Command Palette
Search for a command to run...
ميج أكتور: تسخير قوة الفيديو الخام للرسوم المتحركة الحية للصور الشخصية
ميج أكتور: تسخير قوة الفيديو الخام للرسوم المتحركة الحية للصور الشخصية
Shurong Yang Huadong Li Juhao Wu Minhao Jing Linze Li Renhe Ji Jiajun Liang Haoqiang Fan
نشر MegActor بنقرة واحدة
الملخص
على الرغم من أن مقاطع الفيديو الخام للقيادة تحتوي على معلومات أكثر ثراءً حول تعابير الوجه مقارنةً بالتمثيلات الوسيطة مثل النقاط المرجعية (landmarks) في مجال تحريك الصور الشخصية، إلا أنها نادراً ما تكون موضوعاً للبحث. ويعود ذلك إلى تحديين متأصلين في تحريك الصور الشخصية المعتمدة على مقاطع الفيديو الخام: 1) تسرب هوية الوجه بشكل كبير؛ 2) تدهور الأداء بسبب تفاصيل الخلفية والوجه غير ذات الصلة، مثل التجاعيد. ولتسخير قوة مقاطع الفيديو الخام من أجل تحريك صور شخصية حيوية، اقترحنا نموذج انتشار مشروط رائداً يُدعى MegActor. أولاً، قدمنا إطار عمل لتوليد بيانات اصطناعية لإنشاء مقاطع فيديو ذات حركات وتعابير متسقة ولكن هويات (IDs) غير متسقة، وذلك للتخفيف من مشكلة تسرب الهوية. ثانياً، قمنا بفصل المقدمة والخلفية للصورة المرجعية، واستخدمنا نموذج CLIP لتشفير تفاصيل الخلفية. ثم تم دمج هذه المعلومات المشفرة في الشبكة عبر وحدة تضمين نصي، مما يضمن استقرار الخلفية. وأخيراً، قمنا بنقل النمط (style transfer) لمظهر الصورة المرجعية إلى فيديو القيادة للقضاء على تأثير تفاصيل الوجه في مقاطع الفيديو القيادية. تم تدريب نموذجنا النهائي باستخدام مجموعات بيانات عامة فقط، وحقق نتائج قابلة للمقارنة مع النماذج التجارية. نأمل أن يساهم ذلك في مساعدة مجتمع المصدر المفتوح.
One-sentence Summary
MegActor is a conditional diffusion model that generates vivid portrait animations from raw driving videos by leveraging a synthetic data framework that creates videos with consistent motion and expressions but inconsistent identities to mitigate identity leakage, integrating CLIP-encoded background segmentation via text embeddings to stabilize the background, and applying appearance style transfer from the reference image to the driving video to eliminate distracting facial details, ultimately achieving performance comparable to commercial models while trained exclusively on public datasets.
Key Contributions
- This work introduces MegActor, a conditional diffusion model that generates portrait animations from raw driving videos by employing a synthetic data generation framework to decouple motion control from subject identity and mitigate identity leakage.
- Robustness to irrelevant background and facial details is achieved through a background segmentation and CLIP encoding module, combined with a style transfer process that maps the reference appearance onto the driving frames to filter out visual noise.
- Trained exclusively on public datasets, the framework achieves animation quality and identity preservation comparable to commercial models, as demonstrated through SOTA comparisons and visual evaluations.
Introduction
Portrait animation enables the transfer of motion and facial expressions from a driving video to a target image while preserving identity and background, powering applications like digital avatars and AI-driven conversations. While recent diffusion-based approaches using text, image, or audio controls have improved visual quality, they struggle with subtle facial movements, rely on unstable external pose detectors, or suffer from identity leakage when trained on raw video data. To overcome these bottlenecks, the authors introduce MegActor, a conditional diffusion model that directly harnesses raw driving videos for highly expressive portrait animation. They address identity leakage through a custom synthetic data framework that decouples motion from appearance, stabilize background generation using CLIP-encoded text embeddings, and apply stylization transfer to filter out irrelevant facial details from the driving footage. This approach delivers robust, pixel-level accurate animations that match state-of-the-art commercial systems while relying solely on publicly available training data.
Dataset
- Dataset Composition and Sources: The authors train the model using publicly available video datasets, specifically VFHQ and CelebV-HQ. To address identity and background leakage, they supplement these real videos with synthetically generated data created via Face-Fusion and SDXL.
- Subset Details and Filtering: The real data originates from VFHQ and CelebV-HQ. The synthetic subsets include AI face-swapping videos generated by pairing each driving frame with a source image from a different individual, and stylized videos produced with SDXL. The authors also apply L2CSNet to measure gaze shifts across frames, isolating approximately 5 percent of the data that exhibits significant eye movements for specialized fine-tuning.
- Training Usage and Mixture Ratios: During the initial training stage, the model consumes a blended mixture of 50 percent real videos, 40 percent AI face-swapping videos, and 10 percent stylized videos. The authors sample frames using a stride of 2 to create 16-frame segments, where one frame serves as the reference and the remaining frames act as both the driving input and ground truth. In the second stage, the model fine-tunes exclusively on the high-gaze subset using a stride of 12 while maintaining the 16-frame segment length.
- Processing and Augmentation Strategies: To minimize background leakage, the authors use pyFacer to detect faces and mask all non-facial pixels to black. They also apply random augmentations to the driving videos, including grayscale conversion and adjustments to size and aspect ratio, which modify facial structure without altering expressions or head poses. All video frames are resized to 512 by 512 pixels before training.
Method
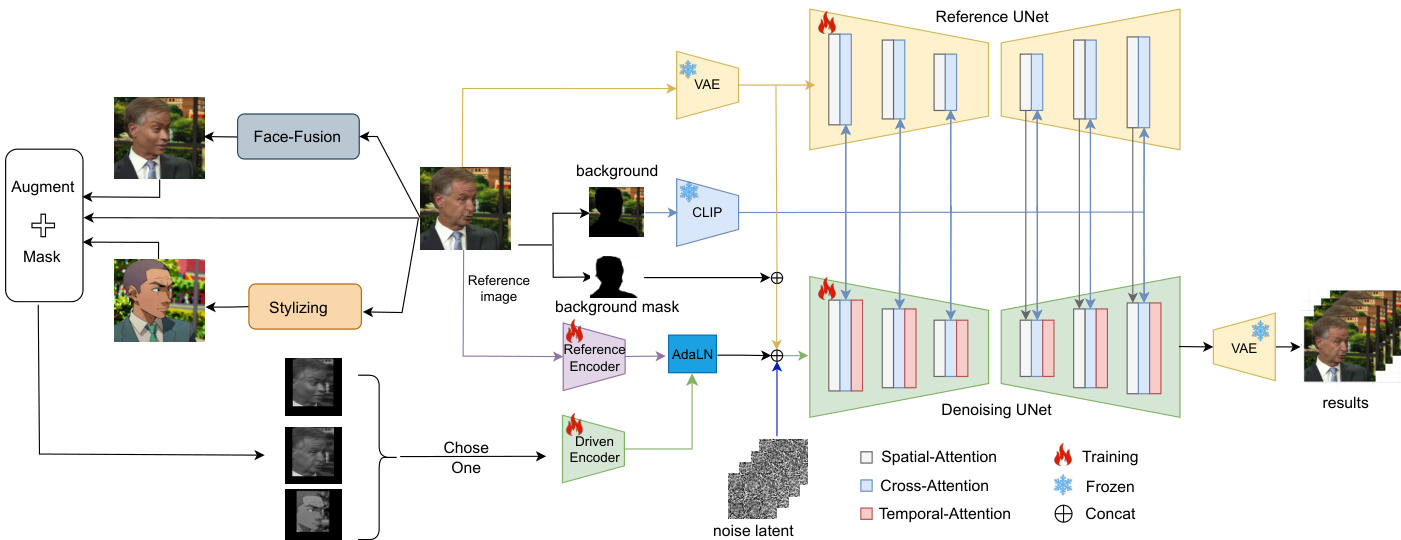
The authors leverage a conditional diffusion model architecture, referred to as MegActor, to achieve vivid portrait animation driven by raw video inputs. The overall framework is designed to address two primary challenges in using raw driving videos: identity leakage and the degradation of performance due to irrelevant background and facial details. The system operates by first processing the reference image and the driving video through distinct pipelines before integrating their features into a unified denoising process.
The reference image is processed to extract identity and background information. A ReferenceNet, based on the UNet architecture of Stable Diffusion 1.5 (SD1.5), is used to encode fine-grained identity and background features. Concurrently, the background region of the reference image is isolated and encoded using CLIP’s image encoder. This encoded background information is then integrated into the model via a text embedding module, replacing the standard text prompt. The extracted global (CLS) and local patch features from CLIP are merged and injected into both the ReferenceNet and the Denoising UNet through cross-attention mechanisms to stabilize the background in the generated output.
For the driving video, a lightweight DrivenEncoder is employed to extract motion features. This encoder consists of four 2D convolutional layers with varying channel sizes and is designed to efficiently process the video frames. The motion features are aligned to the resolution of the noise latents sampled from the diffusion process. To preserve the spatial structure of the pre-trained Denoising UNet, the authors initialize the parameters of the newly added channels in the conv-in layer to zero. The DrivenEncoder is further enhanced by incorporating the reference image as a guide during motion feature extraction. The latent representation of the reference image, obtained via a Variational Autoencoder (VAE), and a foreground mask derived from DensePose are concatenated with the noise latents and motion features before being fed into the Denoising UNet. This ensures that the motion transfer respects the identity of the reference character.
To improve temporal consistency across generated frames, a temporal module is inserted after each Res-Trans layer of the Denoising UNet. This module performs temporal attention between frames, capturing temporal dependencies and enhancing continuity in the animation. The temporal module is fine-tuned separately to optimize its performance without disrupting the pre-trained image generation capabilities of the base model.
The driving video undergoes preprocessing to mitigate identity leakage. A synthetic data generation framework is employed, where face-swapping and stylization techniques are applied to create videos with consistent motion and expressions but inconsistent identities. The stylized video is used during training to reduce the influence of facial details such as wrinkles. Additionally, data augmentation methods, including scaling and aspect ratio adjustments, are applied to the driving video. All non-face regions are masked out to focus the model on the facial motion.
Experiment
The evaluation validates cross-identity portrait generation by animating distinct reference frames using driving videos from multiple datasets. Initial tests on independent video sources confirm that the model accurately preserves background details and subject identity while faithfully transferring complex facial expressions and subtle head movements. A comparative assessment against a state-of-the-art baseline further highlights superior clarity in fine anatomical features and demonstrates overall animation quality on par with leading methods. These qualitative results collectively establish the model's robust generalization and competitive standing in cross-identity animation tasks.
The authors evaluate their model, MegActor, in comparison to existing methods using cross-identity video generation tasks. The results demonstrate that MegActor produces realistic portrait animations with preserved identity and detailed facial features, achieving comparable performance to state-of-the-art methods while supporting open code and weights. MegActor generates realistic portrait animations with preserved identity and detailed facial expressions under cross-identity conditions. MegActor achieves comparable results to state-of-the-art methods, producing clearer outputs in areas like teeth compared to EMO. MegActor supports open code and weights, unlike several other models listed in the comparison.
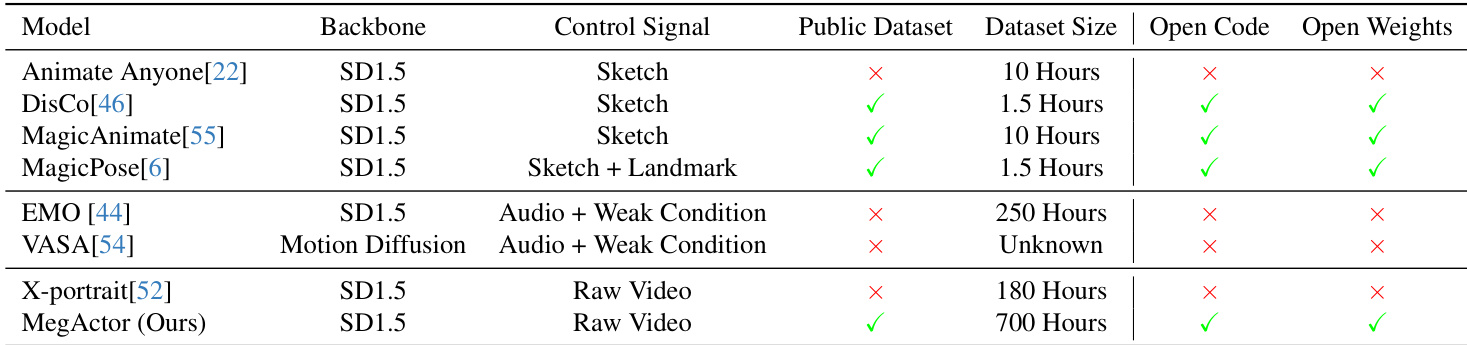
The authors evaluate MegActor through cross-identity video generation tasks to validate its capacity for producing realistic portrait animations that maintain subject identity and fine facial details. Qualitative assessments confirm that the model successfully preserves identity and renders expressive features with clarity that aligns with or exceeds existing state-of-the-art methods. Additionally, the framework establishes a new standard for accessibility by releasing fully open code and weights alongside its competitive performance.