Command Palette
Search for a command to run...
كيف تؤثر خط أنابيب معالجة النصوص على مطابقة المفاهيم؟
كيف تؤثر خط أنابيب معالجة النصوص على مطابقة المفاهيم؟
Zhangcheng Qiang Kerry Taylor Weiqing Wang
نشر معالجة النصوص للمبتدئين بنقرة واحدة
الملخص
لم يتم توفير عنوان للورقة البحثية.
تتمثل خط أنابيب معالجة النصوص الكلاسيكي، الذي يشمل تجزئة النص (Tokenisation)، والتطبيع (Normalisation)، وإزالة كلمات التوقف (Stop Words Removal)، والجذرية/الإشتقاق (Stemming/Lemmatisation)، في كونه مُنفّذاً في العديد من الأنظمة الخاصة بمطابقة الأنطولوجيات (OM). ومع ذلك، فإن عدم وجود توحيد قياسي في معالجة النصوص يؤدي إلى تنوع في نتائج المطابقة. في هذه الورقة، نبحث في تأثير خط أنابيب معالجة النصوص على 8 مسارات من مبادرة تقييم محاذاة الأنطولوجيات (OAEI)، والتي تتضمن 49 محاذاة متميزة. نجد أن تجزئة النص والتطبيع (المصنّفةان كمرحلة أولى من معالجة النصوص) أكثر فعالية من إزالة كلمات التوقف والجذرية/الإشتقاق (المصنّفتان كمرحلة ثانية من معالجة النصوص). نقترح نهجين جديدين لإصلاح الخرائط الكاذبة غير المرغوب فيها التي تحدث في مرحلة معالجة النصوص الثانية. أحدهما نهج إصلاح قائم على المنطق مسبقاً (pre hoc) يُستخدم قبل معالجة النصوص، ويعتمد على فحص خاص بالأنطولوجيا للعثور على الكلمات الشائعة التي تسبب خرائط كاذبة. أما نهج الإصلاح الآخر فهو نهج قائم على نماذج اللغة الكبيرة (LLM) لاحقاً (post hoc)، يُستخدم بعد معالجة النصوص، والذي يستفيد من المعرفة الخلفية القوية التي توفرها نماذج اللغة الكبيرة لإصلاح الخرائط الكاذبة غير الموجودة وغير البديهية. تشير النتائج التجريبية إلى أن هذين النهجين يمكن أن يحسّنا بشكل كبير من دقة المطابقة والأداء العام للمطابقة.
One-sentence Summary
Investigating eight Ontology Alignment Evaluation Initiative (OAEI) tracks across 49 distinct alignments, this paper demonstrates that Phase 1 preprocessing steps (tokenisation and normalisation) outperform Phase 2 steps (stop word removal and stemming/lemmatisation) in ontology matching, and proposes two targeted repair strategies to mitigate Phase 2 false mappings: a pre-hoc logic-based approach that identifies problematic common words prior to preprocessing and a post-hoc large language model-based approach that leverages external knowledge to correct erroneous alignments, thereby significantly improving matching correctness and overall performance.
Key Contributions
- The paper systematically evaluates classical text preprocessing pipelines across eight OAEI tracks containing 49 distinct alignments, demonstrating that Phase 1 operations (tokenisation and normalisation) yield higher alignment quality than Phase 2 operations (stop word removal and stemming/lemmatisation).
- Two novel repair approaches are introduced to eliminate false mappings generated by Phase 2 preprocessing, featuring a pre hoc logic-based module that filters ontology-specific problematic terms before processing and a post hoc large language model-based module that corrects non-existent or counter-intuitive alignments using external knowledge.
- Experimental validation confirms that integrating these repair mechanisms significantly improves matching correctness and overall ontology alignment performance compared to standard preprocessing workflows.
Introduction
Ontology matching enables interoperability across heterogeneous knowledge graphs by aligning concepts from different ontologies, and text preprocessing serves as a computationally efficient foundation for this task. However, prior implementations of the classical preprocessing pipeline lack standardization, and systematic studies reveal that stop word removal and stemming or lemmatization frequently introduce false mappings due to over-processing and inappropriate filtering. The authors leverage a comprehensive evaluation across multiple ontology alignment benchmarks to demonstrate that early pipeline stages consistently outperform later ones. To address these weaknesses, they introduce a pre hoc logic-based validation step that filters problematic terms before processing and a post hoc large language model approach that corrects erroneous alignments after processing. Together, these methods significantly enhance matching accuracy while bridging traditional lexical techniques with modern reasoning capabilities.
Dataset
- Dataset Composition and Sources: The authors use 49 distinct ontology alignment benchmarks drawn from 8 OAEI tracks hosted in the MELT repository. Entity pairs are sourced from ontology classes and properties, with annotation labels substituted for non-textual identifiers.
- Subset Details and Filtering: The dataset focuses exclusively on equivalence mappings for classes and properties, intentionally excluding subsumption mappings due to limited ground truth availability. Entities containing more than 15 compound words are filtered out to maintain dataset balance.
- Data Usage and Evaluation: Rather than training models, the authors employ the data as a static benchmark to test text preprocessing pipelines. Alignment generation relies on a deterministic rule where preprocessed entity strings are compared for exact equality. Performance is measured against expert-validated reference alignments using Precision, Recall, and F1 scores, deliberately omitting Accuracy and Specificity due to the overwhelmingly large negative space in ontology matching.
- Processing and Metadata Construction: Each entity undergoes a standardized preprocessing pipeline comprising full-word tokenisation, normalisation, stop word removal, and stemming or lemmatisation. The tokenisation step preserves the exact order of compound words to ensure fair comparison. Normalisation applies lowercasing, HTML tag stripping, and punctuation handling while avoiding semantic-altering filters. Stop words follow the standard NLTK English list, while stemming and lemmatisation experiments test Porter, Snowball, Lancaster, and WordNet-based approaches with optional POS tagging.
Method
The authors leverage a context-based pipeline repair approach to address false positives (FPs) in ontology matching (OM) caused by text preprocessing methods. The overall framework involves a two-phase text preprocessing pipeline, where Phase 1 methods shift the alignment (A) closer to the reference (R), increasing true positives (TPs) and decreasing FPs. However, Phase 2 methods expand the alignment, increasing both TPs and FPs. The proposed repair strategy aims to collapse the alignment towards the reference, significantly reducing FPs with only a slight reduction in TPs. 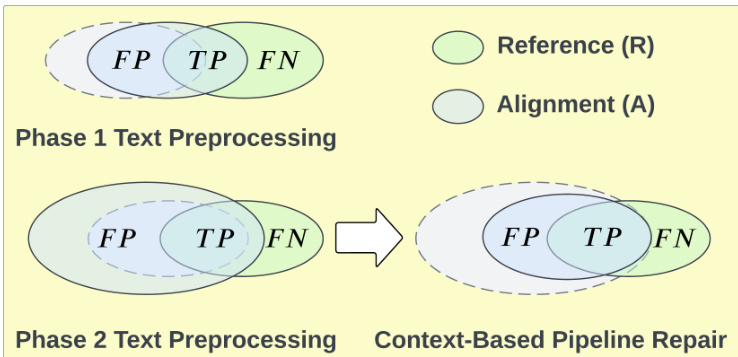
The core of the method is a pre hoc logic-based repair applied before text preprocessing. This approach constructs a reserved word set that prevents specific terms from being processed by the text preprocessing pipeline, thereby preserving distinctions between entities that would otherwise be conflated. The selection of reserved words is based on two ontology features: the uniqueness of entity names within a single ontology and the tendency for ontologies representing the same domain to use similar terminologies. Algorithm 1, as shown in the figure below, is used to generate this set. It first identifies pairs of entities in the source and target ontologies (O_s and O_t) that produce the same output under a given text preprocessing function f(·). For each such pair, the non-common words from their string representations are added to the reserved set. Subsequently, the algorithm removes any word from the reserved set that is immutable under the preprocessing function (i.e., f(w) = w), as these do not affect the mapping outcome. 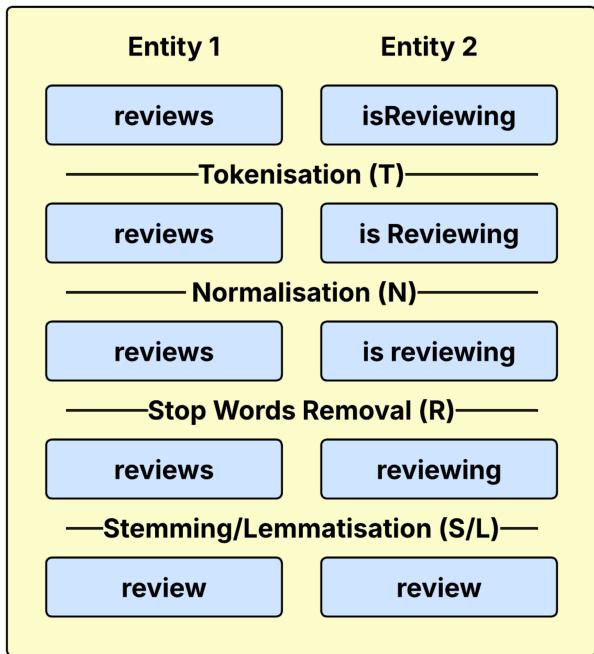
The framework for the overall matching process is illustrated in the diagram below. It begins by retrieving entities from the source and target ontologies. These entities undergo a sequence of text preprocessing steps: tokenisation (T), normalisation (N), stop words removal (R), and stemming or lemmatisation (S/L). The processed entities are then used to compute an alignment (A), which is compared against the reference (R) to evaluate matching performance. The context-based pipeline repair is integrated into this flow, specifically by applying the reserved word set during the preprocessing stages to modify the text representation of entities before alignment. 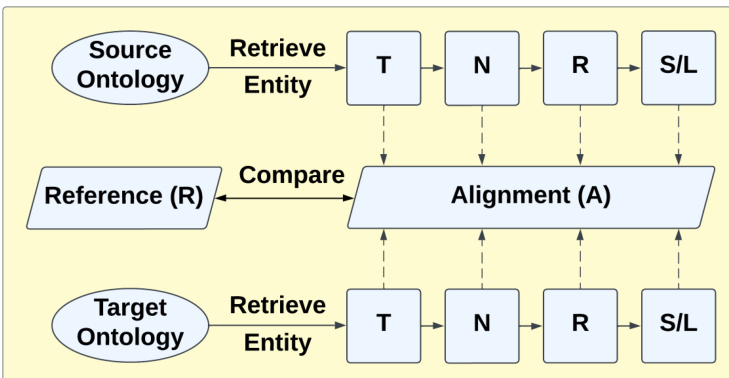
The effectiveness of this repair is demonstrated by a Venn diagram showing the relationship between false positives (FP), true positives (TP), and false negatives (FN) in the alignment and reference sets. The diagram illustrates how the pipeline repair reduces the FP region while maintaining the TP region, thereby improving the overall quality of the alignment. The process is visualized as a transition from Phase 1 and Phase 2 text preprocessing, which increase both TPs and FPs, to the context-based pipeline repair, which specifically targets and reduces FPs. 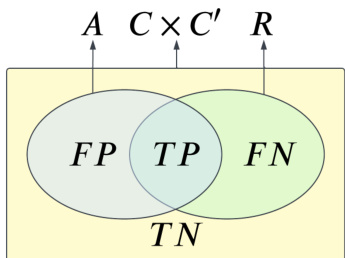
Experiment
This study evaluates a comprehensive ontology matching pipeline across multiple benchmark tracks, systematically analyzing the sequential impact of text preprocessing steps and testing various large language models with different prompting strategies. The experiments validate that initial tokenisation and normalisation consistently improve matching accuracy by preserving semantic meaning, whereas subsequent stop word removal and stemming techniques inadvertently increase false positives and degrade overall performance. To address these limitations, the research introduces and verifies two targeted repair approaches that combine deterministic preprocessing for true match detection with LLM-based validation to filter erroneous alignments. Ultimately, the findings demonstrate that integrating classical preprocessing with structured LLM correction significantly enhances precision and system robustness, establishing a more reliable workflow than purely prompt-driven methods.
The authors compare the performance of various LLMs and prompt strategies in detecting false mappings (FPs) in ontology matching tasks. Results show that API-accessed commercial LLMs generally achieve higher discovery rates for FPs compared to open-source models, and that more complex prompt strategies do not consistently improve performance. The classical text preprocessing pipeline achieves a high and stable discovery rate for FPs across different models and prompts. API-accessed commercial LLMs achieve higher discovery rates for false mappings than open-source models Complex prompt strategies do not consistently improve performance for detecting false mappings The classical text preprocessing pipeline provides a stable and high discovery rate for false mappings across different LLMs and prompts
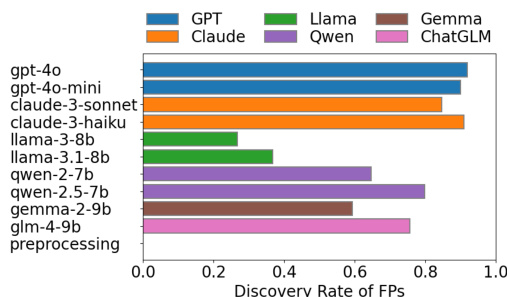
The authors compare the discovery rate of false positives (FPs) across various large language models (LLMs) and a classical text preprocessing pipeline. Results show that commercial API-accessed LLMs achieve higher discovery rates for FPs compared to open-source models, and that more complex prompting strategies do not consistently improve performance. The classical text preprocessing pipeline achieves a high and stable discovery rate, comparable to the best-performing LLMs. Commercial LLMs achieve higher discovery rates for false positives than open-source models. Complex prompting strategies do not consistently improve the discovery rate of false positives. The classical text preprocessing pipeline achieves a high and stable discovery rate for false positives, comparable to top-performing LLMs.
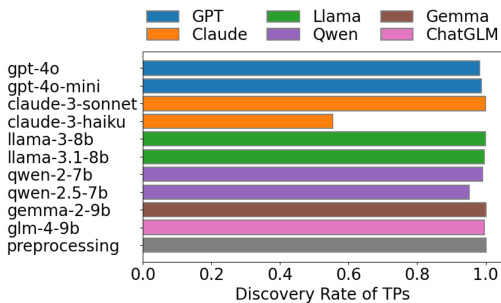
The authors compare the discovery rate of true mappings (TPs) across various large language models (LLMs) and a classical text preprocessing pipeline. Results show that the classical preprocessing method achieves a discovery rate close to 1.0, while LLMs exhibit varying performance, with some commercial models performing worse than open-source models. The discovery rate is influenced by both the LLM and the prompt strategy used. The classical text preprocessing pipeline achieves a discovery rate near 1.0 for true mappings, outperforming most LLMs. Commercial LLMs show lower discovery rates for true mappings compared to open-source models. Prompt strategies such as few-shot and self-reflection do not significantly improve or may even reduce the discovery rate of true mappings.
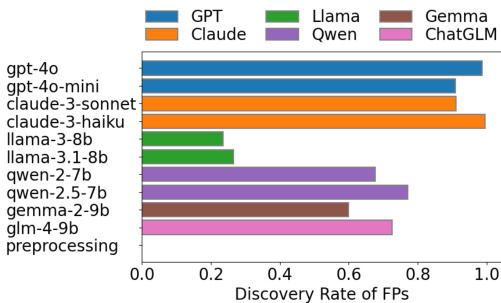
The authors compare the discovery rate of false positives (FPs) across various large language models (LLMs) and a classical text preprocessing pipeline. Results show that commercial API-accessed LLMs generally achieve higher discovery rates for FPs compared to open-source models, and that more complex prompting strategies do not consistently improve performance. The text preprocessing pipeline achieves a discovery rate close to the best-performing LLMs, indicating strong capability for identifying false mappings. Commercial LLMs achieve higher discovery rates for false positives compared to open-source models. Complex prompting strategies do not consistently improve false positive detection performance. The classical text preprocessing pipeline achieves a high discovery rate for false positives, comparable to the best-performing LLMs.
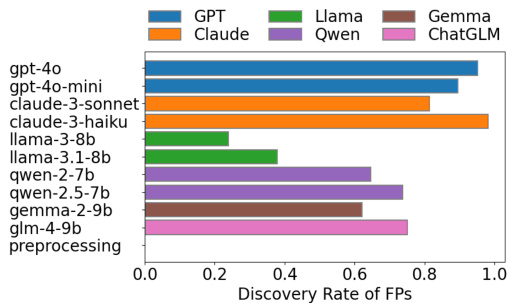
The authors compare the performance of various LLMs and prompt strategies in detecting true mappings (TPs) in ontology matching tasks. Results show that open-source LLMs generally outperform commercial API-accessed models in TP discovery, and that simple prompt strategies can be more effective than complex ones involving few-shot examples or self-reflection. The classical text preprocessing pipeline achieves near-perfect discovery rates across all models and prompts, indicating its reliability as a stable method for identifying TPs. Open-source LLMs achieve higher discovery rates for true mappings compared to commercial API-accessed models. Simple prompt strategies outperform complex ones involving few-shot examples and self-reflection in detecting true mappings. The classical text preprocessing pipeline consistently achieves near-perfect discovery rates across all LLMs and prompt strategies.
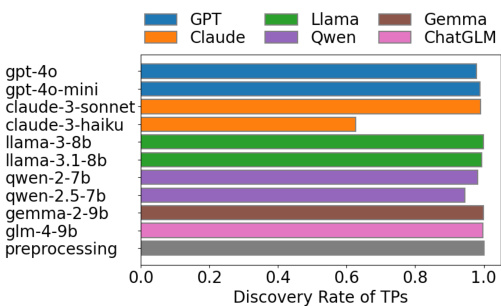
The experiments evaluate the detection of false and true mappings in ontology matching by comparing commercial and open-source large language models alongside various prompt strategies against a classical text preprocessing pipeline. The results indicate that commercial models generally excel at identifying false mappings, while open-source models perform better for true mappings, with complex prompting strategies offering no consistent advantage in either case. Ultimately, the classical preprocessing pipeline demonstrates superior stability and reliability, consistently matching or surpassing the best-performing LLMs across both evaluation tasks.