Command Palette
Search for a command to run...
عرض ترجمة آلية من الشروكي إلى الإنجليزية مع تقدير الجودة والتغذية الراجعة التصحيحية
عرض ترجمة آلية من الشروكي إلى الإنجليزية مع تقدير الجودة والتغذية الراجعة التصحيحية
Shiyue Zhang Benjamin Frey Mohit Bansal
نشر نموذج Qwen2-7B-Instruct-GPTQ-Int4 التجريبي بنقرة واحدة
الملخص
نقدّم ChrEnTranslate، وهو نظام عرض لترجمة الآلة عبر الإنترنت يهدف إلى الترجمة بين اللغة الإنجليزية واللغة المهددة بالانقراض تشيروكي. يدعم النظام كلًا من نماذج الترجمة الإحصائية والعصبية، كما يوفر تقديرًا للجودة لإبلاغ المستخدمين بمستوى الموثوقية، وواجهتي تغذية راجعة للمستخدمين المخصصتين على التوالي للخبراء والمستخدمين العاديين، وإدخالات نموذجية لجمع الترجمات البشرية الخاصة بالبيانات أحادية اللغة، وتصور محاذاة الكلمات، والمصطلحات ذات الصلة من القاموس التشيروكي-الإنجليزي. تُظهر التقييمات الكمية أن نماذج الترجمة الأساسية لدينا تحقق أداءً ترجميًا في طليعة الأداء الحالي، وأن تقدير الجودة لدينا يتناسب بشكل جيد مع كل من درجة BLEU والحكم البشري. ومن خلال تحليل 216 قطعة من تغذية الخبراء الراجعة، نجد أن الترجمة العصبية للآلة (NMT) مفضلة لأنها تنسخ أقل من الترجمة الإحصائية للآلة (SMT)، وبشكل عام، يمكن للنماذج الحالية ترجمة أجزاء من الجملة المصدرية لكنها ترتكب أخطاءً كبيرة. وعند إضافة هذه النصوص المتوازية المصححة من قبل الخبراء وعددها 216 مرة أخرى إلى مجموعة التدريب وإعادة تدريب النماذج، نلاحظ أداءً مساويًا أو أفضل قليلاً، مما يشير إلى إمكانية التعلم الذي يدمج الإنسان في الحلقة (human-in-the-loop).
One-sentence Summary
ChrEnTranslate is an online English-Cherokee machine translation system that supports statistical and neural models alongside quality estimation and separate expert and general user feedback interfaces, with quantitative evaluations demonstrating state-of-the-art translation performance, quality estimation that correlates with BLEU scores and human judgment, and a human-in-the-loop learning potential evidenced by retraining on 216 expert-corrected translations that yields equal or improved results.
Key Contributions
- ChrEnTranslate is an online demonstration platform for English-Cherokee machine translation that integrates statistical and neural models with quality estimation, word alignment visualization, and specialized feedback interfaces for experts and general users.
- The system implements a human-in-the-loop pipeline that captures expert corrections to iteratively retrain translation models, demonstrating that incorporating 216 manually verified parallel texts into the training data yields equal or improved translation accuracy.
- Quantitative evaluations confirm that the backbone translation models achieve state-of-the-art performance and that the quality estimation module achieves moderate to strong correlations with both BLEU scores and human judgment.
Introduction
Machine translation has matured into a standard tool for global communication, yet it largely overlooks low-resource languages like Cherokee, which UNESCO classifies as endangered. This technological gap directly threatens language revitalization efforts because digital translation aids remain unavailable for communities that rely heavily on elder-led instruction and immersion programs. Prior translation models struggle with severely limited parallel corpora and typically depend on expensive human quality ratings that are impractical to collect for indigenous languages. To bridge this divide, the authors develop ChrEnTranslate, the first online Cherokee-English translation platform that integrates statistical and neural machine translation backbones with built-in quality estimation. By deploying both BLEU-based and uncertainty-driven quality metrics, the system actively warns users when outputs fall below reliable thresholds. The authors also engineer a human-in-the-loop feedback framework that captures expert corrections and user ratings, enabling continuous model refinement while preserving linguistic heritage and offering a scalable template for other low-resource language pairs.
Dataset
- Dataset Composition and Sources: The authors use 17,000 parallel texts originally sourced from the WMT campaign, which typically pairs machine-translated outputs with human quality ratings.
- Subset Details: The corpus is divided into a 16,000-example training set and a 1,000-example evaluation set.
- Data Usage and Processing: To train a supervised quality estimation model, the authors replace missing human ratings with BLEU scores as a quality proxy. They generate these scores through a 17-fold cross validation workflow, training a translation model on 16 folds to produce translations and BLEU metrics for the held out fold, repeating the cycle until all 17,000 examples are scored before applying the final 16,000 to 1,000 split.
- Feature Extraction and Metadata Construction: The authors extract lightweight SMT-specific features optimized for online inference to prevent latency spikes. Each example includes the output length, raw scoring components for distortion, language modeling, lexical reordering, phrase penalty, translation model, and word penalty, alongside length normalized variants of these metrics. They explicitly exclude computationally expensive features like dropout estimators to maintain real time performance.
Method
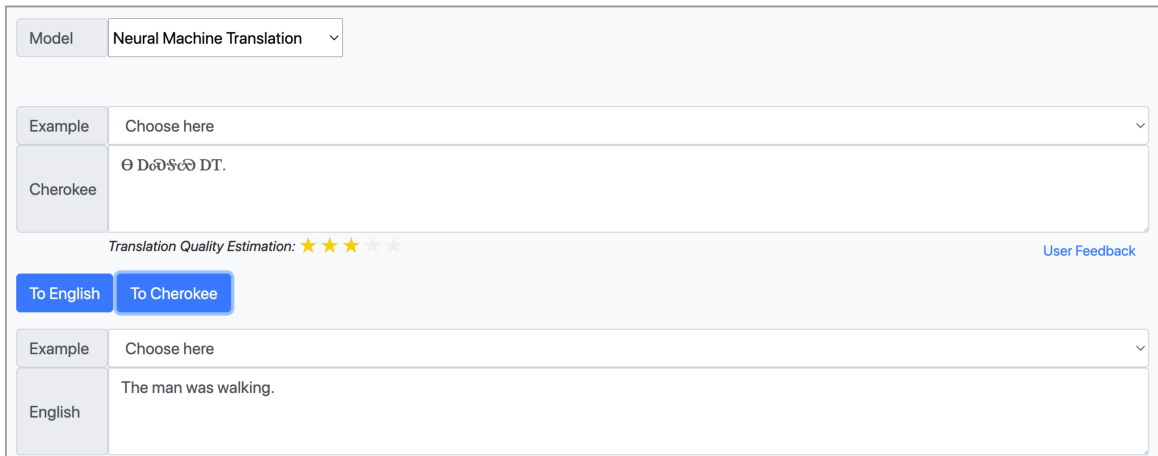
The authors leverage a dual-model framework that supports both statistical machine translation (SMT) and neural machine translation (NMT) approaches, allowing users to select the most appropriate model based on the translation scenario. As shown in Figure 1, the system integrates these two paradigms, with SMT being particularly effective for out-of-domain translation between Cherokee and English. The SMT implementation is based on a phrase-based model using Moses, where a 3-gram language model is trained with KenLM and word alignment is learned via GIZA++. Model weights are optimized on a development set using MERT.
For in-domain translation, the system employs NMT, which demonstrates superior fluency and performance. The authors adopt the global attentional model introduced by Luong et al. (2015), noting that the Transformer architecture performs empirically worse in their experiments. They do not employ multilingual techniques, as these only significantly enhance performance when trained on multilingual Bible texts, potentially introducing a bias toward Bible-style language. Instead, the NMT models are trained exclusively on the provided Cherokee-English parallel corpora. To improve robustness, the final NMT system uses an ensemble of three models.

Quality estimation (QE) is integrated into the system to assess translation output quality. For NMT, the authors consider multiple features: output length, log probability and length-normalized log probability, probability and length-normalized probability, and attention entropy, defined as:
−Lt1i=1∑Ltj=1∑Lsαijlogαijwhere Ls is the source text length and αij represents the attention weight between target token i and source token j. These features are fed into an XGBoost regressor to predict BLEU scores, which are then rescaled to a 0–5 star scale by dividing the predicted BLEU score (0–100) by 20. This provides a visual quality indicator within the system.
Unsupervised QE methods are also explored, motivated by the limitation of requiring large amounts of human-rated data for supervised approaches. The authors investigate uncertainty estimation as a proxy for quality. While output probability is commonly used as a confidence measure, it is often poorly calibrated for language generation tasks. Instead, they consider ensemble-based uncertainty estimation, where the model’s output probability across multiple forward passes is used to quantify uncertainty. This method is found to be simple yet effective and is normalized by sentence length. The normalized probability (0–1) is rescaled to a 0–5 scale by multiplying by 5.

To evaluate the quality estimation system, human ratings are collected from 200 translated sentences—50 each for Cherokee-English SMT, English-Cherokee SMT, Cherokee-English NMT, and English-Cherokee NMT. These ratings, provided by Prof. Benjamin Frey, use a direct assessment setup similar to that of FLoRes, with scores ranging from 0 to 100.
Experiment
The evaluation setup employs a held-out development set to assess statistical and neural translation models alongside quality estimation tools, validating their practical reliability through expert feedback and human judgment correlations. Qualitative analysis indicates that while neural models are favored for minimizing direct source copying, both systems predominantly translate isolated fragments and frequently produce major errors or archaic phrasing due to dataset biases. Nevertheless, reintegrating expert-corrected translations into the training pipeline yields equal or improved performance, confirming the viability of human-in-the-loop learning for advancing endangered language translation.
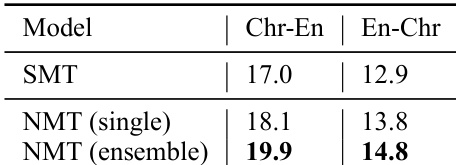
The authors evaluate translation models for Cherokee-English translation using both statistical and neural approaches, with results showing that neural models achieve higher performance and better alignment with human judgments. The study includes expert feedback on translation quality and examines the impact of incorporating corrected translations into the training data. The results indicate that neural models are preferred due to less copying from the source and improved translation of fragments, though they still make significant errors. Neural models outperform statistical models in translation quality and alignment with human judgments. Expert feedback reveals that models often translate fragments correctly but make major errors, particularly with archaic English terms. Incorporating expert-corrected translations into training leads to equal or slightly improved performance.
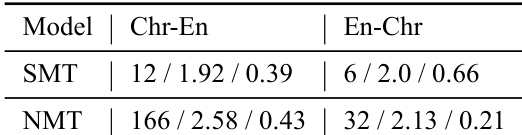
The authors compare statistical and neural translation models for Cherokee-English translation, evaluating their performance on a development set. Results show that neural models achieve higher translation quality than statistical models, with ensemble NMT models outperforming single models. The translation quality is further analyzed through expert feedback, which reveals that models often translate fragments correctly but make significant errors, and that incorporating expert corrections improves performance. Neural translation models outperform statistical models in translation quality. Ensemble neural models achieve higher performance than single models. Expert feedback indicates that models often translate fragments correctly but make major errors.
The authors present a translation system for Cherokee-English with both statistical and neural models, evaluating quality estimation and translation performance. Results show that supervised quality estimation performs better for SMT, while unsupervised methods correlate better with human ratings for NMT, with NMT achieving higher BLEU and human ratings than SMT. Supervised quality estimation performs better for SMT, while unsupervised methods show stronger correlation with human ratings for NMT. NMT models achieve higher BLEU and human ratings compared to SMT models. Unsupervised quality estimation methods show moderate to strong correlation with human judgments for NMT, but weaker for SMT.
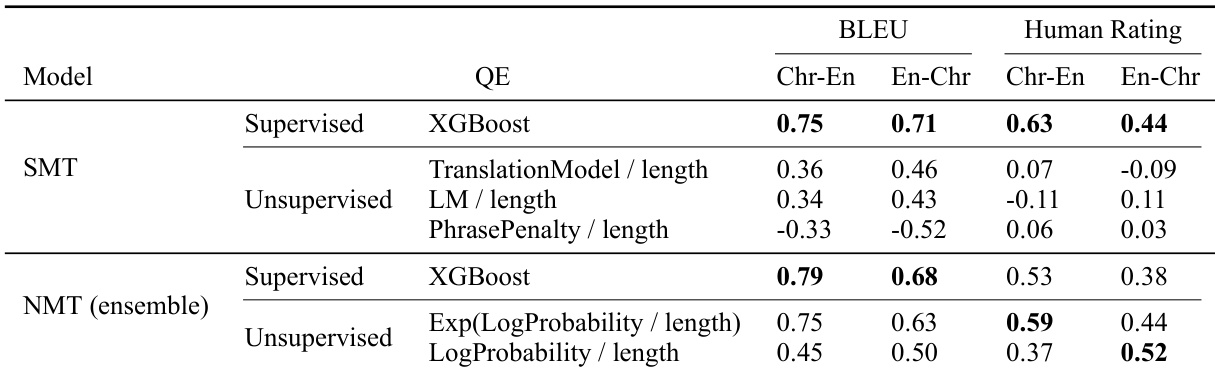
The evaluation compares statistical and neural translation systems for Cherokee-English, validated through expert feedback and quality estimation analysis. Qualitative results indicate that neural approaches consistently deliver superior translation quality and stronger alignment with human judgments compared to statistical methods, with ensemble configurations providing additional gains. While models effectively handle fragmented phrases, they frequently struggle with complex or archaic terminology, and integrating expert corrections into the training data sustains or slightly enhances overall performance. Furthermore, quality estimation strategies diverge by architecture, as supervised methods prove more effective for statistical models while unsupervised techniques correlate more closely with human ratings for neural systems.