Command Palette
Search for a command to run...
الكشف التلقائي عن أحداث الصوت وتصنيف نداءات الرئيسيات العليا باستخدام الشبكات العصبية
الكشف التلقائي عن أحداث الصوت وتصنيف نداءات الرئيسيات العليا باستخدام الشبكات العصبية
Zifan Jiang Adrian Soldati Isaac Schamberg Adriano R. Lameira Steven Moran
مقدمة في كشف الأحداث الصوتية
الملخص
نقدم نهجاً جديداً للكشف التلقائي عن نداءات الرئيسيات العظمى وتصنيفها من تسجيلات صوتية خام مستمرة تم جمعها خلال أبحاث ميدانية. تستفيد منهجيتنا من الشبكات العصبية العميقة المدربة مسبقاً والمتسلسلة، بما في ذلك wav2vec 2.0 وLSTM، ويتم التحقق من صحتها باستخدام ثلاث مجموعات بيانات من سلالات مختلفة من الرئيسيات العظمى (الإنسان الغاب، والشمبانزي، والبنوبو). تم جمع التسجيلات بواسطة باحثين مختلفين وتشمل مخططات تدوين ملاحظات متنوعة، والتي تقوم خطتنا المعالجة المسبقة وتدريبها بشكل موحد. حققت نتائجنا للكشف عن النداءات وتصنيفها دقة عالية. تهدف منهجيتنا إلى أن تكون قابلة للتعميم على أنواع حيوانية أخرى، وبشكل أوسع، على مهام كشف الأحداث الصوتية. وتشجيعاً للبحث المستقبلي، نجعل خطتنا المعالجة ومنهجياتنا متاحة للجمهور.
One-sentence Summary
Leveraging wav2vec 2.0 and LSTM networks, this pipeline automatically detects and classifies great ape calls from continuous field recordings by uniformly processing heterogeneous annotation schemes, achieving high accuracy across orangutan, chimpanzee, and bonobo datasets while aiming to generalize to other species and broader sound event detection tasks.
Key Contributions
- A unified processing pipeline automatically detects and classifies great ape calls directly from continuous raw audio recordings by combining the wav2vec 2.0 feature extractor with a sequential LSTM network. This architecture standardizes heterogeneous annotation schemes and diverse field recordings into a consistent training framework.
- The wav2vec 2.0 model pretrained exclusively on human speech functions as an effective audio feature representation layer for great ape calls without requiring additional fine-tuning. This result demonstrates strong cross-species acoustic generalization for raw waveform processing.
- Validation across three distinct great ape lineages (orangutans, chimpanzees, and bonobos) achieves more than 80% frame-level classification accuracy and weighted F1-scores. The complete processing pipeline and trained models are publicly released to facilitate reproducible research and extension to other species.
Introduction
Primatologists rely on manually annotating primate vocalizations from continuous field recordings, a process that is labor-intensive and complicated by dense, noisy forest environments. Automating this workflow would significantly accelerate behavioral and acoustic research. Prior sound event detection and animal classification systems typically require pre-segmented audio clips, struggle with continuous raw recordings, and fail to handle overlapping vocalizations and environmental noise effectively. No existing framework specifically addresses automatic great ape call detection from unprocessed field data. The authors leverage a pretrained wav2vec 2.0 feature extractor paired with an LSTM network to detect and classify great ape calls directly from continuous raw audio. Their pipeline processes heterogeneous field recordings into a unified training format, achieves over 80 percent accuracy across orangutan, chimpanzee, and bonobo datasets, and is publicly released to advance computational primatology.
Dataset
-
Dataset Composition and Sources: The authors compiled a multi-species vocalization corpus featuring chimpanzee pant-hoots, orangutan long calls, and bonobo high-hoots sourced from field recordings across natural behavioral contexts such as feeding, traveling, resting, and social or environmental responses.
-
Subset Details: Chimpanzee clips capture isolated pant-hoots without temporal overlap, organized into sequential introduction, build-up, climax, and let-down phases. Orangutan recordings contain complex, multi-pulse long calls with highly variable phase durations and a balanced ratio of call to non-call segments. Bonobo entries are dominated by loud high-hoots, supplemented by shorter, diverse vocalizations that introduce minor class imbalance.
-
Processing and Feature Extraction: All audio clips are converted to .wav format and resampled to 16 kHz before being segmented into 20 millisecond frames with zero padding applied as needed. The authors extract three distinct frame-level feature sets using torchaudio: raw waveforms, spectrograms, and embeddings inferred from a wav2vec 2.0 base model.
-
Label Construction, Splitting, and Model Usage: Frame-level labels are constructed by mapping manual annotations to positive class indices for specific call phases, while all unmarked frames default to a zero index representing non-calls. The complete dataset is shuffled and divided into 80 percent training, 10 percent validation, and 10 percent test sets, with three independent splits generated using random seeds 0, 42, and 3407. This pipeline supports the authors' dual modeling approach, enabling a multi-class phase classifier on chimpanzee data and a binary call detection system on orangutan recordings.
Method
The authors leverage a sequence modeling framework to learn a function f mapping input audio frames I1:T to corresponding label sequences L1:T. The overall architecture processes raw audio waveforms through a feature extraction pipeline, where wav2vec 2.0 features are extracted from the waveform and used as input to a sequence modeling component. As shown in the figure below, the framework begins with the raw waveform, which is converted into spectrogram features and fed into the wav2vec 2.0 model to generate high-level representations. These representations are then processed by a sequence modeling function fm, which produces a hidden sequence H1:T capturing inter-frame dependencies. The hidden sequence is subsequently passed through a dense linear layer fd to generate intermediate outputs D1:T, which are then transformed via a Softmax function fs to yield a probability distribution P1:T over the target classes.
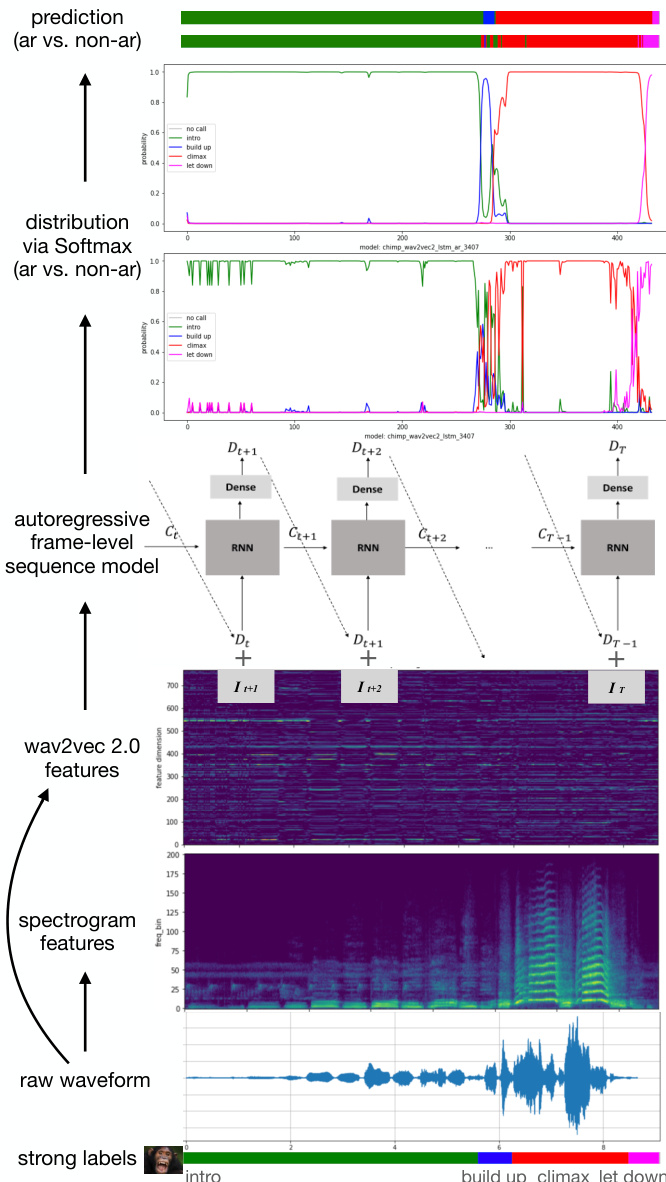
The sequence modeling function fm can take several forms. One implementation uses a bidirectional LSTM with a hidden size of 1024, resulting in a hidden dimension of 2048. Alternatively, a Transformer encoder with 8 attention heads and 6 layers is employed, using a hidden dimension of 1024. The authors also incorporate an autoregressive mechanism, where the output of the dense layer at time step t, Dt, is concatenated to the input It+1 of the next time step, enabling the model to maintain temporal consistency in predictions. This autoregressive connection is applied within an RNN-based sequence model, which can be configured to operate unidirectionally or, with the addition of two stacked layers, to preserve bidirectionality through a summation operation before the final classification step.
The model is trained using cross-entropy loss between the predicted probability distribution P1:T and the ground-truth labels L1:T, with gradients backpropagated through the network to update the parameters. To address class imbalance, class weights are assigned as the reciprocal of the frequency of each class in the training data. This training strategy enables the model to effectively learn from imbalanced datasets while maintaining high classification accuracy across all target classes.
Experiment
Experiments were conducted using PyTorch on a V100 GPU with training capped at 200 epochs and early stopping based on validation performance. Initial tests on chimpanzee vocalizations validated the substantial benefits of wav2vec 2.0 transfer learning, revealed that Transformers offer no advantage over LSTMs for this limited dataset, and confirmed that autoregressive connections enhance output consistency. The approach was subsequently extended to orangutan and bonobo recordings, where binary classification effectively isolates calls for automated analysis. Finally, successful zero-shot transfer from orangutan to bonobo data demonstrates strong potential for developing a generalized great ape sound event detection model despite class imbalance challenges.
The authors conduct experiments to evaluate different models and features for detecting great ape vocalizations, focusing on performance improvements with pre-trained audio representations and autoregressive modeling. They extend their approach to orangutan and bonobo data, achieving competitive results and demonstrating potential for zero-shot transfer across species. Pre-trained audio features significantly outperform raw waveform and spectrogram inputs in performance. Autoregressive modeling improves consistency and performance compared to non-autoregressive approaches. The model shows promising generalizability to unseen species through zero-shot transfer learning.
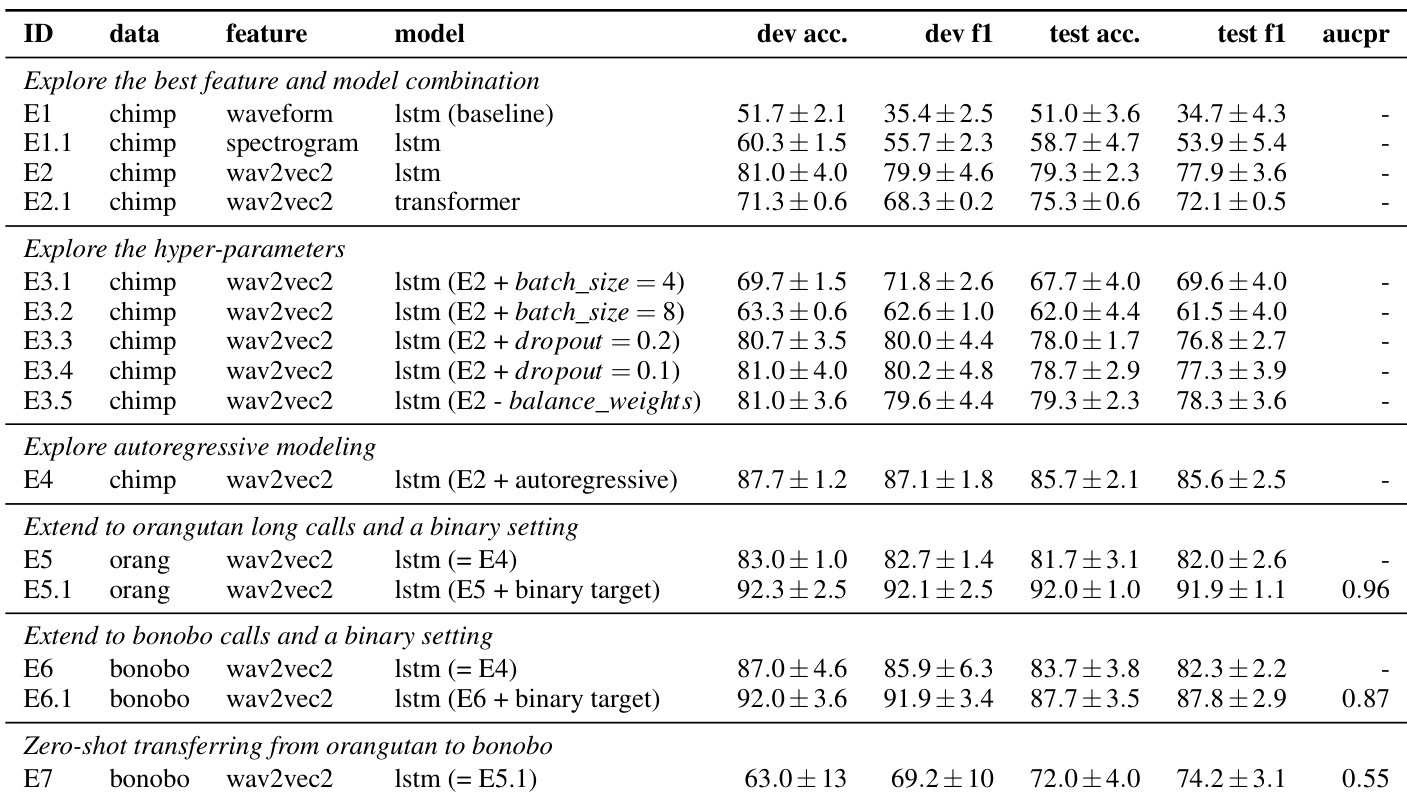
The authors conduct experiments on chimpanzee, orangutan, and bonobo data sets to evaluate their model's performance in detecting call types, with results showing consistent behavior across species and indicating the potential for generalizable sound event detection. The experiments involve various model architectures and training strategies, with the model achieving stable output in non-autoregressive settings and demonstrating transferability across species. The model is tested on three great ape data sets with varying numbers of audio clips and call types, showing consistent performance across species. Non-autoregressive models produce stable outputs with minimal variation, as illustrated by small gaps in results. The model trained on one species shows promise when applied to another, suggesting potential for general-purpose sound event detection across great apes.

The authors evaluated multiple model architectures and feature representations across chimpanzee, orangutan, and bonobo datasets to assess their effectiveness in great ape vocalization detection. Comparisons between pre-trained audio representations and raw inputs demonstrated that learned features substantially enhance detection accuracy, while autoregressive modeling yielded more consistent performance than non-autoregressive alternatives. Cross-species testing further revealed that models trained on a single species generalize effectively to unseen apes, highlighting the approach's strong potential for broad, zero-shot sound event detection across great apes.