Command Palette
Search for a command to run...
GLM-4-Voice: نحو روبوت محادثة منطوق ذكي وشبيه بالإنسان من البداية إلى النهاية
GLM-4-Voice: نحو روبوت محادثة منطوق ذكي وشبيه بالإنسان من البداية إلى النهاية
Aohan Zeng Zhengxiao Du Mingdao Liu Kedong Wang Shengmin Jiang Lei Zhao Yuxiao Dong Jie Tang
نشر GLM-4-Voice بنقرة واحدة: نموذج دردشة صوتية شاملة بين الصينية والإنجليزية من البداية إلى النهاية
الملخص
نقدم GLM-4-Voice، وهو روبوت محادثة صوتية ذكي وشبيه بالبشر يعمل بنظام النهاية إلى النهاية. يدعم النظام كل من اللغتين الصينية والإنجليزية، ويتيح إجراء محادثات صوتية في الوقت الفعلي، مع تنويع الفروق الدقيقة الصوتية مثل العاطفة، والنبرة، وسرعة الكلام، واللهجة وفقاً لتعليمات المستخدم. يستخدم GLM-4-Voice مرمّز كلام (speech tokenizer) أحادي الكتاب الرمزي (single-codebook) بمعدل بت منخفض للغاية (175 بت في الثانية) ومعدل إطارات يبلغ 12.5 هرتز، وهو مستمد من نموذج التعرف التلقائي على الكلام (ASR) من خلال دمج عنق زجاجة معتمد على التكميم المتجهي (vector-quantized bottleneck) في المشفر. ولنقل المعرفة بكفاءة من النصوص إلى نماذج الكلام، نقوم بتوليد بيانات متداخلة من الكلام والنص من مجموعات البيانات الموجودة المسبقة التدريب للنصوص باستخدام نموذج من النص إلى الرموز (text-to-token). نستمر في التدريب المسبق بدءاً من نموذج اللغة النصية المسبق التدريب GLM-4-9B، باستخدام مزيج من بيانات الكلام غير الخاضعة للإشراف، وبيانات الكلام والنص المتداخلة، وبيانات الكلام والنص الخاضعة للإشراف، مع توسيع نطاق التدريب ليصل إلى تريليون رمز (token)، مما يحقق أداءً متفوقاً في كل من نمذجة لغة الكلام والإجابة على الأسئلة المنطوقة. ثم نقوم بضبط النموذج المسبق التدريب بدقة باستخدام بيانات محادثات كلامية عالية الجودة، مما يحقق أداءً متفوقاً مقارنة بالأسس المرجعية الحالية في كل من القدرة على المحادثة وجودة الكلام. يمكن الوصول إلى النماذج مفتوحة المصدر عبر الرابط https://github.com/THUDM/GLM-4-Voice و https://huggingface.co/THUDM/glm-4-voice-9b.
One-sentence Summary
GLM-4-Voice is an intelligent, human-like end-to-end spoken chatbot that enables real-time Chinese and English conversations with dynamic vocal nuances by leveraging a 175 bps single-codebook speech tokenizer and pre-training on one trillion tokens of synthesized speech-text interleaved data to achieve state-of-the-art performance in speech language modeling and spoken question answering, while subsequent fine-tuning yields superior conversational ability and speech quality compared to existing baselines.
Key Contributions
- GLM-4-Voice is an end-to-end spoken chatbot that supports real-time voice conversations with dynamic control over emotion, intonation, and dialect. The architecture utilizes a novel ultra-low bitrate (175bps) single-codebook speech tokenizer derived from an ASR encoder with a vector-quantized bottleneck to achieve a 12.5Hz frame-level representation.
- To align text and speech modalities, the framework synthesizes interleaved speech-text corpora from existing text pre-training datasets and continues pre-training from the GLM-4-9B language model. This cross-modal training scales to one trillion tokens of mixed unsupervised, interleaved, and supervised data, establishing strong baseline capabilities in speech language modeling and automatic speech recognition.
- The model undergoes conversational fine-tuning with a streaming thoughts template that alternates between text and speech tokens to enable low-latency dialogue generation. Extensive evaluations demonstrate state-of-the-art results in spoken question answering, along with superior speech quality and conversational fluency compared to prior baselines.
Introduction
Voice-based interaction provides a more natural and expressive medium for human-computer communication, yet traditional spoken chatbots rely on disjointed ASR, language model, and text-to-speech pipelines that introduce high latency, compounding errors, and limited emotional nuance. End-to-end speech language models offer a promising alternative, but they are constrained by the severe scarcity of speech data relative to text corpora and often lack dedicated speech pre-training, which restricts their ability to generate fluent, human-like prosody and dynamic vocal style. The authors leverage a single-codebook supervised speech tokenizer operating at 12.5Hz to efficiently discretize audio streams, effectively bridging the text and speech modalities through massive pre-training on one trillion tokens of interleaved and unsupervised speech-text data. They further enhance conversational fluency by fine-tuning the model with a streaming thought template that alternates between text and speech tokens. This approach enables real-time, low-latency voice interactions that dynamically adjust emotion, intonation, and pacing while achieving state-of-the-art performance across speech modeling, question answering, and synthesis tasks.
Dataset
- The authors structure the dataset across two training phases to develop a speech-enabled language model and a spoken conversational agent.
- Stage 1 Joint Pre-training
- Interleaved speech-text pairs synthesized from existing text corpora to enable cross-modal alignment
- Approximately 700k hours of unsupervised real-world speech for general acoustic learning
- Supervised speech-text pairs covering automatic speech recognition and text-to-speech tasks
- Standard text pre-training datasets mixed in to preserve native language capabilities
- Stage 2 Spoken Chatbot Fine-tuning
- Multi-turn conversational dialogues derived from text sources, strictly filtered to exclude code and mathematical content. The team shortens verbose responses, removes verbally unnatural phrasing, synthesizes matching audio, and supplements the set with human-recorded inputs to boost real-world diversity
- Style-controlled multi-turn dialogues specifically curated to model variations in speaking rate, emotional tone, and regional dialects
- Data Processing and Usage
- The initial pre-training phase blends the speech subsets with text corpora in unspecified ratios to jointly optimize speech and language modeling
- All conversational data undergoes quality filtering, length reduction, and audio synthesis or human recording before deployment for chatbot training
- Complete dataset statistics and mixture breakdowns are referenced in the original paper
Method
The authors leverage a minimal modification to the autoregressive transformer architecture to design GLM-4-Voice, a model aimed at creating a human-like, end-to-end spoken chatbot capable of both comprehending speech and generating expressive spoken responses. The core architecture integrates a unified speech representation for both input and output, enabling next-token prediction on speech data and facilitating efficient pre-training on large-scale, unsupervised speech corpora. This design preserves the model's text processing capabilities while enabling effective speech modeling through a single-codebook speech tokenization approach, which avoids the complexity of multi-layer speech token generation.

The speech tokenization process converts continuous audio waveforms into discrete speech tokens that preserve semantic information and a portion of acoustic detail. The model employs a supervised speech tokenizer, specifically the 12.5Hz variant described in Zeng et al., which is finetuned from a pretrained automatic speech recognition model, such as whisper-large-v3. This tokenizer architecture includes a feed-forward network and a pooling layer within the encoder, followed by a vector quantization layer with codebook vectors learned via exponential moving average. To ensure low-latency interaction, the Whisper encoder is adapted for causality by replacing its convolution layer with a causal convolution and its bidirectional attention with block causal attention, enabling streaming encoding of input speech. The tokenizer is fine-tuned on a diverse collection of ASR datasets and unsupervised speech data with pseudo labels, using a ratio of supervised to pseudo-labeled samples of 1:3, and the selected 12.5Hz variant is chosen for its optimal balance between quality and bitrate.
The speech decoder synthesizes high-quality speech waveforms from the discrete speech tokens and is designed for low-latency streaming inference. It adopts the architecture of CosyVoice, comprising a speech token encoder, a conditional flow matching model, and a HiFi-GAN vocoder. The decoder is trained in a two-stage paradigm: a pre-training stage on diverse, low-quality speech data from various speakers, followed by a fine-tuning stage on high-quality, single-speaker data. To support streaming inference, the model processes truncated audio samples in blocks during fine-tuning, allowing it to generate speech tokens with a minimum delay of a predefined block size, which is set to 0.8 seconds for GLM-4-Voice. This enables the decoder to process speech tokens corresponding to the first n⋅b seconds of audio, using the preceding (n−1)b seconds as a prompt to predict the next segment.
The inference process decouples the speech-to-speech task into two subtasks: speech-to-text and speech-and-text-to-speech. Given a user's speech input Qs, the model first generates a text response At, and then generates a speech output As using both Qs and At to ensure conversational coherence. To reduce latency, the model employs a "Streaming Thoughts" template, which alternates between generating text and speech tokens at a specified ratio. Based on the 12.5Hz tokenizer, the model alternates between generating 13 text tokens and 26 speech tokens, ensuring that text generation remains faster than speech generation to maintain contextual coherence.
The overall response latency is composed of four sequential stages: speech tokenization, LLM prefilling, LLM decoding, and speech decoding. The speech tokenization latency depends on the block size of the input audio. The LLM prefilling latency is determined by the number of speech tokens generated, which is based on the user's speech duration and the frame rate. The LLM decoding latency for the initial audio response is calculated based on the number of tokens generated for the first speech chunk. Finally, the speech decoding latency is determined by the number of audio tokens processed by the speech decoder. The total response latency is the sum of these four stages.
Experiment
The evaluation framework validates the base model's capacity for speech-text interleaving and factual spoken question answering across both speech-to-speech and speech-to-text settings. Results show the model consistently outperforms baselines in spoken QA and significantly narrows the performance gap between modalities, indicating that direct speech-to-speech chatbots are highly viable despite text guidance remaining more accurate. The fine-tuned chat experiment further validates response correctness, speech naturalness, and cross-modal consistency, confirming the system's readiness for interactive conversational applications.
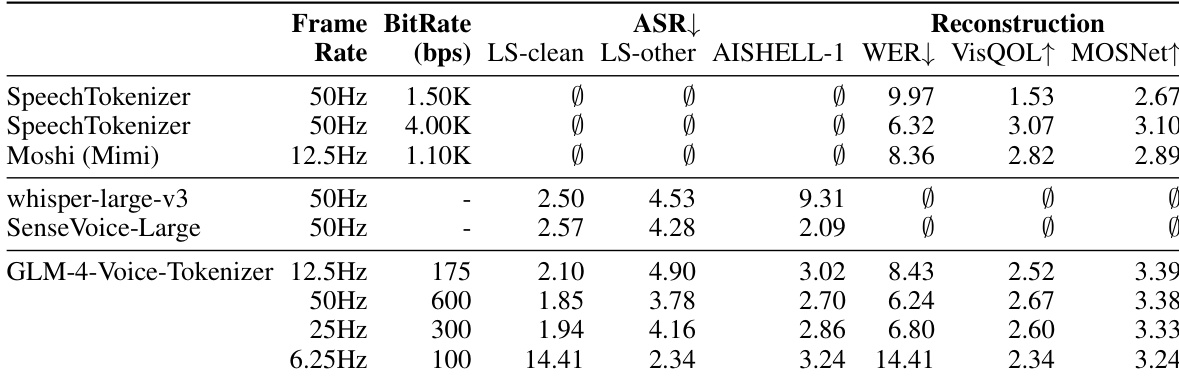
The authors evaluate the ASR and TTS capabilities of GLM-4-Voice using standard benchmarks for English and Chinese. Results show that GLM-4-Voice achieves competitive performance in both ASR and TTS tasks compared to established baselines, with notable differences in error rates across different datasets and modalities. The model demonstrates strong performance in TTS for English and Chinese, while its ASR performance varies depending on the dataset and language. GLM-4-Voice achieves competitive ASR and TTS performance compared to established baselines. The model shows higher error rates in ASR for English (LibriSpeech) than in TTS for English (LibriTTS). GLM-4-Voice performs better in TTS for Chinese (AISHELL-1) than in ASR for Chinese (Seed-TTS).
The authors evaluate the ASR and TTS performance of various models, including GLM-4-Voice-Tokenizer, across different frame rates and bitrates. Results show that GLM-4-Voice-Tokenizer achieves competitive or superior performance in reconstruction metrics compared to baselines like Whisper-large-v3 and SenseVoice-Large, particularly at lower frame rates and bitrates. The model's performance varies across different conditions, with some configurations showing better alignment between speech and text outputs. GLM-4-Voice-Tokenizer demonstrates competitive reconstruction performance compared to baseline models across various frame rates and bitrates. The model achieves improved performance in certain conditions, such as lower frame rates, where it outperforms other models in reconstruction metrics. Performance varies significantly with frame rate and bitrate, indicating sensitivity to these parameters in ASR and TTS tasks.
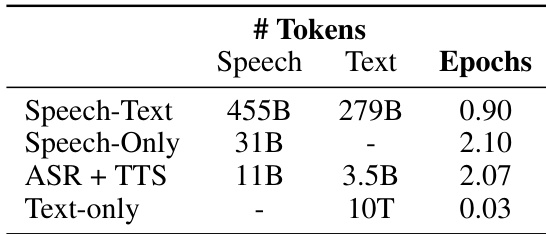
The authors present a comparison of different model configurations based on their training data and parameters. The configurations vary in the types of data used, such as speech-text, speech-only, and text-only, and differ in the number of tokens and training epochs. The results indicate that models trained with speech-text data require fewer tokens and epochs compared to those trained with speech-only or text-only data. Models trained on speech-text data use fewer tokens and epochs compared to speech-only or text-only models. The text-only configuration requires significantly more tokens and epochs than other configurations. Speech-only and ASR + TTS configurations have intermediate token and epoch counts, with ASR + TTS using more tokens than speech-only.
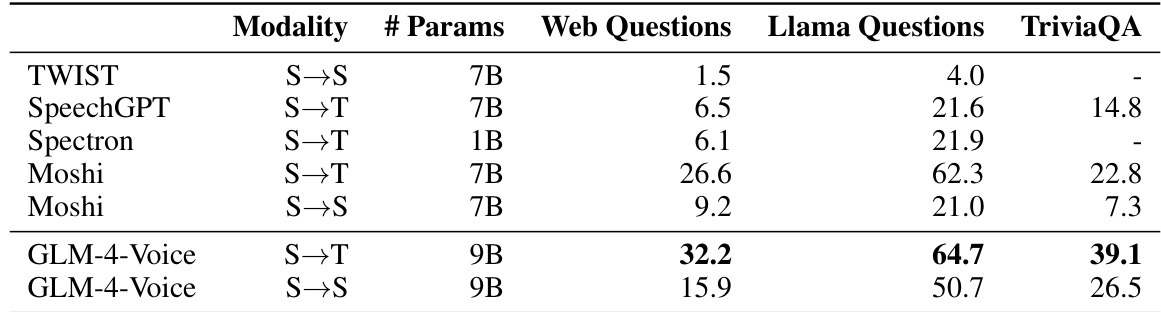
The authors evaluate the performance of GLM-4-Voice in spoken question answering tasks across different modalities and compare it with several baselines. Results show that GLM-4-Voice achieves higher accuracy than other models in both S→T and S→S settings, particularly excelling in the S→T setting and demonstrating improved performance on Llama Questions and TriviaQA compared to existing models. GLM-4-Voice outperforms baselines in spoken question answering across multiple datasets and modalities. The model achieves higher accuracy in the S→T setting compared to the S→S setting, indicating better performance with textual guidance. GLM-4-Voice shows significant improvements on Llama Questions and TriviaQA, especially in the S→T configuration.
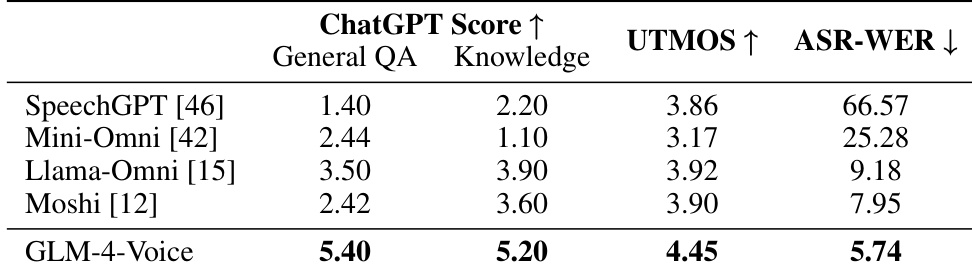
The authors evaluate the chat model performance using multiple metrics, including ChatGPT scores for general question answering and knowledge tasks, UTMOS for speech quality, and ASR-WER for speech-text alignment. The results show that GLM-4-Voice achieves the highest scores across all evaluated metrics compared to other models, demonstrating superior performance in both text and speech generation capabilities. GLM-4-Voice achieves the highest ChatGPT scores in both general QA and knowledge tasks. GLM-4-Voice shows the best speech quality with the highest UTMOS score. GLM-4-Voice has the lowest ASR-WER, indicating better alignment between generated speech and text responses.
The experiments evaluate GLM-4-Voice and its components across standard benchmarks for automatic speech recognition, text-to-speech synthesis, spoken question answering, and conversational dialogue. These tests validate the model's competitive performance against established baselines, its efficient training requirements when utilizing paired speech-text data, and its robust adaptability to varying audio compression parameters. The results consistently highlight superior cross-modal reasoning and conversational quality, demonstrating that the architecture effectively balances speech processing accuracy with natural interaction capabilities. Overall, the findings confirm GLM-4-Voice as a highly efficient and versatile voice model that excels in both acoustic tasks and end-to-end dialogue generation.