Command Palette
Search for a command to run...
كشف الكمامة باستخدام باي توتش
الملخص
Please provide the title and abstract you would like me to translate.
One-sentence Summary
Addressing limited training data during the pandemic, this study benchmarks three object detection architectures (SSD, YOLOv4-tiny, and YOLOv4-tiny-3l) for real-time face mask detection, ultimately selecting YOLOv4-tiny for real-world and mobile applications and achieving 85.31% mean Average Precision and 50.66 frames per second on a two-dataset collection of 1,531 images across three classes.
Key Contributions
- This study evaluates three state-of-the-art object detection architectures, specifically SSD, YOLOv4-tiny, and YOLOv4-tiny-3l, to establish an effective framework for real-time face mask compliance monitoring. The comparative analysis addresses the deployment constraints of running health surveillance systems on resource-limited mobile devices.
- Systematic performance evaluation identifies YOLOv4-tiny as the optimal architecture for practical deployment, enabling accurate classification of individuals into three categories: wearing a mask correctly, wearing no mask, and wearing a mask improperly.
- The selected model achieves 85.31% mean Average Precision and 50.66 frames per second using a combined dataset of only 1,531 images, demonstrating viable real-time detection capabilities in crowded environments despite limited training data availability.
Introduction
Automated face mask detection has become a critical tool for enforcing public health protocols in crowded or restricted environments, replacing error-prone manual surveillance with real-time computer vision. However, prior research has struggled with obscured facial landmarks, limited or synthetically generated datasets, class imbalances, and models that either lack real-time speed or demand excessive computational resources. The authors leverage three state-of-the-art object detection architectures to address these constraints, ultimately identifying YOLOv4-tiny as the optimal solution. By training on a compact dataset of 1,531 images across three compliance categories without preprocessing, their approach achieves a practical balance of 85.31 percent mean Average Precision and 50.66 frames per second, enabling efficient deployment on mobile and edge devices.

Dataset
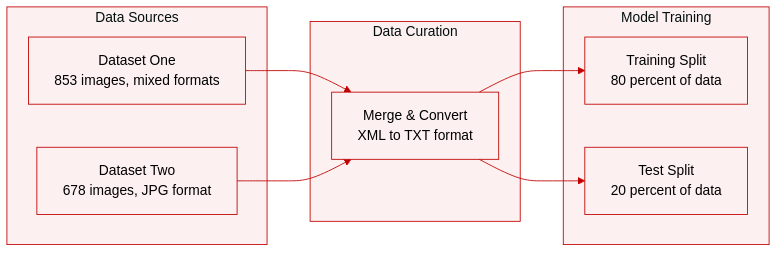
- Dataset Composition and Sources: The authors combine two external image collections to create a unified library for mask detection, resulting in a mixed format set containing both JPG and PNG files across three categories: correct mask, no mask, and incorrect mask.
- Subset Details: The first source contributes 853 images in PNG, JPG, and JPEG formats, featuring diverse scenarios that range from single individuals to crowded environments. The second source adds 678 JPG images covering the same three classification labels.
- Processing and Metadata Construction: Original XML annotation files containing image dimensions and bounding box coordinates are converted into TXT format to ensure compatibility with YOLO and SSD object detection architectures. The coordinate metadata is standardized to track top right and bottom left corners for each detected person.
- Training Strategy and Data Usage: The merged collection is partitioned into an 80 percent training split and a 20 percent test split. The authors highlight a notable class imbalance in the final instance distribution, with 6322 examples labeled as wearing a mask, 1377 without, and 247 classified as wearing an incorrect mask.
Method
The authors leverage the YOLO (You Only Look Once) family of object detection models, which were introduced to accelerate real-time object detection by treating it as a regression problem rather than a classification task. The foundational YOLO model, developed by Redmon et al. in 2016, was later improved by SSD (Single Shot MultiBox Detector), which achieved higher accuracy and speed. Since then, multiple versions of YOLO have been released, each enhancing both accuracy and inference speed. Among these, YOLO-tiny variants are designed to be lighter by reducing the number of convolutional layers, thereby increasing speed at the cost of accuracy. However, in scenarios with limited training data, YOLO-tiny may outperform standard YOLO due to reduced complexity and overfitting risk.
To address the challenge of detecting small objects, YOLOv3 introduced multi-scale detection, utilizing three feature map scales and nine anchor boxes per grid cell. In contrast, YOLOv3-tiny uses only two scales and six anchor boxes, resulting in a trade-off between speed and accuracy. The authors reference the architectural differences between these variants, noting that YOLOv3-tiny achieves 33.2% mean Average Precision (mAP) on the COCO dataset while running 11 times faster than YOLOv3.

Experiment
The evaluation utilized a diverse dataset of indoor and outdoor scenes to test YOLOv4-tiny variants and SSD models across varying crowd densities, lighting conditions, and ethnicities, validating their real-world generalization capabilities. A dedicated ablation experiment merging detection classes confirmed that maintaining three distinct categories significantly enhances model robustness compared to binary classification. Additionally, comparative trials against prior architectures demonstrated that the proposed lightweight approach eliminates extensive preprocessing while delivering superior accuracy and inference speed over heavier alternatives. Ultimately, the findings confirm that the optimized model effectively balances computational efficiency with reliable detection performance, making it highly suitable for practical deployment in diverse surveillance environments.
The authors compare their proposed method with existing approaches for face mask detection, highlighting that their model achieves a higher mAP while maintaining a low computational cost and real-time performance. The study emphasizes the importance of using a three-class classification system and demonstrates robustness across different image conditions, even with a limited dataset. Results show that the proposed method outperforms several prior works in terms of accuracy and efficiency, particularly in real-world applications. The proposed method achieves higher mAP compared to existing approaches while maintaining real-time performance and low computational cost. The use of a three-class classification system improves model robustness and accuracy over two-class alternatives. The proposed method demonstrates strong performance on real-world data despite using a limited dataset and is suitable for deployment in mobile and surveillance applications.
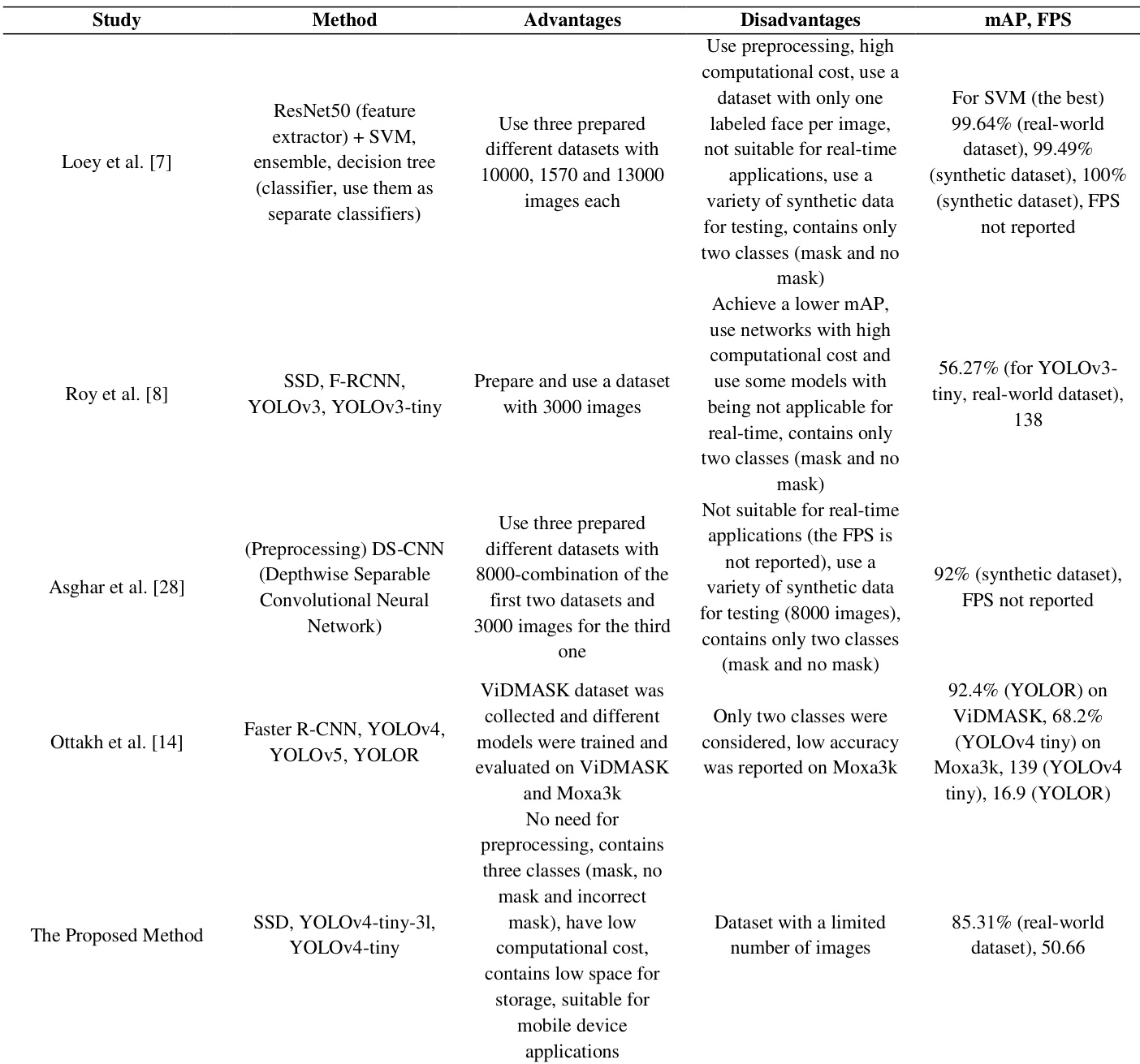
The authors compare the performance of three object detection models on a face mask detection task, focusing on speed and accuracy. Results show that the YOLOv4-tiny model achieves the highest speed among the tested models, while also demonstrating strong accuracy, particularly in detecting the incorrect mask class. The models are evaluated on a dataset with limited size and diversity, yet they maintain robust performance across different scenarios, including real-world conditions. The YOLOv4-tiny model achieves the highest speed among the tested models. The YOLOv4-tiny model shows better performance on the incorrect mask class compared to other models. All models achieve speeds suitable for real-time applications, with YOLOv4-tiny being the fastest.

The authors compare the performance of YOLOv4-tiny-3l, YOLOv4-tiny, and SSD models on a face mask detection task, focusing on their ability to classify three classes: incorrect mask, with mask, and without mask. Results show that YOLOv4-tiny achieves the highest average precision across all classes, particularly for the incorrect mask category, while SSD performs the worst. The models are evaluated in terms of both accuracy and speed, with YOLOv4-tiny being the fastest and suitable for real-time applications. The study emphasizes the importance of using a multi-class approach and demonstrates that the models generalize well to different populations despite dataset limitations. YOLOv4-tiny outperforms both YOLOv4-tiny-3l and SSD in average precision, especially for the incorrect mask class. The SSD model shows the lowest performance across all classes, particularly failing to detect the incorrect mask class. YOLOv4-tiny achieves the highest speed, making it suitable for real-time surveillance applications.
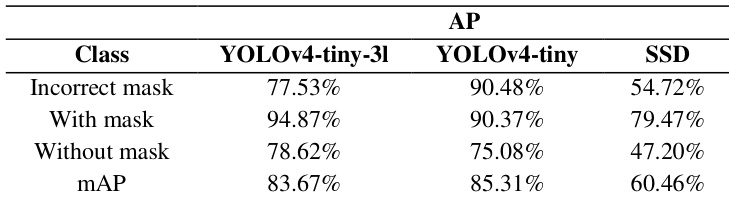
The authors evaluate the performance of YOLOv4-tiny-3l on a face mask detection task, reporting average precision for different classes. The model achieves high precision for the 'with mask' class and lower precision for the 'without mask' class, resulting in a moderate mAP. The results indicate that the model performs well on the given dataset, particularly for detecting masks that are properly worn. YOLOv4-tiny-3l achieves high average precision for the 'with mask' class. The model shows lower average precision for the 'without mask' class compared to the 'with mask' class. The overall mAP indicates moderate performance on the validation dataset.
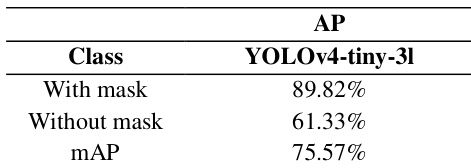
The experiments compare multiple object detection architectures on a three-class face mask detection task to evaluate their predictive accuracy, computational efficiency, and real-time feasibility. The primary benchmark validates the proposed method and YOLOv4-tiny as superior to baseline architectures, demonstrating their capacity to rapidly and accurately identify all mask categories with minimal processing overhead. Additional evaluations further confirm that a multi-class classification strategy significantly enhances robustness across diverse imaging conditions, ultimately proving that these lightweight models are highly viable for real-world mobile and surveillance deployment despite limited training data.