Command Palette
Search for a command to run...
نمذجة اللغة المقنعة
الملخص
Please provide the title and abstract you would like me to translate.
One-sentence Summary
This study systematically evaluates subword tokenization strategies for French biomedical masked language models across various NLP tasks to determine how segmentation granularity, data sources, and morphological information influence token consistency and task performance.
Key Contributions
- The paper introduces a morpheme-enriched tokenization strategy for the French biomedical domain that integrates manually defined linguistic morphemes into statistical algorithms such as Byte-Pair Encoding and SentencePiece to standardize the segmentation of agglutinative terminology.
- It systematically evaluates the alignment between statistical tokenizers and actual linguistic word boundaries while investigating how tokenization granularity impacts performance across diverse downstream tasks.
- The study delivers comprehensive qualitative and quantitative benchmarks across 23 French biomedical NLP tasks, including named entity recognition and semantic textual similarity, to demonstrate how morpheme-enriched tokenization and training data sources influence BERT-based language models.
Introduction
Subword tokenization has become the standard approach in natural language processing, enabling pre-trained language models to efficiently manage out-of-vocabulary terms and boost performance across diverse applications. Despite its widespread adoption, the underlying mechanics of its success remain poorly understood, particularly regarding optimal segmentation granularity and the systematic exclusion of linguistic structure. In specialized fields like French biomedicine, terminology relies on strict agglutinative rules derived from classical roots, yet conventional statistical tokenizers disregard this morphological knowledge, producing arbitrary and inconsistent word splits that hinder model accuracy. To bridge this gap, the authors introduce a morpheme-enriched tokenization strategy that embeds manually defined linguistic units directly into standard statistical algorithms. By evaluating this approach across twenty-three French biomedical NLP tasks, they demonstrate how rule-based segmentation improves token consistency and provide actionable insights into the relationship between linguistic granularity and downstream model performance.
Dataset
-
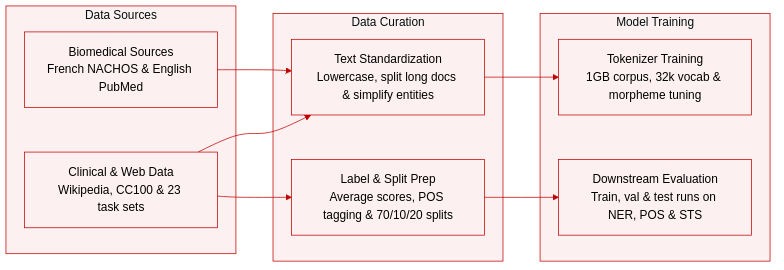
Dataset composition and sources: The authors evaluate their models using 23 downstream NLP tasks from the DrBenchmark suite, focusing on French biomedical and clinical text. The data spans clinical cases, drug labels, biomedical abstracts, clinical trial protocols, and spoken prescription dialogues. For tokenizer training, they curate a 1GB raw text corpus combining French biomedical content (NACHOS), English biomedical literature (PubMed Central), general French text (French Wikipedia), and multilingual web text (CC100).
-
Key details for each subset: DEFT-2020 provides 1,010 sentence pairs for semantic textual similarity and 1,102 samples for multi-class classification. DEFT-2021 contains 275 clinical cases that yield 4,712 multi-label classification samples across 23 MeSH axes and NER annotations for 13 entities. E3C offers 1,402 French clinical cases annotated for clinical entities, temporal information, and factuality. QUAERO covers drug leaflets and biomedical titles with 26,409 entities mapped to 5,797 UMLS concepts. MorFITT includes 3,624 PMC Open Access abstracts with multi-label annotations across 12 medical specialties. Mantra-GSC focuses on the French subset of EMEA, Medline, and patent documents for biomedical NER. CLISTER comprises 1,000 sentence pairs with averaged similarity scores ranging from 0 to 5. CAS contains 3,790 clinical cases with automatic POS tagging across 31 classes and negation markers. ESSAI provides 7,247 clinical trial protocols with automatic POS tagging across 41 classes. PxCorpus features 1,981 transcribed dialogue recordings spanning 4 hours for intent classification across 4 classes and NER across 38 classes.
-
Data usage and splits: The authors apply these datasets strictly for downstream task evaluation rather than model pretraining. Where predefined splits are unavailable, they randomly partition the data into 70 percent training, 10 percent validation, and 20 percent testing sets. The tokenizer training mix uses the curated 1GB corpus to generate 16 distinct tokenizers, each configured with a 32k vocabulary size and balanced between morpheme-integrated and standard algorithms.
-
Processing and cropping strategies: The authors standardize the tokenizer corpus by converting all text to lowercase. For QUAERO, they simplify nested entity annotations to the highest granularity level, which removes approximately 6 to 9 percent of annotations, and split lengthy EMEA documents into sentences to respect model input limits. CLISTER similarity scores are averaged across multiple annotators to produce continuous float values. POS tagging for CAS and ESSAI relies on the Tagex and TreeTagger tools respectively, achieving high precision against manual gold standards.
Method
The authors leverage two statistical-based tokenization methods, Byte Pair Encoding (BPE) and SentencePiece, as foundational approaches for subword segmentation. BPE operates by starting with individual characters and iteratively merging the most frequent pairs of subwords into larger units based on their occurrence in the training corpus. This process results in a vocabulary that prioritizes high-frequency combinations, enabling efficient representation of common word forms. In contrast, SentencePiece supports two distinct segmentation algorithms—Unigrams and BPE—allowing for greater flexibility in controlling the granularity of subword units. While SentencePiece has gained traction in French biomedical NLP, its effectiveness may vary depending on the language and domain, potentially leading to suboptimal tokenization outcomes.
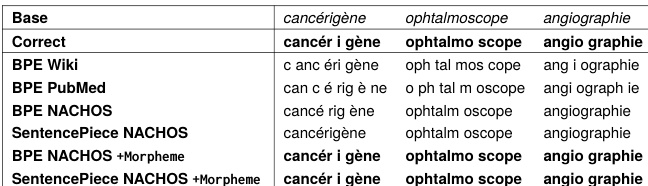
To enhance the modeling of specialized medical terminology and mitigate the challenge of unseen words during pre-training, the authors introduce a novel morpheme-enriched tokenization strategy. This approach integrates linguistic knowledge by incorporating a manually curated list of approximately 600 lexical morphemes commonly found in the French medical domain, drawn from established sources such as Cottez (1980). Examples of such morphemes include céphal-, clinico-, -thérapie, thoraco-, -ome, and -gène. These morphemes are treated as fixed token units during the tokenization process.

As shown in the figure below, the morpheme-enriched tokenization framework modifies both BPE and SentencePiece algorithms by enforcing the inclusion of predefined morpheme tokens. During training, when the tokenizer encounters a morpheme from the curated list, it treats it as a single token rather than decomposing it further. For the remaining text, the standard subword segmentation procedure of the chosen algorithm—either BPE or SentencePiece—is applied. This hybrid strategy enables the preservation of meaningful morphological units while maintaining the adaptability of statistical tokenization methods, thereby improving the representation of medical terminology and reducing the impact of out-of-vocabulary words.
Experiment
The evaluation framework assesses French biomedical language models across twenty-three downstream tasks using standardized fine-tuning protocols to isolate the effects of tokenization strategies. Experiments validating tokenization granularity demonstrate that coarser segmentation generally yields higher performance, particularly for context-sensitive tasks, while those assessing morpheme enrichment reveal that explicit linguistic rules improve segmentation accuracy without consistently boosting downstream results due to the model's inherent robustness. Finally, tests on training data sources confirm that corpora aligned with the target language outperform linguistically mismatched domain-specific data by preventing token sparsity and excessive over-segmentation.
The authors describe an experiment evaluating tokenization strategies for French biomedical language models, using a consistent training and evaluation protocol across multiple tasks. Results show that the choice of training data significantly impacts performance, with some data sources outperforming others despite not being domain-specific, and that the effect of morpheme enrichment varies across tasks and models. Performance varies significantly depending on the training data source, with non-domain-specific data sometimes outperforming domain-specific data. The introduction of morphemes does not consistently improve model performance across all tasks and tokenization strategies. There is a general trend where higher performance correlates with fewer subword units, particularly for certain types of tasks like sequence-to-sequence and STS.

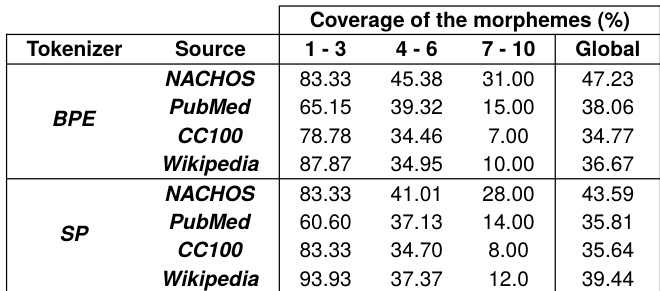
The authors analyze the coverage of morphemes in tokenizers trained on different data sources, focusing on how tokenization strategies and data selection affect morpheme representation. The the the table shows that tokenizers trained on NACHOS and Wikipedia exhibit higher morpheme coverage, particularly for shorter morphemes, while CC100 and PubMed result in lower coverage across all length ranges. These differences in morpheme representation are linked to the linguistic and domain-specific characteristics of the training data. Tokenizers trained on NACHOS and Wikipedia show higher morpheme coverage compared to those trained on PubMed and CC100. Morpheme coverage decreases significantly for longer morphemes, especially in tokenizers trained on PubMed and CC100. BPE and SentencePiece show similar trends in morpheme coverage, with variations depending on the training data source.
The authors evaluate the impact of tokenization strategies on French biomedical language models using a variety of downstream tasks. Results show that performance varies significantly across tasks and tokenization methods, with no single strategy consistently outperforming others, and that the choice of training data has a substantial influence on model outcomes. Performance varies across tasks and tokenization methods, with no single strategy consistently achieving the best results. The choice of training data significantly affects model performance, with domain-relevant data often outperforming domain-specific but language-mismatched data. Introducing morphemes into tokenizers improves segmentation quality but does not consistently lead to better downstream task performance.
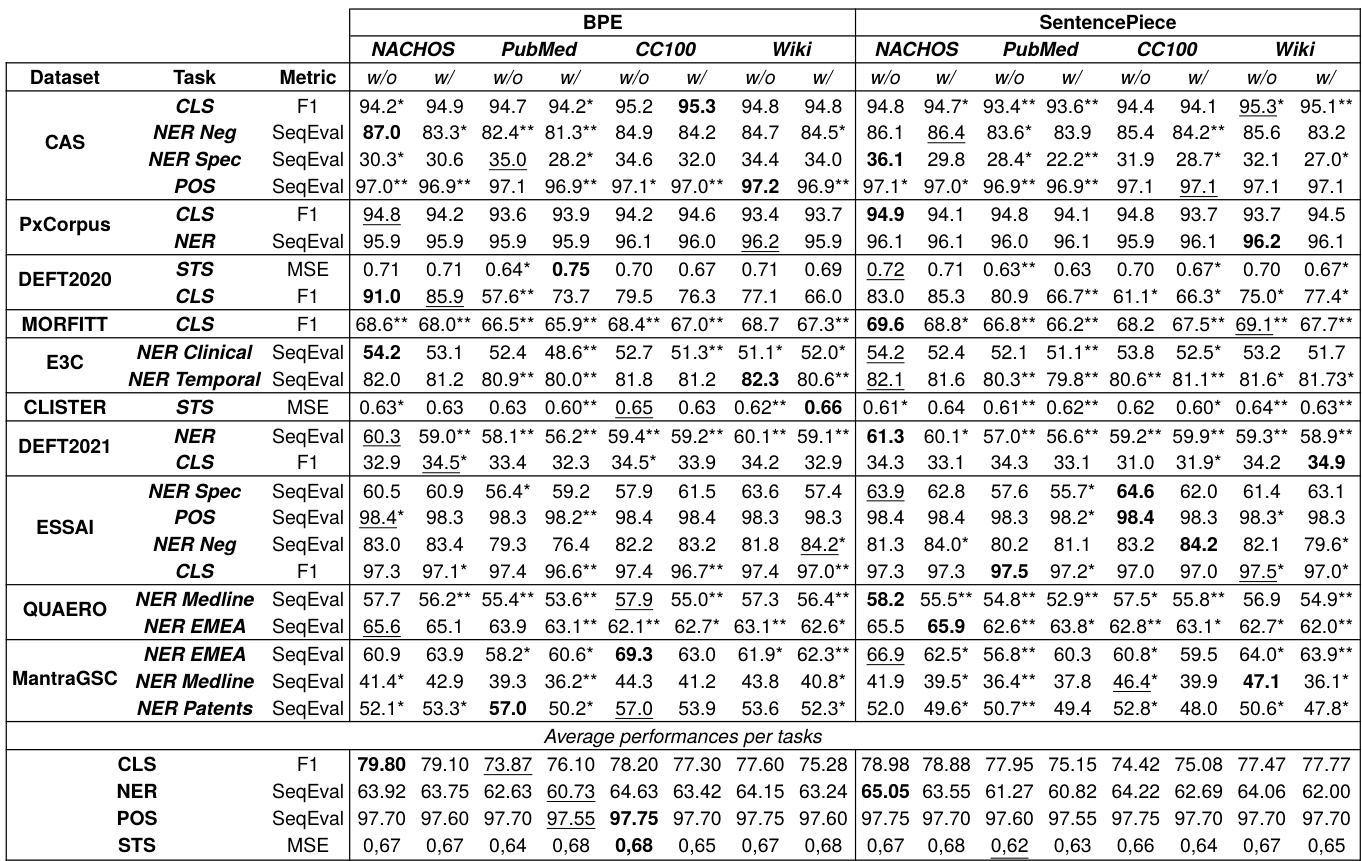
The authors evaluate the impact of tokenization strategies on French biomedical language models, focusing on the influence of tokenization granularity, morpheme enrichment, and data sources. Results show that while morpheme-enriched tokenizers improve segmentation accuracy, they do not consistently lead to better downstream performance, and the choice of training data significantly affects model outcomes. The best results are achieved with classical statistical tokenizers trained on domain-specific data, even without morpheme enrichment. Morpheme enrichment improves segmentation accuracy but does not consistently enhance downstream task performance. Tokenization granularity correlates with model performance, with fewer subword units generally associated with higher scores. Training data source has a significant impact, with domain-specific data outperforming cross-lingual sources despite potential over-segmentation issues.
The authors conduct an experiment to evaluate the impact of tokenization strategies on French biomedical language models, focusing on the influence of tokenization granularity, morphological information, and data sources. The results show that performance varies significantly across tasks and tokenization methods, with no single strategy consistently outperforming others. The study also investigates the effect of freezing different components of the model during fine-tuning, revealing task-specific dependencies on embeddings and the encoder. Performance varies across tasks and tokenization methods, with no consistent best strategy. Freezing the encoder has a greater impact on tasks like POS tagging and STS, indicating stronger context dependency. Tokenization granularity correlates with performance, where fewer subword units are generally associated with higher scores.
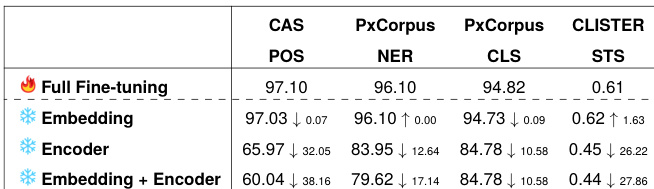
The experiments evaluate various tokenization strategies, including morpheme enrichment and subword granularity, across multiple downstream tasks to assess their impact on French biomedical language models. Results indicate that the choice of training data substantially influences model outcomes, with domain-specific corpora generally yielding superior performance despite occasional advantages from non-domain sources. While morpheme enrichment consistently enhances segmentation accuracy, it does not reliably improve downstream task performance, and coarser tokenization with fewer subword units typically correlates with higher scores. Additionally, fine-tuning analyses reveal task-specific dependencies on frozen model components, confirming that no single tokenization strategy universally optimizes results across all biomedical NLP applications.