Command Palette
Search for a command to run...
Please provide the title you would like me to translate.
Please provide the title you would like me to translate.
الانحدار اللوجستي باستخدام مجموعة بيانات تايتانيك من كاجل
الملخص
Please provide the title and abstract you would like me to translate.
One-sentence Summary
The authors propose a combined latent factor and logistic regression model for citation networks that captures main technological trends and ad-hoc dependencies through a convex joint-likelihood with penalty terms, enabling efficient estimation of low-dimensional latent components and sparse graphical structures, as validated by simulations and application to a real citation network of statisticians.
Key Contributions
- The proposed model integrates a latent factor model with logistic regression to jointly capture dominant technological trends and sparse, ad-hoc dependencies within citation networks.
- Parameter estimation employs a convex joint-likelihood objective augmented with penalty terms, enabling an efficient algorithm that enforces low-dimensional latent components and sparse graphical structures.
- The method is validated through simulations demonstrating practical effectiveness and applied to a citation network of statisticians to report structural findings.
Introduction
Citation analysis plays a critical role in evaluating scholarly impact, guiding funding decisions, and mapping scientific collaboration networks. Traditional bibliometric methods often rely on raw citation counts or isolated statistical techniques that struggle to capture the underlying structure of research communities and the probabilistic nature of academic referencing. To address these limitations, the authors leverage a combined latent and logistic regression model that performs factor analysis directly on citation data. This unified approach simultaneously uncovers hidden scholarly themes and models citation probability, delivering a more accurate and interpretable framework for analyzing academic influence.
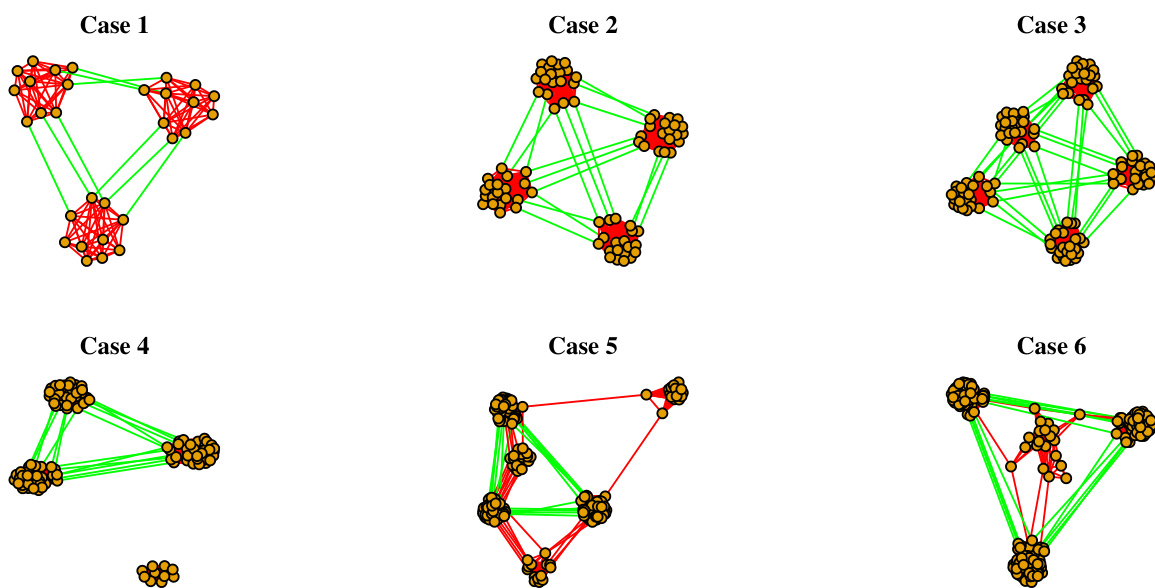
Dataset

-
Dataset Composition and Sources: The authors construct a fully synthetic dataset consisting of six citation networks designed to simulate academic publishing patterns. Rather than drawing from real-world repositories, the data is algorithmically generated to provide controlled ground truth for testing network inference models.
-
Subset Details: The dataset is divided into two experimental scenarios, each containing three networks:
- Scenario 1 includes networks of 30, 80, and 120 papers with 3, 4, and 5 embedded topics respectively. All papers in these subsets are assigned to exactly one topic, with 9, 18, and 30 ad-hoc links connecting the topic clusters.
- Scenario 2 features networks of 120, 210, and 210 papers, all structured around 3 topics. These subsets introduce topic mixing by randomly assigning two or three topics to a controlled subset of papers while the remainder retain single-topic assignments. Each network maintains exactly 18 ad-hoc cross-cluster links.
-
Data Usage and Generation Pipeline: The authors use these networks to calibrate and evaluate a logistic regression model for network reconstruction. Instead of standard train-test splits, the synthetic graphs serve as controlled testbeds where ground truth parameters are sequentially initialized. The intercept term is sampled from a uniform distribution to minimize artificial edge density, while the mixture ratios of single-topic to multi-topic papers in Scenario 2 are explicitly tuned to test how well the model disentangles shared latent factors from direct citations.
-
Processing and Metadata Construction: Topic assignments are encoded in a binary factor loading matrix that enforces strict clustering, and factor weights are drawn from a uniform distribution to maintain group cohesion. Cross-cluster citations are generated by randomly pairing nodes from different topics, with connection probabilities calculated via a logistic function that combines the intercept, topic factors, and weights. The resulting upper-triangular adjacency matrix is populated using Bernoulli trials and symmetrized to form the final undirected graph. A centering transformation is also applied to the factor matrix to standardize the underlying topic structure before final network assembly.
Method
The proposed model integrates a latent factor model with a logistic regression framework to analyze citation networks, addressing limitations inherent in using either approach alone. The framework is designed to capture both global structural trends and local, ad-hoc dependencies within the network. At its core, the model assumes that the binary adjacency matrix X, representing citations between n nodes, arises from a combination of two components: a low-rank latent structure and a sparse residual structure. The latent component is modeled through a factor analysis approach, where each node is associated with a set of underlying topics (factors) via a factor loading matrix F∈RK×n, and the influence of these topics is weighted by a diagonal matrix D∈RK×K. The resulting interaction term FTDF captures the main technological trends in the network. Simultaneously, a sparse matrix S∈Rn×n is introduced to model direct, non-factor-based dependencies between nodes, effectively representing ad-hoc citation links. The joint probability of the observed network is formulated as a logistic regression model, where the log-odds of a citation between nodes i and j is given by the sum of the global intercept α, the latent factor interaction fiTDfj, and the ad-hoc term Sij.
The estimation process begins by defining a penalized log-likelihood function that combines the likelihood of the observed data with regularization terms to promote desirable properties in the estimated components. The log-likelihood function, after appropriate transformation, is expressed in terms of the parameters α, the low-rank matrix L=FTDF, and the sparse matrix S. To ensure identifiability and computational tractability, the latent matrix L is treated as a general low-rank matrix rather than being explicitly decomposed into F and D. The objective function is then minimized subject to penalty terms: an L1 norm on S to enforce sparsity and a nuclear norm on L to promote low rank. This formulation results in a convex optimization problem, which allows for the development of an efficient algorithm. The convexity of the objective function is preserved by the convexity of the logistic loss and the convexity of the regularization terms.
The optimization is performed using the alternating direction method of multipliers (ADMM), a technique well-suited for problems with structured convex objectives. The method decomposes the problem into simpler subproblems that can be solved iteratively. The linear terms in α, L, and S in the objective function allow for efficient updates, while the convexity of the logistic loss ensures convergence. The ADMM framework facilitates the handling of the non-smooth L1 and nuclear norm penalties through augmented Lagrangian techniques. The algorithm iteratively updates estimates of α, L, and S, and the convergence of the method is guaranteed due to the convexity of the overall objective. The resulting estimators α, L, and S provide a decomposition of the network structure into a low-rank component capturing the main technological trends and a sparse component capturing the remaining, more specific dependencies. The rank of the estimated L serves as an estimate of the number of underlying topics, while the non-zero entries in S reveal the ad-hoc connections. The model's theoretical properties, including non-asymptotic error bounds, are established under standard assumptions, ensuring the consistency of the estimators.
Experiment
The experimental evaluation assesses the proposed method through controlled tests on synthetic graphical structures and a real-world citation network for statisticians. These setups validate the model's structural accuracy and practical applicability across varying data complexities. The results demonstrate consistent performance across both scenarios, confirming the method's robustness and suitability for both theoretical analysis and real-world network applications.
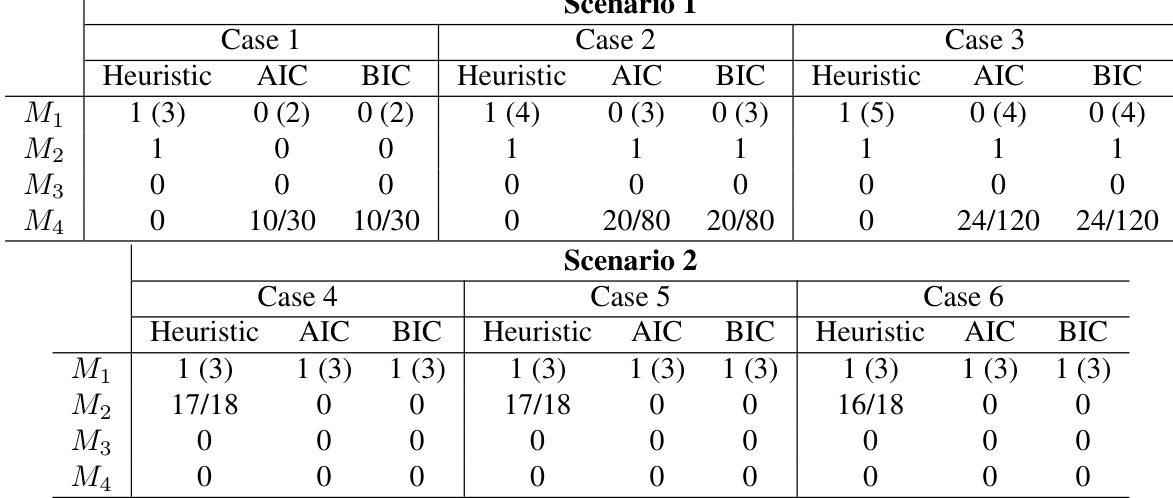
The authors present experimental results from synthetic network scenarios, comparing different model selection methods across multiple cases. The the the table shows varying performance of heuristic, AIC, and BIC criteria in selecting models, with some methods consistently outperforming others in specific scenarios. The heuristic method shows strong performance across various cases, often selecting the correct model. AIC and BIC criteria exhibit lower success rates compared to the heuristic method in most scenarios. Performance varies significantly between cases, indicating sensitivity to the underlying network structure.
The authors evaluated model selection methods across synthetic network scenarios to determine how effectively heuristic, AIC, and BIC criteria identify the correct underlying structure. The results demonstrate that the heuristic approach consistently outperforms both AIC and BIC, which show notably lower success rates in most tested cases. Ultimately, the experiments reveal that selection accuracy is highly dependent on the specific network topology, establishing the heuristic method as the most reliable option across varying conditions.