Command Palette
Search for a command to run...
التعلم الخاضع للإشراف
الملخص
Please provide the title and abstract you would like me to translate.
One-sentence Summary
The authors propose a semi-supervised continual learning framework that employs a gradient learner to predict gradients on unlabeled data from labeled examples, thereby integrating unlabeled samples into supervised continual learning frameworks and achieving state-of-the-art classification accuracy and backward transfer across mainstream continual learning methods, adversarial continual learning, and semi-supervised learning tasks while significantly alleviating catastrophic forgetting and enhancing generalization.
Key Contributions
- A generic semi-supervised continual learning framework is introduced that relaxes the requirement for known labels on unlabeled data, enabling direct integration into existing continual learning architectures.
- A novel gradient learner trained on labeled samples predicts pseudo gradients for unlabeled inputs, allowing the model to incorporate external data without relying on conventional pseudo-labeling loss functions.
- Extensive evaluations across continual learning, adversarial continual learning, and semi-supervised learning tasks demonstrate state-of-the-art classification accuracy and backward transfer, confirming that the approach effectively alleviates catastrophic forgetting and improves generalizability.
Introduction
Continual learning enables AI models to acquire new visual concepts over time without erasing prior knowledge, a capability essential for deploying adaptive systems in dynamic real-world environments. Prior approaches typically assume that both labeled and unlabeled data share known class distributions, which contradicts practical scenarios where unlabeled samples often contain novel or unrelated concepts. Traditional semi-supervised techniques also rely on pseudo-labeling, a strategy that forces unknown data into predefined categories and struggles to compute effective backpropagation gradients when ground-truth labels are missing. The authors leverage a novel gradient learner trained on labeled examples to directly predict pseudo gradients for unlabeled inputs. By bypassing explicit label assignment, this method seamlessly incorporates unlabeled data into supervised continual learning pipelines, significantly enhancing model generalizability and mitigating catastrophic forgetting across diverse benchmarks.
Dataset
-
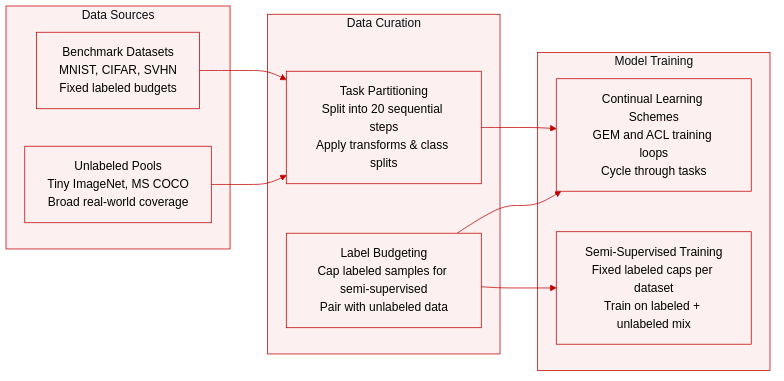
Dataset Composition and Sources The authors use a combination of standard computer vision benchmarks and large-scale unlabeled repositories to support continual and semi-supervised learning experiments. Supervised tasks draw from MNIST variants, CIFAR-100, miniImageNet, and SVHN. Unlabeled data pools are sourced from Tiny ImageNet and MS COCO to provide broad, real-world coverage for continual learning scenarios.
-
Subset Details The authors organize the data into clearly defined subsets with specific dimensions and transformations:
- MNIST permutation (MNIST-P) and MNIST rotation (MNIST-R) both contain 70,000 images at 28x28 resolution. MNIST-P applies a fixed pixel permutation, while MNIST-R applies a fixed rotation between 0 and 180 degrees.
- iCIFAR-100 and CIFAR-100 each provide 60,000 images at 32x32 resolution, structured by class.
- miniImageNet is an ImageNet variant containing 60,000 images at 84x84 resolution across 100 classes.
- The semi-supervised evaluation uses SVHN, CIFAR-10, and CIFAR-100 with strict labeled budgets of 1,000, 4,000, and 10,000 samples respectively.
-
Task Partitioning and Processing The authors apply consistent structural processing across all supervised datasets:
- All training samples are divided into 20 sequential tasks.
- CIFAR-100, iCIFAR-100, and miniImageNet are split into tasks containing 5 classes each.
- MNIST-P and MNIST-R are split into tasks containing 10 classes each, with each task assigned a unique permutation or rotation transform.
- The authors pair Tiny ImageNet with MNIST and CIFAR experiments, while MS COCO images are reserved for miniImageNet training to create a representative unlabeled pool.
-
Training Usage and Configuration The authors structure the data to align with specific learning schemes:
- The GEM and ACL schemes utilize the 20-task partitions described above.
- The authors implement an epoch repetition strategy for the ACL scheme, cycling through images within each task during every training epoch.
- Semi-supervised protocols follow established benchmarking standards with fixed labeled data caps, while continual learning experiments leverage the large-scale unlabeled pools to simulate distribution shifts across tasks.
Method
The proposed method operates within a semi-supervised continual learning (SSCL) framework, designed to leverage both labeled and unlabeled data for model training. The overall architecture consists of two primary components: gradient learning and gradient prediction, which are integrated into a continual learning process. The framework enables the model to update its parameters using pseudo gradients derived from unlabeled data, thereby enhancing generalizability without requiring explicit labels.
The gradient learning process is responsible for training a gradient learner h(⋅;ω), which is a separate module designed to predict pseudo gradients. This learner takes as input the model's activations (logits) zi and maps them to predicted gradients gi. The training of h is conducted using labeled data, where the fitness of the predicted gradients is evaluated by their ability to minimize a fitness loss function. Specifically, the fitness loss is defined as ℓfit(zi,gi,yi)=λℓ(zi−ηgi,yi), where ℓ is the base loss function (e.g., cross-entropy), yi is the ground-truth label, η is the learning rate, and λ is a scaling coefficient. This formulation ensures that the predicted gradients are optimized to produce a loss reduction when applied to the model's parameters, rather than being constrained to match the exact direction and magnitude of the true gradients. To improve robustness, the predicted gradients are normalized using the magnitude τi=∥∂zi∂ℓ∥ of the true gradient from the last labeled sample, resulting in a scaled predicted gradient gˉi=ατigi/∥gi∥, where α is a hyperparameter controlling the magnitude proportion.
The gradient prediction module utilizes the trained gradient learner h(⋅;ω) to generate pseudo gradients for unlabeled data. When an unlabeled sample x~i is presented, the model first computes its logits z∣x~i=f(x~i,ti;θ), where f is the main model and θ are its parameters. The gradient learner h then predicts a gradient g∣x~i=h(z∣x~i;ω), which is subsequently normalized using the magnitude τi−1 of the last known true gradient. The resulting pseudo gradient gˉ∣x~i is then used to update the model parameters via the chain rule: θ←θ−ηgˉ∣x~i∂θ∂gˉ∣x~i. This process allows the model to learn from unlabeled data by back-propagating the predicted gradients, effectively simulating a supervised update.
The training process is governed by a probabilistic sampling policy to manage the integration of unlabeled data. At each training step, unlabeled data x~ are sampled from a distribution with a probability determined by a threshold p. This policy enables a smooth transition between supervised continual learning (when p=0) and semi-supervised continual learning (when p=1), allowing the framework to adapt to varying availability of unlabeled data. The use of a probabilistic threshold is critical for balancing the trade-off between generalizing to new data and avoiding the accumulation of prediction errors that could overwhelm the knowledge learned from labeled data. The overall framework, as illustrated in the provided diagrams, integrates these components to enable continual learning in a semi-supervised setting, where the model can adapt to new tasks and data distributions while efficiently utilizing the information from unlabeled samples.
Experiment
The experiments evaluate the proposed gradient prediction method across task-incremental continual learning, adversarial continual learning, and semi-supervised learning settings using established protocols and baseline comparisons. Qualitative analysis demonstrates that predicted gradients consistently guide model updates toward more optimal parameter regions, effectively mitigating catastrophic forgetting and enhancing generalization across diverse datasets and backbone architectures. Unlike pseudo-labeling approaches that struggle with label noise and distribution mismatches, the proposed method maintains stable performance and robustness to hyperparameter variations and visual diversity shifts. Overall, the findings confirm that leveraging predicted gradients from unlabeled data provides a reliable and computationally efficient mechanism for continual learning without compromising predictive accuracy.
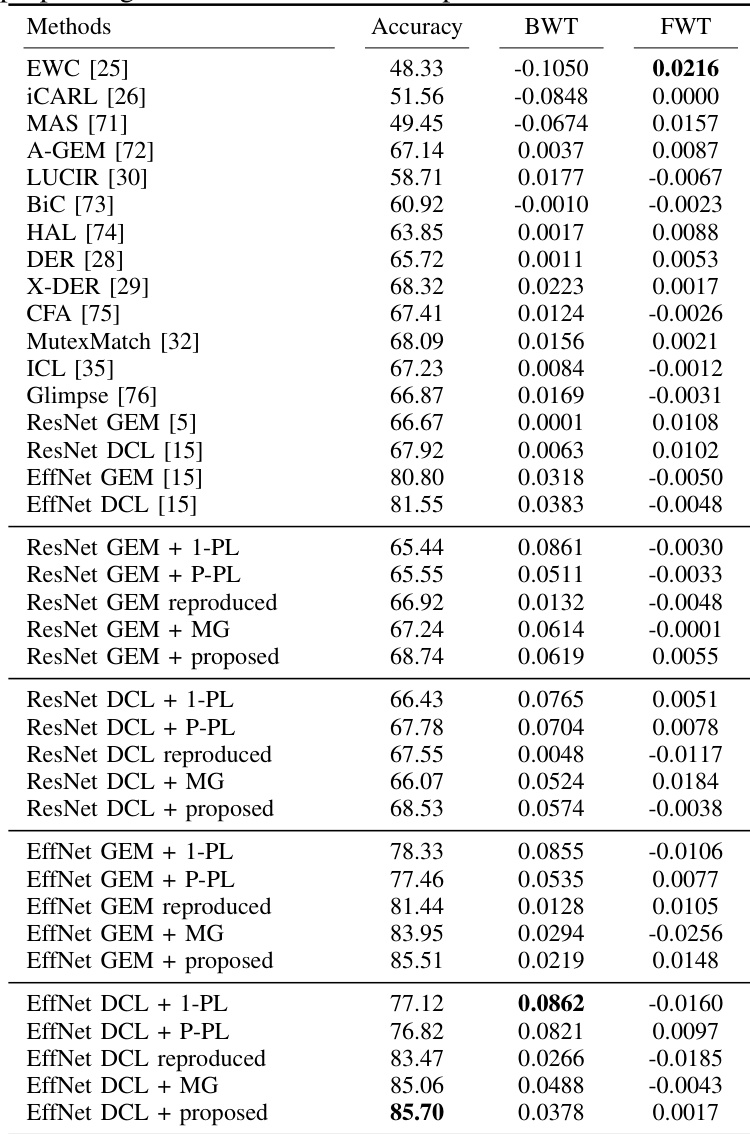
The authors evaluate the proposed method in continual learning settings using multiple benchmarks and backbones, comparing it against various baselines. Results show that the proposed method consistently improves average accuracy and backward transfer compared to baselines, with the most significant gains observed in the EfficientNet-based models. The method demonstrates better performance than pseudo-labeling approaches and achieves higher accuracy and stability than random noise-based alternatives. The proposed method achieves higher average accuracy and backward transfer than baseline methods across different backbones and datasets. The proposed method outperforms pseudo-labeling approaches and random noise-based alternatives in terms of accuracy and stability. EfficientNet-based models show the most significant improvements with the proposed method, particularly in average accuracy and backward transfer.
The authors compare the performance of the proposed method with existing continual learning approaches on a task-incremental learning setup. Results show that the proposed method achieves higher accuracy and maintains a positive backward transfer score compared to the baseline, indicating improved predictive ability and reduced catastrophic forgetting. The proposed method's performance is stable and consistently outperforms the baseline across multiple runs. The proposed method achieves higher accuracy and positive backward transfer compared to the baseline. The proposed method improves predictive ability and reduces catastrophic forgetting in continual learning. The proposed method demonstrates stable performance across multiple runs, outperforming the baseline consistently.
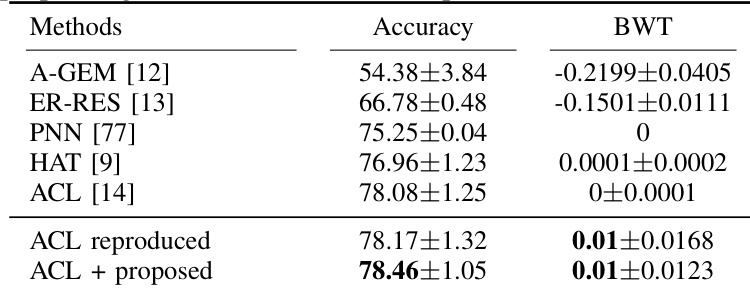
The authors evaluate the proposed method in a continual learning setting using GEM and DCL as baselines, comparing performance across multiple metrics including accuracy, backward transfer, and forward transfer. The proposed method consistently improves upon baseline models, achieving higher accuracy and forward transfer while also enhancing backward transfer. The results show that the proposed approach effectively leverages unlabeled data to improve model performance and generalization. The proposed method achieves higher accuracy and forward transfer compared to baseline methods. The proposed method improves backward transfer, indicating better retention of previously learned tasks. The proposed method outperforms other approaches that use pseudo labels or random noise as predicted gradients.
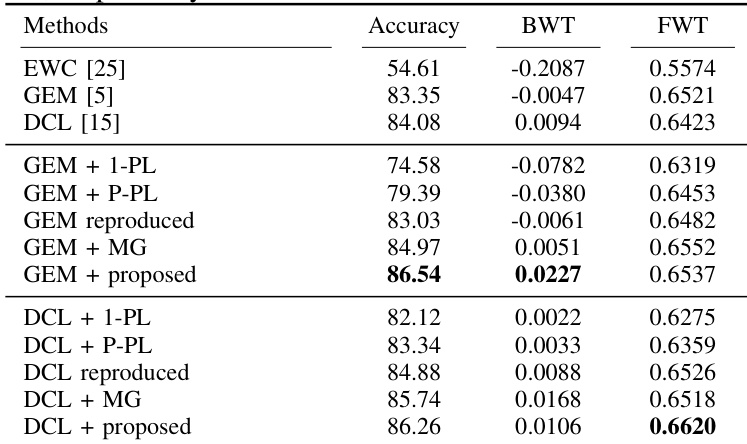
The authors analyze the impact of different sources of unlabeled images on the performance of the proposed method in a continual learning setting. The results show that the choice of unlabeled data source affects model accuracy, with more visually similar datasets leading to better performance. The proposed method consistently improves classification accuracy, backward transfer, and forward transfer compared to the baseline, indicating enhanced generalization and reduced catastrophic forgetting. The performance of the proposed method varies with the visual diversity of the unlabeled data source, with more similar datasets yielding higher accuracy. The proposed method improves classification accuracy, backward transfer, and forward transfer compared to the baseline. Using random noise as predicted gradients leads to lower accuracy but higher backward transfer due to the disruption of learning on earlier tasks.
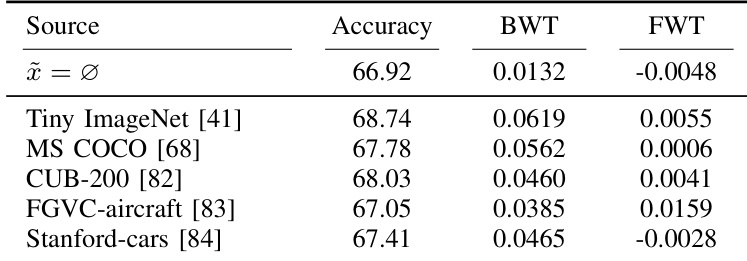
The authors present a method that uses predicted gradients from unlabeled images to improve continual learning performance. The approach is evaluated across various datasets and backbones, with results showing consistent improvements in average accuracy, backward transfer, and forward transfer compared to baseline methods. The method is shown to be effective in both supervised and semi-supervised settings, and its performance is robust to changes in hyperparameters. The proposed method improves average accuracy, backward transfer, and forward transfer compared to baseline methods in continual learning tasks. The method is effective in both supervised and semi-supervised learning settings, demonstrating robust performance across different datasets and backbones. The approach is robust to hyperparameter variations, with optimal performance achieved within a specific range of parameter values.
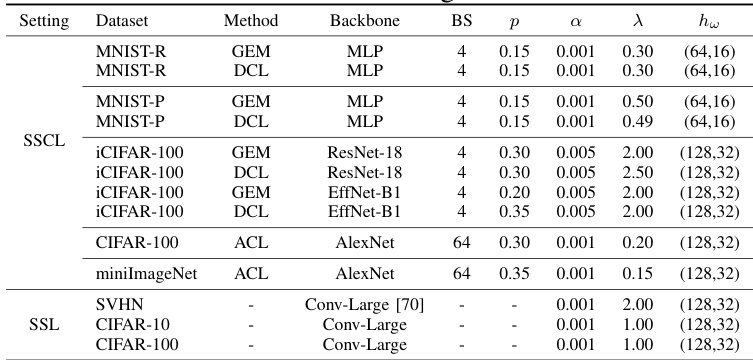
The proposed method is evaluated across multiple continual learning benchmarks and backbones, where it is tested against baselines including pseudo-labeling, random noise generation, and established gradient-based algorithms. These experiments validate the approach's ability to consistently enhance predictive accuracy and mitigate catastrophic forgetting by improving both backward and forward transfer, with particularly notable gains in EfficientNet architectures. Additional analyses confirm that the method effectively leverages unlabeled data for better generalization, demonstrating that visually similar unlabeled sources yield superior performance while maintaining stability across diverse settings. Overall, the technique proves robust in both supervised and semi-supervised contexts, delivering reliable improvements without strict sensitivity to hyperparameter tuning.