Command Palette
Search for a command to run...
Please provide the title you would like me to translate.
Please provide the title you would like me to translate.
كشف لغة الإشارة الأمريكية
الملخص
Please provide the title and abstract you would like me to translate.
One-sentence Summary
the paper introduce 3D-LEX v1.0, a dataset comprising 1,000 American Sign Language and 1,000 Sign Language of the Netherlands signs captured via high-resolution 3D poses, handshapes, and depth-aware facial features for semi-automatic phonetic annotation, where a straightforward handshape generation method improves gloss recognition accuracy by 5% over unannotated baselines and 1% over expert annotations in a sign recognition task.
Key Contributions
- Introduces an efficient 3D sign language capture pipeline that synchronizes high-resolution 3D poses, 3D handshapes, and depth-aware facial features to achieve an average sampling rate of one sign every 10 seconds.
- Presents the 3D-LEX v1.0 dataset comprising 1,000 signs each from American Sign Language and the Sign Language of the Netherlands, which is aligned with existing sign language benchmarks and linguistic resources.
- Details a semi-automatic annotation method for phonetic properties that generates handshape labels, demonstrating a 5% improvement in gloss recognition accuracy over unannotated baselines and a 1% improvement over expert annotations.
Introduction
Sign languages are complex visual systems that combine manual and non-manual markers to convey meaning, serving as the primary communication method for Deaf communities and a growing focus for computational linguistics and accessibility applications. Traditional lexical resources frequently fall short in capturing the full spatial dynamics of signs, which hinders the development of accurate sign language processing and translation systems. The authors leverage 3D modeling to introduce 3D-LEX v1.0, a comprehensive lexical database for American Sign Language and Sign Language of the Netherlands. This resource provides standardized spatial annotations that enable more precise computational analysis and support the creation of advanced sign language technologies.
Dataset
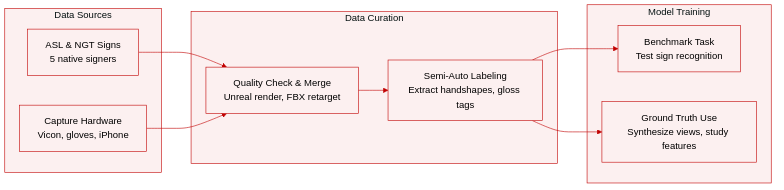
-
Dataset Composition and Sources
- The authors present 3D-LEX v1.0, a corpus of 2,000 isolated signs divided equally between American Sign Language and the Sign Language of the Netherlands.
- The selected vocabulary aligns with established benchmarks such as WLASL, SEMLEX, ASL-LEX 2.0, and SignBank NGT.
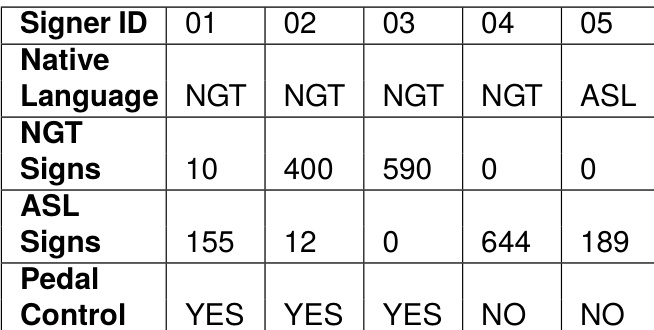
- All recordings originate from five native signers working in a controlled studio environment equipped with specialized motion capture hardware.
-
Subset Details
- Handshape Data: Captured using StretchSense Pro Fidelity gloves that measure finger splay, joint rotation, and sensor stretch values. The authors release raw sensor logs and exported FBX files.
- Body Pose Data: Recorded with a Vicon optical system featuring ten ceiling-mounted and two floor-mounted cameras. The authors provide raw marker coordinates alongside processed FBX animations generated through Shogun Post.
- Facial Features: Captured via an iPhone 13 Pro running Live Link Face and ARKit to extract facial blendshapes.
- Retargeted Animations: The authors combine processed body pose and handshape data into unified FBX files optimized for extended reality pipelines.
-
Data Usage and Processing
- The authors do not train a primary machine learning model on this dataset. Instead, they leverage it to benchmark a semi-automatic handshape annotation pipeline applied to the 1,000 ASL signs.
- These automatically derived labels are evaluated in an isolated sign recognition task, where they improve gloss recognition accuracy by 5 percent compared to unannotated baselines and by 1 percent over expert-provided labels.
- The dataset serves as a 3D ground truth resource for future research, enabling synthetic multi-view 2D data generation and detailed phonetic analysis rather than direct model training.
-
Cropping, Metadata, and Production Workflow
- Each sign is captured within a standardized 10-second window that encompasses demonstration, performance, and archiving.
- The authors implement an immediate quality control step where recordings are rendered as avatars in Unreal Engine for real-time visual verification before being saved to the SignCollect platform.
- Metadata includes unique signer identifiers to preserve anonymity, calibration pose logs for the StretchSense gloves, and synchronized timestamps across all three capture systems triggered by a triple-foot pedal interface.
- Post-processing involves retargeting raw Vicon markers to skeletal animations and extracting dominant handshapes from the glove sensor data for downstream linguistic annotation.
Method
The authors leverage a semi-automatic annotation framework to generate handshape labels from 3D sign data captured using StretchSense gloves, focusing on the ASL vocabulary within the 3D-LEX dataset. The overall approach is structured to produce annotations that align with those used in existing ISR benchmarks, enabling a direct comparison between automated and expert-derived labels. The method begins with temporal segmentation to isolate characteristic handshape signals from resting or transitional poses. This is achieved by computing the Euclidean distance of each frame’s hand pose relative to a set of calibration poses. The resulting distance values are used to identify and segment frames where a dominant handshape is present, effectively filtering out non-informative segments.

To determine the dominant handshape for each sign, the system calculates the frequency of each observed handshape across the segmented frames. The most frequent handshape is selected as the representative label, with a special case for the resting pose "5": if it occurs in more than 90% of the frames, it is retained as the label; otherwise, the second most frequent handshape is chosen. This process yields candidate frames for downstream analysis, which are then used for further annotation. Figure 5 illustrates the output of this Euclidean distance-based classification, showing how the handshape "o" is identified as the characteristic handshape for the sign "zero" through a time-series visualization of frame-by-frame classification results.

Recognizing the limitations of the Euclidean distance method—particularly its reliance on calibration poses that may not fully represent the lexicon’s diversity—the authors introduce a more flexible approach based on k-means clustering. After temporal segmentation, the average hand poses from the candidate frames are clustered into k=50 groups, corresponding to the approximate number of handshapes in the ASL-LEX vocabulary. Each sign is assigned a handshape label based on the cluster ID of its average pose, enabling a broader coverage of handshape variation. This clustering-based labeling allows for the generation of semi-automatic annotations without strict dependency on predefined calibration poses.
To evaluate the efficacy of these annotations, the authors employ an isolated sign recognition (ISR) task using the SL-GCN architecture trained on the WLASL benchmark, restricted to the subset overlapping with 3D-LEX. The model is trained to predict glosses under two conditions: with expert annotations from ASL-LEX and with the semi-automatic labels derived from the 3D-LEX data. The training process runs until validation accuracy plateaus for 30 consecutive epochs, using the splits detailed in Table 3. This setup enables a direct comparison of the performance of models trained with human-annotated versus automatically generated handshape labels.
The results demonstrate that the semi-automatic annotations achieve recognition accuracy comparable to that of expert annotations, indicating that the 3D-LEX handshape data, when processed through this pipeline, captures sufficient phonetic information to support downstream recognition tasks. This outcome suggests that high-resolution 3D sensor data can significantly reduce the need for manual linguistic annotation while maintaining the quality of phonetic labels. Figure 6 provides a t-SNE projection of the average hand poses, illustrating that the high-dimensional features naturally cluster into distinct groups, reinforcing the validity of the handshape labels and the discriminative power of the sensor data.