Command Palette
Search for a command to run...
تصنيف النصوص
الملخص
Please provide the title and abstract you would like me to translate.
One-sentence Summary
The authors propose a novel pipeline and comparative analysis of twelve machine learning text classifiers evaluated on a public spam corpus, integrating NLP-based preprocessing with systematic hyperparameter tuning to optimize performance across F-score, precision, recall, and run time while addressing the critical tradeoff in classification aggressiveness.
Key Contributions
- The study evaluates twelve machine learning text classifiers on a public spam corpus to quantify how varying feature dimensions and hyperparameters influence classification performance.
- A preprocessing pipeline incorporating specific natural language processing techniques is introduced to optimize hyperparameter selection and improve model accuracy across F-score, precision, recall, and run time metrics.
- The work provides a statistical analysis of classification outcomes and supplies an adaptable Python script for application to various spam detection datasets.
Introduction
Text-based communication powers modern business operations but is frequently exploited for malicious spam, making robust text classification essential for digital security and data protection. Prior research has extensively tested classifiers like Naïve Bayes, support vector machines, and neural networks, yet many studies suffer from inconsistent preprocessing, ad hoc hyperparameter selection, and limited model interpretability, which hinders reliable real-world deployment. The authors address these gaps by introducing a standardized pipeline that integrates natural language processing techniques with systematic hyperparameter optimization to evaluate twelve machine learning classifiers. They further validate their methodology using statistical testing and explainability tools to quantify feature importance and classification drivers, ultimately delivering a reproducible framework that achieves strong spam filtering performance on the Enron dataset.
Dataset
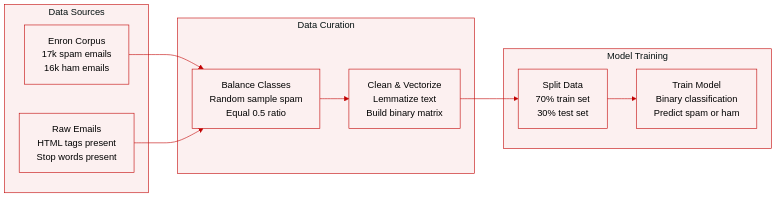
-
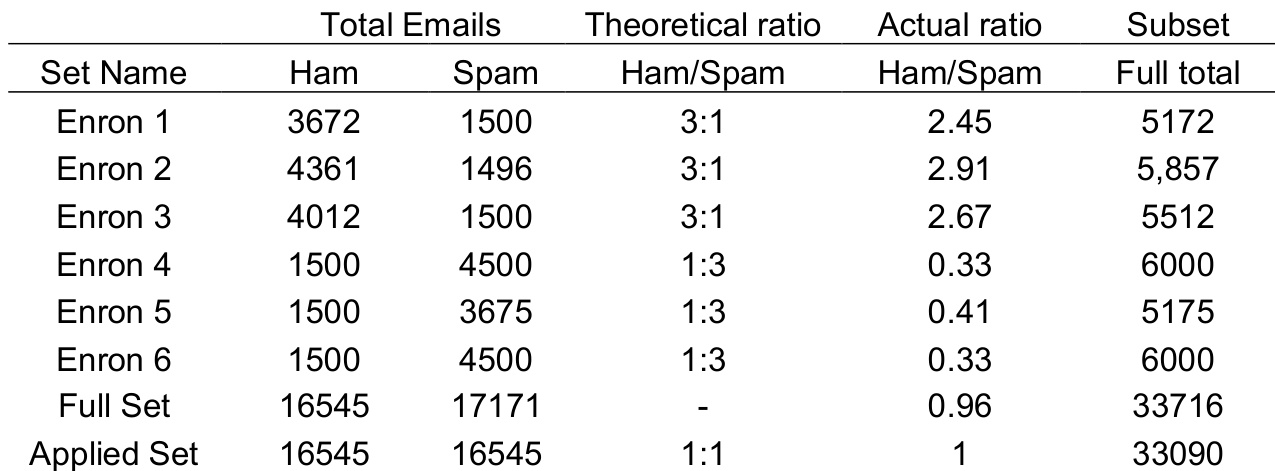
Dataset Source & Composition: The authors use the Enron spam corpus, which originally contains 17,171 spam and 16,545 ham emails. To prevent class imbalance, they resample the corpus to a 0.5 ratio by randomly extracting 16,545 spam emails, creating an equal split between both categories.
-
Subset Sizes & Splits: The balanced dataset is divided into a 70 percent training set and a 30 percent test set. Both subsets maintain the equal ham to spam proportion established during resampling.
-
Data Usage & Mixture: The authors apply the balanced 0.5 mixture directly to a binary classification task. The 70/30 train test partition feeds the model while preserving the original class distribution across both phases.
-
Processing & Feature Construction: Starting with preprocessed emails that still contain HTML tags and stop words, the team filters out single letters, numbers, and generic email headers like "subject," "cc," "to," and "Enron." They then apply lemmatization to normalize word forms. Finally, they extract the most frequent terms to build a fixed dictionary and convert each email into a binary vector matrix, where a 1 indicates the presence of a dictionary word, mirroring a Word2Vec style encoding before feeding the data into the classifier.
Method
The classification pipeline proposed in this work is structured into six primary stages, forming a comprehensive framework for text classification using a diverse set of machine learning models. The process begins with the selection of the Enron dataset, a well-documented corpus frequently used in text classification research, as the source of textual data. Following this, the dataset is partitioned into training and testing subsets, with a standard 70%–30% split allocated to train and test sets, respectively. This allocation ensures a robust evaluation of model performance on unseen data.
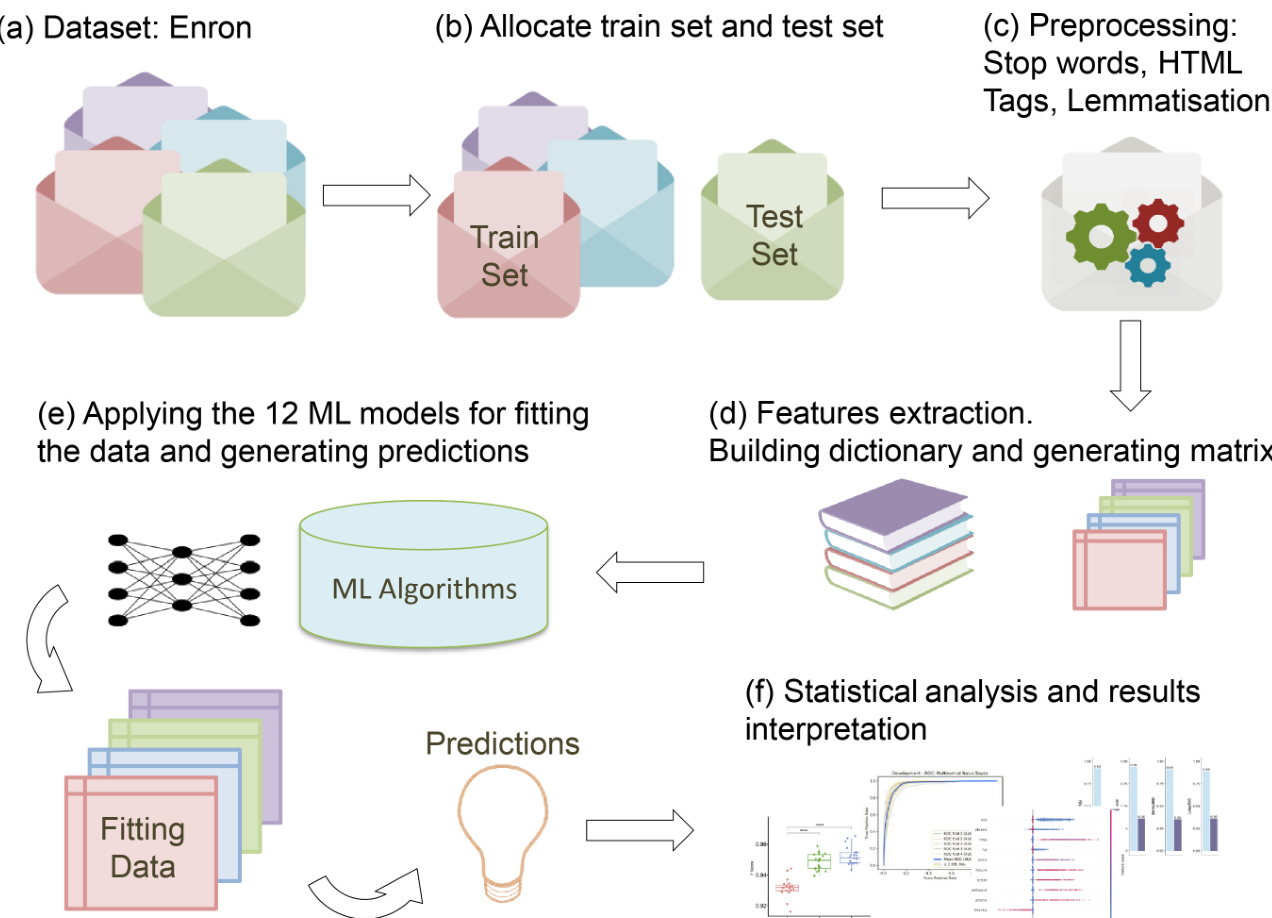
Refer to the framework diagram for a visual overview of the entire process. The next stage involves data preprocessing, where noise reduction techniques are applied to the textual data. This includes the removal of stop words, lemmatisation, and the elimination of HTML tags, all aimed at enhancing the quality and relevance of the features used for classification. These steps are critical for reducing dimensionality and mitigating the impact of irrelevant or redundant information on model performance.
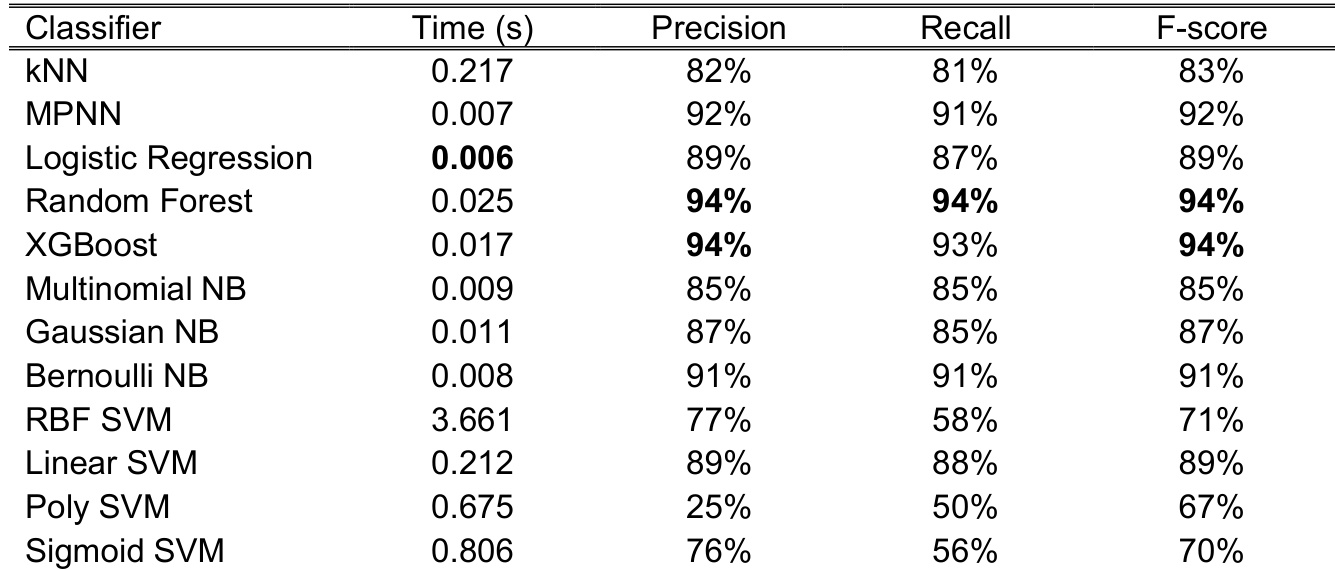
Following preprocessing, features are extracted to construct a dictionary and generate feature matrices for both the training and test sets. This step transforms the textual data into a numerical format suitable for machine learning algorithms, typically through methods such as bag-of-words or TF-IDF vectorization. The resulting feature matrices are then used to fit and evaluate 12 different supervised machine learning classifiers. These models include variants of Naïve Bayes (Multinomial, Gaussian, and Bernoulli), Support Vector Machines (SVM) with linear, polynomial, and radial basis function kernels, k-Nearest Neighbours (kNN) using brute force, ball tree, and KD-tree implementations, a Multilayer Perceptron Neural Network (MPNN), Logistic Regression, Random Forest, and Extreme Gradient Boost (XGBoost). Each model employs its own unique mathematical formulation and optimization strategy to learn patterns from the training data and generate predictions.
The final stage of the pipeline involves statistical analysis and interpretation of the classification results. This includes the application of statistical models to assess the significance of the outcomes and provide insights into the performance and behavior of the various classifiers. The framework is designed to allow for a systematic comparison of the 12 models, enabling a thorough evaluation of their strengths and weaknesses in the context of text classification tasks.
Experiment
The evaluation setup tests twelve machine learning classifiers on the Enron spam corpus using stratified cross-validation, with dedicated experiments validating the impact of feature selection, hyperparameter tuning, and preprocessing steps on model accuracy and efficiency. The comparative analysis confirms that ensemble approaches deliver the strongest predictive capabilities, whereas neural and linear architectures provide superior computational speed, with statistical testing verifying significant performance variations across the algorithms. Interpretability investigations further demonstrate that each model leverages unique linguistic cues for spam detection, emphasizing the necessity of aligning algorithm choice with domain-specific text characteristics. Ultimately, the findings underscore that systematic preprocessing and careful hyperparameter optimization are essential for maximizing classification performance across diverse machine learning frameworks.
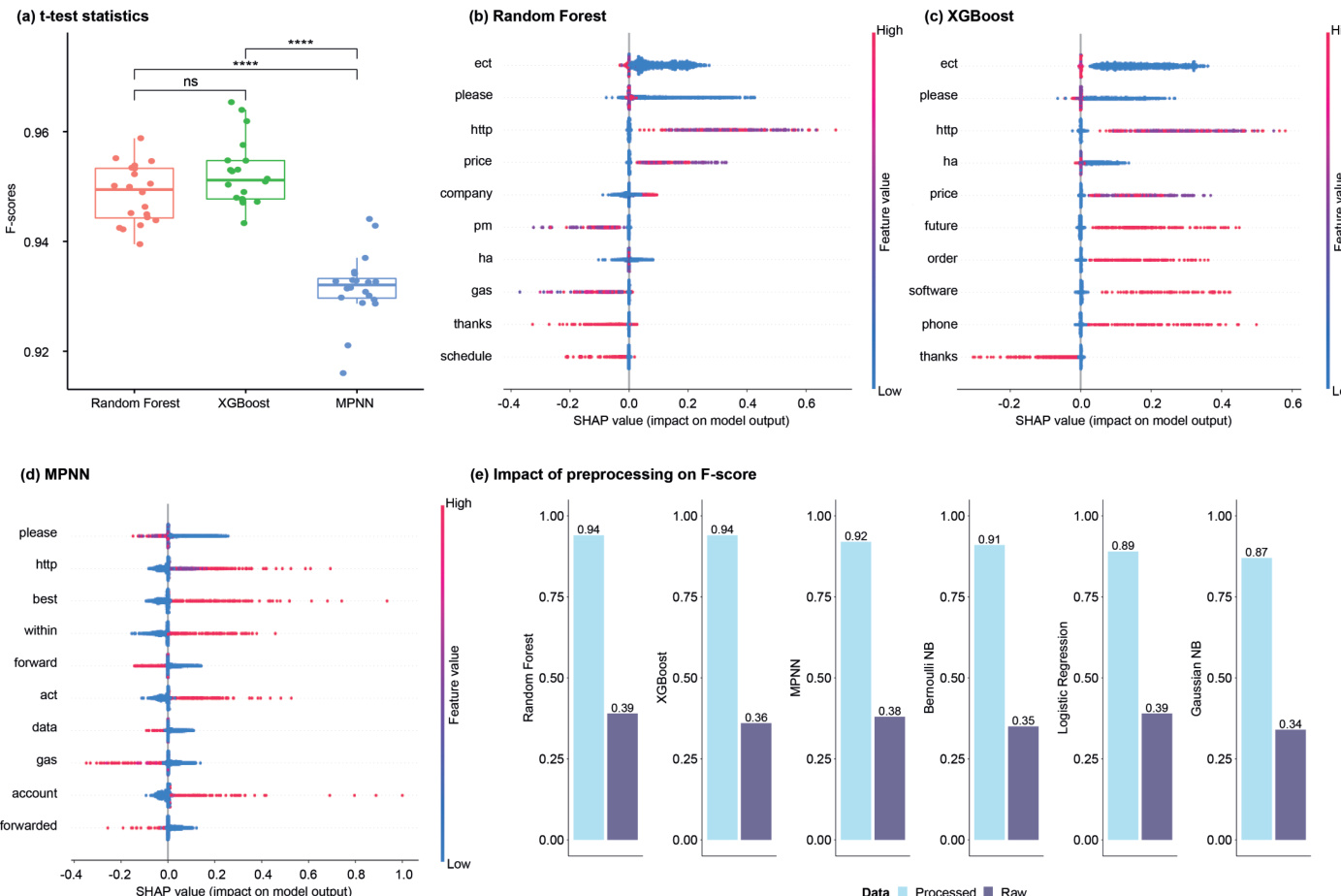
The experiment evaluates multiple machine learning models for spam classification using the Enron dataset, focusing on performance metrics such as F-score, run time, and ROC curves. The results show that certain models, including random forest and extreme gradient boost, achieve high accuracy with relatively short prediction times, while others like multilayer perceptron neural network demonstrate strong performance in terms of speed and consistency. The study also highlights the impact of hyperparameter tuning and preprocessing steps on model effectiveness. Random forest and extreme gradient boost achieved high F-scores with competitive run times, indicating strong overall performance. Multilayer perceptron neural network demonstrated consistent accuracy and the shortest prediction time among the top-performing models. Preprocessing steps significantly improved model performance, with more than a two-fold increase in F-scores for several classifiers.
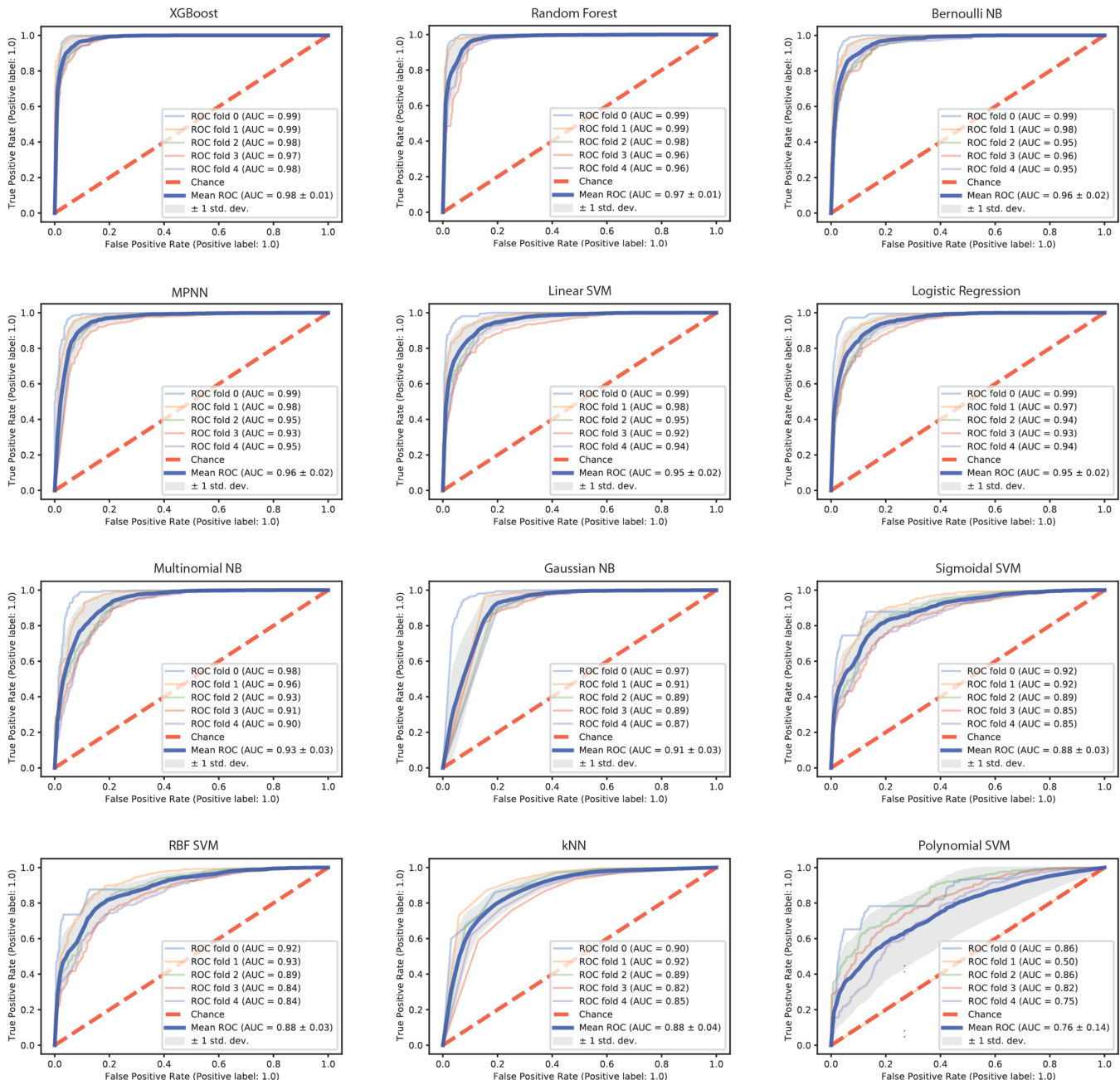
The authors evaluate multiple machine learning models for spam classification using ROC curves to compare their performance. The results show that certain models achieve high average AUC values, with some exhibiting consistent performance across folds, while others show greater variability. The analysis highlights differences in model behavior, particularly in how they respond to specific features, as revealed by interpretability methods. XGBoost and Random Forest achieve high average AUC values, with minimal variation across cross-validation folds. Polynomial SVM shows the lowest average AUC and the greatest variability among folds, indicating poor performance and instability. The ROC curves reveal that the performance of models like Bernoulli NB and MPNN is consistently strong, with high true positive rates and low false positive rates across folds.
The authors compare multiple machine learning classifiers for spam detection, evaluating their performance based on precision, recall, F-score, and prediction time. The results show that Random Forest and XGBoost achieve the highest F-scores, while Logistic Regression demonstrates the fastest prediction time. The the the table highlights significant variations in classifier performance, particularly in recall and F-score, with some models like RBF SVM and Polynomial SVM showing notably lower performance. Random Forest and XGBoost achieve the highest F-scores among the tested classifiers. Logistic Regression is the fastest classifier in terms of prediction time. RBF SVM and Polynomial SVM show significantly lower performance in recall and F-score compared to other models.
The authors compare the performance of 12 machine learning models for spam classification using a range of metrics including F-score, run time, and AUC-ROC. The analysis highlights that certain models, such as XGBoost and Random Forest, achieve high F-scores with minimal statistical difference, while others like MPNN are faster but slightly less accurate. Model interpretability is explored through SHAP values, revealing how different models rely on distinct features for classification. Preprocessing steps significantly improve performance across most models. XGBoost and Random Forest achieve the highest F-scores with minimal statistical difference, while MPNN is faster but slightly less accurate. SHAP analysis reveals that different models rely on distinct features, with XGBoost focusing on spam-specific terms and Random Forest on general email vocabulary. Preprocessing steps lead to a substantial improvement in F-scores across most models, demonstrating their importance in text classification.
The experiments evaluate multiple machine learning classifiers for spam detection on the Enron dataset, validating their predictive accuracy, computational efficiency, and feature interpretability across cross-validation folds. Tree-based ensemble methods consistently deliver the most robust and stable classification performance, while neural architectures provide faster inference with marginally reduced accuracy. Systematic data preprocessing substantially enhances overall model effectiveness, and interpretability analysis confirms that high-performing classifiers leverage distinct linguistic patterns tailored to spam detection.