summary
The authors propose a contrastive learning framework that leverages text-to-image diffusion models to generate personalized synthetic data from a few real examples, addressing data-scarce vision tasks through an evaluation suite of reformulated and novel datasets while demonstrating improved personalized representation learning across recognition and segmentation benchmarks.
Key Contributions
- The study formalizes the challenge of learning personalized representations from data-scarce scenarios and introduces an evaluation suite featuring a novel instance-level dataset, PODS, alongside reformulated splits and annotations for two existing benchmarks.
- A contrastive learning framework adapts general-purpose representation spaces by conditioning text-to-image diffusion models on few-shot real examples, enabling synthetic data generation that operates without external real negatives.
- Empirical evaluations across recognition and segmentation tasks demonstrate consistent performance gains, while the analysis identifies critical image generation characteristics and assesses computationally efficient multi-method synthesis alternatives.
Introduction
Modern vision models excel at broad recognition tasks but struggle with fine-grained personalization, which requires learning instance-specific representations from minimal real examples. This capability matters because it enables private, localized model training without relying on centralized data repositories or extensive user annotations. Prior approaches typically depend on large-scale labeled datasets, require external data sharing, or treat image generation and representation learning as disconnected pipelines, making them impractical for few-shot scenarios. The authors leverage text-to-image diffusion models to synthesize diverse training examples from just a handful of real images and apply contrastive fine-tuning to adapt a general-purpose vision backbone. This strategy produces robust personalized representations that consistently boost performance across classification, retrieval, detection, and segmentation tasks. To advance the field, the authors also release a dedicated evaluation suite and a new instance-level dataset designed specifically for benchmarking personalized representation learning.
Dataset
-
Dataset Composition and Sources
- The authors evaluate personalized representation learning using three distinct datasets: DeepFashion2 (DF2), DogFaceNet, and a newly introduced benchmark called PODS (Personal Object Discrimination Suite).
- DF2 provides large-scale commercial and consumer fashion imagery focused on shirts, DogFaceNet supplies dog re-identification footage, and PODS features 100 everyday personal objects captured across five categories (mugs, screwdrivers, shoes, bags, and water bottles) using an iPhone 15 Pro and the PolyCam app.
-
Key Details for Each Subset
- DeepFashion2: The authors extract 169 unique shirt instances from the validation split after filtering for categories with sufficient gallery images. The final subset contains 507 training images and 1,271 test images, strictly allocating three training images per instance and four to twenty-four test images per instance.
- DogFaceNet: From the DogFaceNet_large split, the authors retain only classes with more than ten images per instance. They perform a random train-test split, manually inspect all sequences to eliminate data poisoning from overlapping footage, and discard instances with fewer than four remaining test images. The cleaned subset holds 80 dogs, yielding 240 training images and 1,218 test images.
- PODS: This custom dataset includes 100 objects (20 per category) recorded across four controlled scenes: a canonical training scene, a distractor-heavy scene, a pose-variation scene, and a combined variation scene. Each object is captured at three vantage points, resulting in 300 training images and 10,888 test images, with 1,200 test images receiving dense annotations.
-
Data Usage and Training Configuration
- The authors treat the three-image training split as positive examples for contrastive fine-tuning, pairing them with a large pool of negative samples to learn instance-level representations.
- They assess model performance across classification, retrieval, detection, and segmentation tasks, deliberately structuring test sets to include both in-distribution and out-of-distribution scenarios for robustness evaluation.
- The data supports comparative experiments between standard DreamBooth fine-tuning and computationally lighter alternatives like Cut-and-Paste and Masked DreamBooth, allowing the authors to measure how real versus generated data impacts representation quality.
-
Annotation, Metadata, and Processing Strategies
- Metadata Construction: Each object receives a unique identifier, and all test images are labeled for classification and retrieval. The authors generate 100 instance-specific prompts per object using an LLM, replacing object names with a
<new1>placeholder to standardize training inputs. - Mask Generation and Cropping: Ground truth segmentation masks are manually annotated for DF2 and Dogs. For PODS, the authors generate initial mask proposals with Grounding-SAM and refine them manually using TORAS, then extract bounding boxes directly from these masks.
- DreamBooth Processing: To prevent background overfitting, the authors apply gradient masking during DreamBooth training, zeroing out gradients for background pixels. They also implement an automatic filtering step that uses DreamSim and perSAM to embed masked training and generated images. They compute cosine similarity between embeddings and discard generated samples falling below a threshold of 0.6 for DF2 and PODS, and 0.55 for Dogs.
- Cut-and-Paste Synthesis: When masks are available, the authors extract foreground objects and composite them onto LLM-generated backgrounds. They remove the
<new1>placeholder from background prompts, randomly resize the foreground to 0.3 to 1.3 times its original scale, and paste it at random coordinates.
- Metadata Construction: Each object receives a unique identifier, and all test images are labeled for classification and retrieval. The authors generate 100 instance-specific prompts per object using an LLM, replacing object names with a
Method
The authors leverage a three-stage method to achieve personalized visual representation using generative models. The overall framework begins with a small set of real images of a target instance c, denoted as DR, and the generic category cpr associated with the object. The goal is to adapt a general-purpose vision encoder fϕ to produce a personalized representation for c by training on synthetic data generated from a pretrained generative model.
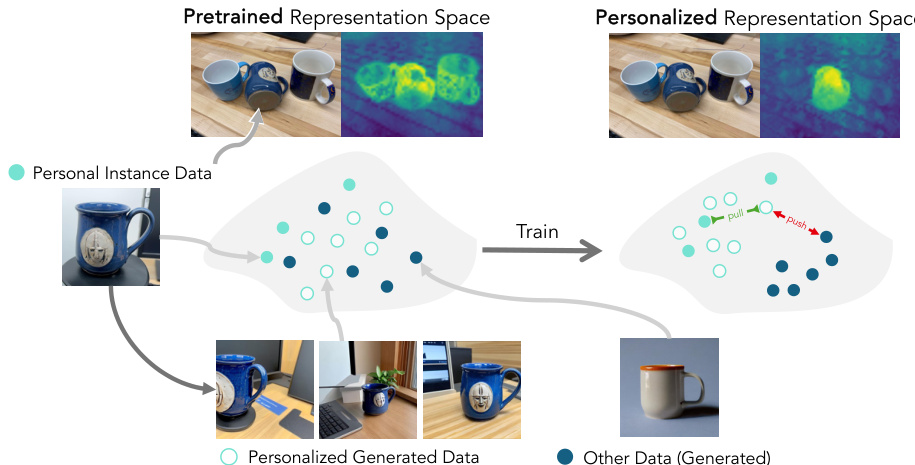
Refer to the framework diagram, which illustrates the transformation from a pretrained representation space to a personalized one. The process starts with the personal instance data, which is used to train a generator. The generator then produces personalized synthetic data, which is used to train the representation model. The figure shows that real images of the target instance are fed into the system, and the generator learns to produce new images of the instance. The personalized representation space is then trained to distinguish the target instance from other data, using both real and generated images.
In the first stage, the authors generate personalized data from DR using Stable Diffusion 1.5, a text-to-image (T2I) model, as the generator gθ. They adapt gθ using DreamBooth, which fine-tunes the model to generate novel images of c when conditioned on an identifier token. The T2I diffusion model gθ generates images given an initial noise latent ϵ∼N(0,1) and a conditioning text embedding y^=Γω(y), where Γω is a text encoder and y is a user-provided prompt. DreamBooth fine-tunes gθ using a loss function that includes a reconstruction loss on the real image x and a prior preservation loss on a synthesized image xpr conditioned on the generic category cpr. The loss is defined as:
Ex,y^,ϵ,ϵ′,t[wt∣∣gθ(αtx+σtϵ,y^)−x∣∣22]+λwt′∣∣gθ(αt′xpr+σt′ϵ′,c^pr)−xpr∣∣22],where xpr is an image synthesized with the pre-trained generator conditioned on cpr, t is the timestep, and variables αt, σt, and wt relate to the noise schedule and sampling quality. The first term is a reconstruction loss on x, and the second term is a prior preservation loss on xpr, weighted by λ. The text encoder Γω is also fine-tuned with the same loss.
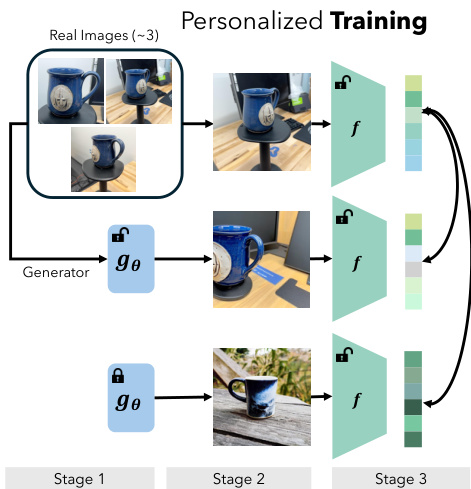
As shown in the figure below, the personalized training pipeline consists of three stages. Stage 1 involves training the generator gθ on real images of the target instance. Stage 2 involves generating synthetic data using the trained generator. Stage 3 involves fine-tuning the vision encoder fϕ on the generated synthetic data using a contrastive objective.
In the second stage, the authors generate synthetic data DS using the trained generator gθ. The generated data is used to train the personalized representation model. The authors control the attributes of the generated dataset by using classifier-free guidance (CFG) to inject diversity into the generated outputs, experimenting with CFG values of 4.0, 5.0, and 7.5. They also use LLM-generated captions to provide rich context descriptions for the target object, ensuring that the generated data is diverse and realistic.
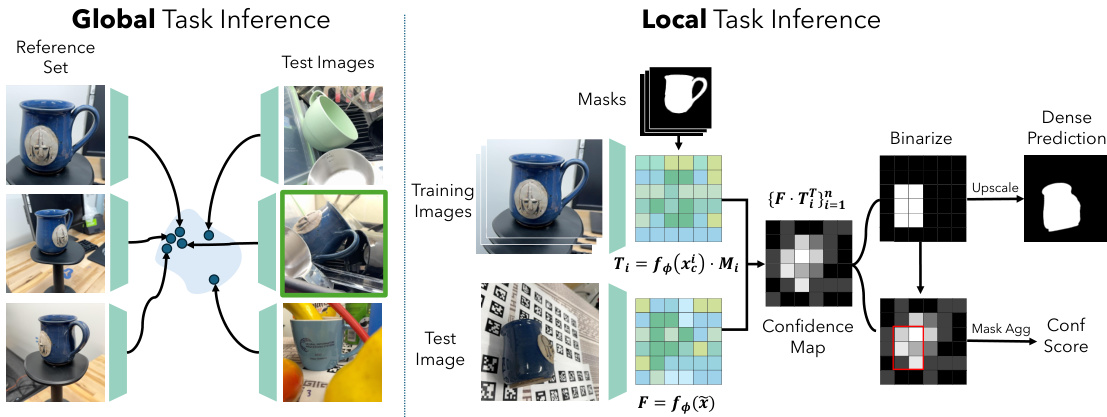
As shown in the figure below, the inference pipelines for global and local tasks are illustrated. For global tasks, such as classification and retrieval, the model uses cosine similarity between CLS embeddings. For local tasks, such as detection and segmentation, the model extracts patch features with spatial information. The figure shows that the training images are used to generate feature maps, which are then processed to produce dense predictions and confidence scores.
In the third stage, the authors train a personalized representation on the generated synthetic data using a contrastive objective. Given the real images DR and the synthetic data DS, they obtain positive examples from DS and negative examples D~S by prompting the pretrained generator with the generic object category: "a photo of cpr". They extract features from the vision encoder fϕ as a concatenation of the CLS token and average-pooled final-layer patch-embeddings. They then fine-tune fϕ using the infoNCE loss:
LInfoNCE=−log∑i=1Nexp(sim(x0,xi)/τ)exp(sim(x0,x+)/τ).This loss pushes together the representations of real and synthetic images of c, and pushes apart representations of c and other instances. The authors fine-tune via Low-Rank Adaptation (LoRA), which is more parameter-efficient than full fine-tuning. They experiment with several state-of-the-art backbones, including DINOv2-ViT B/14, CLIP-ViT B/16, and MAE-ViT B/16. Each dataset is randomly divided into validation and test sets, and the authors sweep over key training parameters on the validation set to determine the optimal configuration. Based on their validation experiments, they LoRA fine-tune with the infoNCE loss for 2 epochs over 4500 anchor-positive pairs, drawn from 450 synthetic positives and 1000 synthetic negatives.
Experiment
The experiments evaluate personalized visual representations trained on minimal real examples augmented with synthetic data against standard pretrained models across classification, retrieval, segmentation, and detection tasks. Results demonstrate that personalization consistently enhances both global semantic understanding and precise object localization, with combined synthetic generation strategies proving most effective by balancing visual fidelity and pose diversity. While different data generation techniques introduce distinct inductive biases, such as DreamBooth’s superior pose generalization versus Cut-and-Paste’s strict object fidelity, the findings confirm that carefully curated synthetic augmentation significantly elevates representation quality. Furthermore, these personalized features seamlessly integrate into downstream pipelines and maintain robust performance as real training data scales, highlighting the enduring practical value of synthetic data for few-shot personalization.
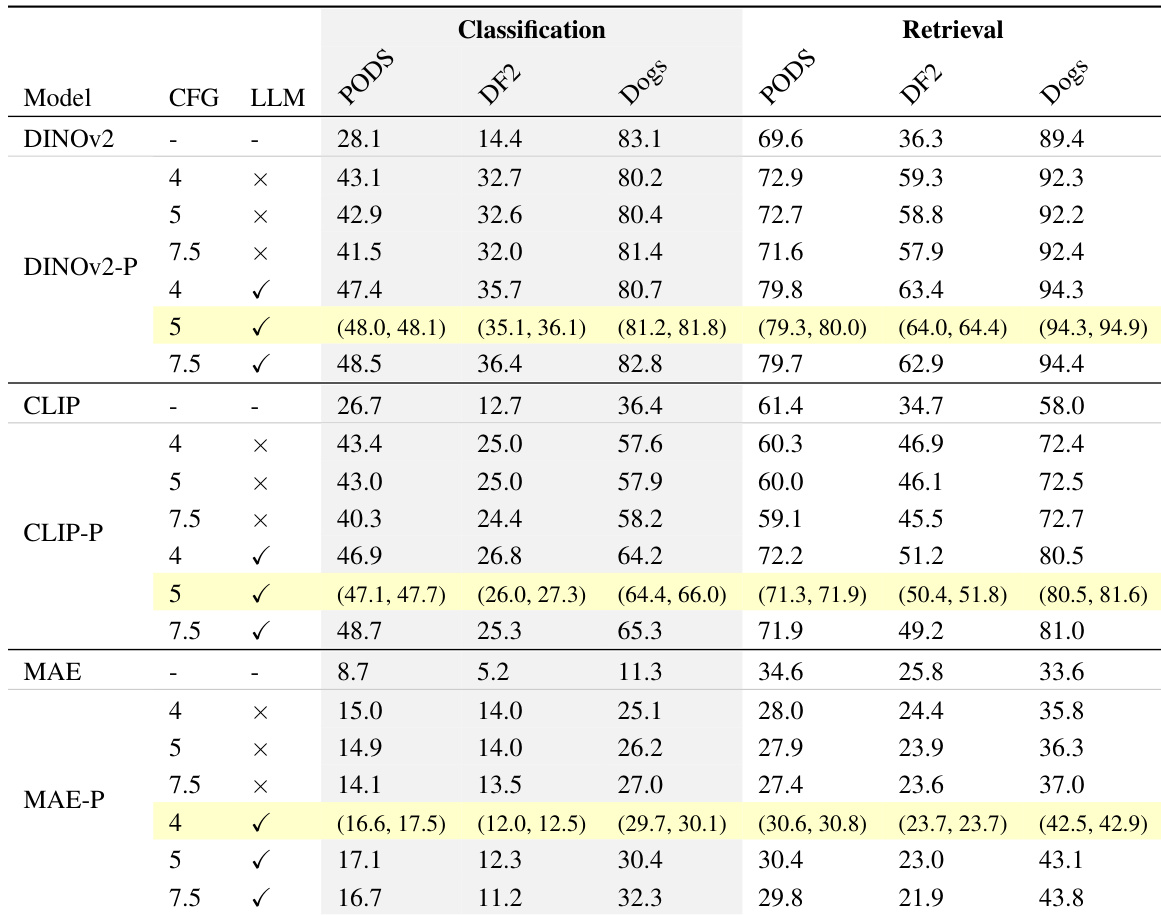
The authors evaluate personalized representations trained with synthetic data against pretrained models across multiple backbones and tasks, finding that personalized models consistently outperform pretrained models in classification and retrieval tasks. The performance gains are particularly notable for DINOv2 and CLIP, with improvements observed across different datasets and tasks, although the gains are less pronounced for MAE. The best results are achieved using synthetic data generated with specific configurations, such as higher CFG values and LLM-generated prompts, which enhance representation quality. Personalized representations consistently outperform pretrained models across classification and retrieval tasks for DINOv2 and CLIP backbones. Synthetic data generated with higher CFG values and LLM prompts leads to better performance in classification and retrieval tasks. MAE-based personalized representations show smaller improvements compared to DINOv2 and CLIP, indicating varying effectiveness across different backbones.
The authors evaluate different loss functions for personalized representations, comparing InfoNCE, InfoNCE with multi-positive, Hinge, and Cross-Entropy against a baseline. Results show that InfoNCE consistently outperforms other loss functions across both classification and retrieval tasks, with the best performance achieved using InfoNCE for classification and retrieval. The personalized model (DINOv2-P) significantly improves retrieval performance compared to the pretrained baseline, while classification performance varies more across loss functions. InfoNCE achieves the highest performance for both classification and retrieval tasks. DINOv2-P outperforms the pretrained DINOv2 baseline in retrieval, with a notable improvement. Classification performance varies more across loss functions, with InfoNCE showing the best results.

The authors compare different methods for generating synthetic data to personalize vision models, evaluating their performance across classification, retrieval, detection, and segmentation tasks. Results show that combining multiple data augmentation strategies leads to the best overall performance, with improvements across most tasks and datasets compared to using real images alone or single augmentation methods. Combining multiple data augmentation methods achieves the highest performance across all tasks and datasets. Using synthetic data with real backgrounds and negatives significantly outperforms using only real images for most tasks. Different augmentation methods show distinct strengths, with some excelling in classification and others in dense prediction tasks.
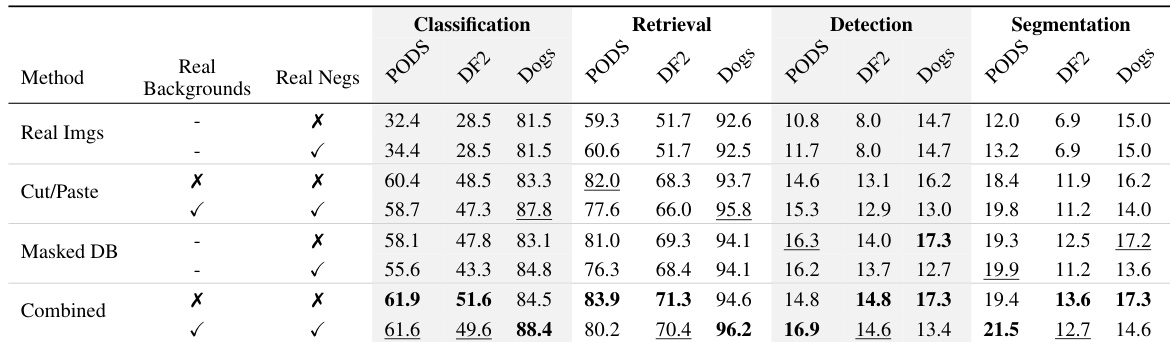
The authors compare the runtime efficiency of different synthetic data generation methods for training personalized representations. Results show that the Cut/Paste method with real backgrounds is the fastest, requiring minimal generation time, while DreamBooth methods are significantly slower, especially when filtering is applied. The total runtime for DreamBooth with filtering is substantially higher due to the time-intensive generation process. Cut/Paste with real backgrounds is the fastest method, requiring minimal generation time. DreamBooth methods are substantially slower, with filtering increasing generation time significantly. Total runtime for DreamBooth with filtering is much higher due to prolonged generation processes.

The authors compare the performance of personalized representations against pretrained models across classification and retrieval tasks, using varying numbers of synthetic images and anchor-positive pairs. Results show that personalized models generally outperform pretrained models, with improvements observed across both global and dense tasks. The best performance is achieved when combining a large number of anchor-positive pairs with a fixed number of synthetic images. Personalized models outperform pretrained models in both classification and retrieval tasks. Increasing the number of anchor-positive pairs improves performance, with the best results achieved at higher ratios. Performance improvements are consistent across different datasets and tasks, indicating robustness of the personalized approach.
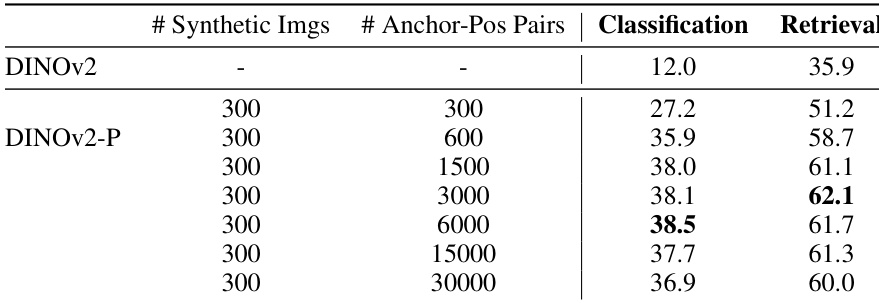
The experiments evaluate personalized vision representations trained with synthetic data against pretrained baselines to validate the impact of backbone architecture, loss functions, generation strategies, training data ratios, and computational efficiency across classification, retrieval, detection, and segmentation tasks. Results consistently demonstrate that personalized models outperform pretrained counterparts, with DINOv2 and CLIP benefiting most from synthetic data generated using high CFG values, LLM prompts, and combined augmentation strategies. The analysis further reveals that InfoNCE loss functions yield the strongest representation quality, while increasing anchor-positive pair ratios enhances performance and robustness across diverse datasets. Although generation methods like Cut/Paste offer superior runtime efficiency compared to computationally intensive approaches like DreamBooth, the overall findings establish that carefully constructed synthetic data significantly improves model personalization and generalization.