Command Palette
Search for a command to run...
Please provide the title you would like me to translate.
Please provide the title you would like me to translate.
تدريب محدود باستخدام GPT-2 على PyTorch
الملخص
Please provide the title and abstract you would like me to translate.
One-sentence Summary
Through GPT-2 replication experiments on a public dataset, the authors identify that early long sequences drive extreme gradient variance and the stability-efficiency dilemma, then introduce Sequence Length Warmup to mitigate this instability and enable efficient GPT model pre-training without compromising generalization accuracy.
Key Contributions
- An empirical analysis replicating the GPT-2 model establishes a strong correlation between training instability and extreme gradient variance. The investigation further identifies long sequence lengths as a primary driver of this instability during early training stages.
- A Sequence Length Warmup method is introduced to stabilize gradient variance by progressively adjusting sequence lengths, supported by a lightweight tuning strategy that requires only a small fraction of the full training budget.
- Evaluations on GPT-3 scale models demonstrate that the method enables stable pre-training with more aggressive hyperparameters, yielding a tenfold reduction in data requirements and a seventeenfold decrease in wall-clock training time.
Introduction
Pre-training large-scale autoregressive language models requires substantial computational resources, making training efficiency a critical bottleneck for both research and real-world deployment. Practitioners typically accelerate convergence by scaling up batch sizes and learning rates, but this approach triggers a stability-efficiency dilemma where aggressive settings cause extreme gradient variance and frequent training divergence. Existing mitigation strategies, such as gradient clipping or standard warmup schedules, often fail to stabilize billion-parameter models or prioritize speed over robustness. To address this gap, the authors analyze pre-training dynamics and identify long sequence lengths as a primary source of gradient variance spikes. They then introduce Sequence Length Warmup, a curriculum-style technique that gradually increases sequence length during early training phases. This method enables stable optimization with significantly larger batch sizes and learning rates, dramatically reducing both wall-clock time and data requirements while preserving zero-shot accuracy. The authors also provide a lightweight hyperparameter tuning strategy that quickly adapts the approach without incurring full pre-training costs.
Dataset

- Dataset composition and sources: The authors do not specify the dataset composition or sources in the provided excerpt.
- Key details for each subset: No subset sizes, origins, or filtering rules are included.
- How the paper uses the data: Training splits, mixture ratios, and data utilization strategies are not described.
- Processing details: The authors do not outline cropping strategies, metadata construction, or preprocessing steps in the submitted text.
Method
The authors leverage a sequence length warmup (SLW) strategy to address training instability during pre-training, particularly in models like GPT-2 that are sensitive to long input sequences. The core idea is to begin training with short sequence lengths to ensure stability and gradually increase the sequence length over time, allowing the model to eventually learn from longer contextual information. This approach requires two key components: support for variable sequence lengths during training and an adaptive pacing function to determine the sequence length at each training step.
To support variable sequence lengths efficiently, the authors implement a truncation-based method that avoids the overhead of pre-indexing data for all possible sequence lengths. In this approach, the dataloader initially indexes raw text into sequences of the full sequence length. At each training step, the pacing function determines the target sequence length, and the full-length sequences are truncated accordingly to form the mini-batch. While this method results in some data being dropped during each step, the authors note that dropped data indices can be recorded and reused in future steps, mitigating data loss over time.
The pacing function is defined as a step-wise linear function, where the sequence length at step t is given by:
seqlent=seqlens+(seqlene−seqlens)×min(Tt,1)Here, seqlens is the starting sequence length, seqlene is the ending (full) sequence length, and T is the total number of steps over which the sequence length increases. The authors also explore alternative pacing functions, including a discrete two-stage function from prior work, a step-wise root function with an additional hyperparameter, and an adaptive function based on training and validation losses. However, these alternatives either lead to unstable training or offer performance comparable to the linear function without significant benefits.

As shown in the figure below: Figure 3 illustrates the validation perplexity during GPT-2 117M pre-training with different pacing function durations T. Subfigure (a) shows the step-wise validation perplexity at the beginning of training, while subfigure (b) presents the token-wise validation perplexity at the end of training. The results demonstrate that the model's performance is not highly sensitive to the duration T within a reasonable range, indicating that the choice of T can be made with relatively low computational cost.
To reduce the need for extensive grid searches, the authors propose a low-cost tuning strategy. This strategy begins with a small starting sequence length seqlens=8 and a duration T set to a few multiples of the learning rate warmup steps. The starting length is increased until validation perplexity no longer exhibits significant fluctuations at the beginning of training. A binary search is then performed to find the largest T that avoids significant validation perplexity fluctuation during the initial training phase. This heuristic relies only on the validation set and does not require downstream task evaluation. The approach is validated on GPT-2 1.5B and GPT-3 125M models, where it achieves similar stability and efficiency benefits as full grid search on the GPT-2 117M case.
Experiment
The experiments evaluate GPT-2 and GPT-3 models across varying batch sizes, learning rates, and sequence lengths to validate the inherent trade-off between training stability and computational efficiency. Analysis reveals that aggressive hyperparameters accelerate convergence but trigger severe instability driven by accumulated gradient variance, particularly when long sequences are introduced early in training. The proposed sequence length warmup strategy effectively suppresses these variance outliers, enabling stable optimization at substantially higher learning rates. Consequently, the method successfully resolves the stability-efficiency dilemma by delivering faster, more resource-efficient pre-training while preserving or improving downstream task accuracy.
The authors analyze the trade-off between training stability and efficiency in large language model pre-training, focusing on how increasing batch size and learning rate improves efficiency but leads to training instability, particularly in larger models. They introduce a method that enables stable training at higher hyperparameter settings by gradually increasing sequence length, which reduces gradient variance and allows for faster convergence without sacrificing performance. The results show that the proposed approach maintains or improves accuracy while significantly reducing training time and data requirements. Increasing batch size and learning rate improves training efficiency but leads to instability and worse performance in baseline models. The proposed method enables stable training at higher hyperparameter settings by gradually increasing sequence length, reducing gradient variance. The method achieves better accuracy and faster training with less data and time compared to baseline approaches.
The authors compare different training configurations for GPT-2 models, including baseline methods and a proposed sequence length warmup approach, across various hyperparameters. Results show that the proposed method achieves lower pre-training perplexity and higher zero-shot accuracy on WikiText-103 and LAMBADA datasets compared to baseline configurations, while also requiring fewer training steps and time. The proposed sequence length warmup method achieves lower pre-training perplexity and higher zero-shot accuracy than baseline methods. The proposed method reduces training time while maintaining or improving model performance. The method enables stable training under larger batch sizes and learning rates, improving training efficiency.
The authors analyze training instability in GPT-2 pre-training across different model sizes, batch sizes, and learning rates, using loss ratios to measure instability. The results show that larger batch sizes and learning rates increase instability, leading to more frequent and severe loss spikes, which negatively impact convergence and downstream performance. The analysis also reveals a strong correlation between training instability and gradient variance outliers, particularly in the maximum element of the Adam variance state. Larger batch sizes and learning rates increase training instability, resulting in more frequent and severe loss spikes. Training instability correlates strongly with gradient variance outliers, especially in the maximum element of the Adam variance state. The proposed method enables stable training at larger batch sizes and learning rates, improving efficiency without sacrificing convergence or performance.

The authors analyze the trade-off between training stability and efficiency in GPT-2 pre-training, showing that larger batch sizes and learning rates improve efficiency but lead to increased training instability, as measured by loss spikes and gradient variance. They introduce a method that enables stable training at higher efficiency settings, achieving better convergence and downstream performance compared to baselines. The results demonstrate that the proposed approach maintains or improves accuracy while reducing training time and enabling faster convergence. Larger batch sizes and learning rates improve training efficiency but increase instability and degrade downstream performance. The proposed method enables stable training at higher efficiency settings, improving convergence and maintaining accuracy. The method reduces training time and improves performance on both zero-shot and few-shot tasks compared to baseline approaches.
The authors analyze the training stability and efficiency of GPT-2 models under different configurations, observing that larger batch sizes and learning rates lead to more frequent training loss spikes and instability, particularly in larger models. They identify a strong correlation between training instability and gradient variance outliers, and propose a method that enables stable training with larger batch sizes and learning rates, improving both efficiency and convergence. The results demonstrate that the proposed approach resolves the stability-efficiency trade-off, allowing for faster training without sacrificing model performance. Larger batch sizes and learning rates lead to increased training instability, with more frequent loss spikes and higher maximum loss ratios, especially in larger models. Training instability is strongly correlated with gradient variance outliers, particularly the maximum element of the Adam variance state. The proposed method enables stable training with larger batch sizes and learning rates, improving training efficiency and convergence while maintaining or improving model performance.
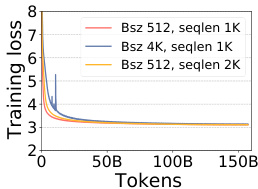
The experiments evaluate GPT-2 pre-training configurations to validate how batch size and learning rate adjustments influence the trade-off between computational efficiency and optimization stability. Subsequent analyses confirm that aggressive hyperparameter scaling consistently induces training instability through loss spikes and gradient variance outliers, which ultimately hinder convergence and downstream task performance. The proposed sequence length warmup method is then validated as an effective solution that progressively expands context to suppress gradient variance and stabilize the optimization process. Ultimately, the findings demonstrate that this approach successfully reconciles efficiency and stability, delivering faster convergence and lower resource requirements while preserving or enhancing model accuracy across diverse benchmarks.