Command Palette
Search for a command to run...
التحسين التدريجي لنظام الإجابة على الأسئلة عن طريق إعادة ترتيب مرشحات الإجابة باستخدام التعلم الآلي
التحسين التدريجي لنظام الإجابة على الأسئلة عن طريق إعادة ترتيب مرشحات الإجابة باستخدام التعلم الآلي
Michael Barz Daniel Sonntag
نموذج إعادة ترتيب المرشحين
الملخص
ننفذ طريقة لإعادة ترتيب أفضل 10 نتائج لنظام أسئلة وأجوبة (QA) متقدم. الهدف من نهج إعادة الترتيب لدينا هو تحسين اختيار الإجابة بناءً على سؤال المستخدم والمرشحين العشرة الأوائل. نركز على تحسين أنظمة الأسئلة والأجوبة المُنتشرة التي لا تسمح بإعادة التدريب أو عندما تكون إعادة التدريب مكلفة للغاية. يتعلم نهج إعادة الترتيب لدينا دالة تشابه باستخدام ميزات تعتمد على n-gram، مع استخدام الاستعلام والإجابة وثقة النظام الأولية كمدخلات. مساهماتنا هي: (1) إنشاء مجموعة تدريب للأسئلة والأجوبة بدءاً من 877 إجابة من مجال خدمة العملاء في T-Mobile النمسا، (2) تنفيذ خط أنابيب أسئلة وأجوبة متقدم باستخدام تضمينات الجمل العصبية التي تشفر الاستعلامات في نفس الفضاء الذي يُستخدم لفهرسة الإجابات، و(3) تقييم خط أنابيب الأسئلة والأجوبة ونهج إعادة الترتيب لدينا باستخدام مجموعة اختبار مُقدمة بشكل منفصل. يمكن اعتبار مجموعة الاختبار متاحة بعد نشر النظام، على سبيل المثال، بناءً على ملاحظات المستخدمين. تُظهر نتائجنا أن أداء النظام، من حيث دقة أفضل n وتردد الرتبة العكسي المتوسط، يستفيد من إعادة الترتيب باستخدام أشجار الانحدار المعززة بالتدرج. في المتوسط، يتحسن تردد الرتبة العكسي المتوسط بنسبة 9.15%.
One-sentence Summary
By training gradient boosted regression trees on n-gram features derived from queries, answers, and initial confidence scores, this study demonstrates that re-ranking the top-10 candidates of a deployed question answering system yields a 9.15% average improvement in mean reciprocal rank on a T-Mobile Austria customer care dataset without requiring costly model retraining.
Key Contributions
- A dedicated training corpus of 877 question-answer pairs is constructed from the T-Mobile Austria customer care domain to support retrieval-based question answering.
- A post-deployment re-ranking algorithm is introduced that employs gradient boosted regression trees to learn a similarity function from n-gram features of queries, candidate answers, and initial confidence scores.
- Evaluations on a held-out test set derived from actual user chat logs demonstrate that the re-ranking step enhances retrieval performance, achieving an average 9.15% improvement in mean reciprocal rank without requiring base model retraining.
Introduction
The authors address the challenge of incrementally enhancing deployed question answering systems in industrial customer care environments, where effectively managing the long tail of frequent queries directly impacts service reliability. While prior approaches rely on knowledge base maintenance, self-reflective meta-models, or human-in-the-loop crowdsourcing, these methods typically require extensive architectural modifications or continuous external oversight, making them difficult to integrate into live production pipelines. To overcome these constraints, the authors introduce a lightweight post-deployment re-ranking module that applies an n-gram based similarity model to re-order answer candidates from an existing retrieval system. This approach enables automated, feedback-driven adaptation of the QA pipeline, demonstrating how targeted re-ranking can substantially improve answer selection without disrupting established workflows or requiring full model retraining.
Dataset
- Dataset composition and sources: The authors construct two anonymized corpora drawn from internal customer care records and real-world chat logs.
- Subset details: The training set contains 877 customer care answers paired with 3,338 extracted keywords or key-phrases. Students augment this baseline by adding two natural example queries per answer, yielding 5,092 total queries. The team creates three training versions by combining keywords with varying sample counts: keywords only (3,338 items), keywords plus one user sample (4,215 items), and keywords plus two user samples (5,092 items). The evaluation set comprises 3,084 real user requests from T-Mobile Austria chat logs, with domain experts manually mapping each query to up to three relevant training answers.
- Data usage and processing: For training, the authors treat the combined questions and keywords as inputs and the corresponding answers as outputs, testing across all three corpus versions. The evaluation corpus measures baseline QA pipeline performance and validates the re-ranking approach through cross-validation, using expert mappings as offline human feedback. To handle the high frequency of typos in the chat logs, the pipeline incorporates a custom spell-checking component.
- Additional processing and metadata: Both corpora undergo full anonymization before use. The training data relies on keyword/key-phrase tags as structural metadata, and the augmentation strategy is designed to be scalable through crowdsourcing for future production deployments.
Method
The authors leverage a two-stage architecture for improving a question answering (QA) system, where the initial QA pipeline produces a ranked list of top-10 answer candidates, which are then refined through a re-ranking process. The overall framework integrates a baseline QA system with a post-processing re-ranking module that operates on the outputs of the initial system. The baseline QA system, as shown in the framework diagram, begins with a user question that first passes through a spellchecker module designed to correct common spelling errors. This is followed by a pre-processing stage that prepares the query for feature encoding, which differs depending on the underlying pipeline. For the spacy_sklearn pipeline, Spacy’s German language model is used for tokenization and document generation, with feature encoding derived as the mean of pre-trained word embeddings. In contrast, the tensorflow_embedding pipeline employs a simple whitespace tokenizer and uses Scikit-learn’s CountVectorizer to generate a bag-of-words representation. Both pipelines proceed to a text classification stage, where the spacy_sklearn pipeline uses a support vector classifier (SVC) and the tensorflow_embedding pipeline employs a StarSpace-based embedding model to learn query and answer representations. The classification outputs confidence scores that are used to rank the top-10 answers.

Following the initial ranking, the re-ranking module takes the top-10 results along with their confidence scores as input. As shown in the figure below, the re-ranking model operates by learning a similarity function that evaluates the alignment between the user question and each answer candidate, incorporating both the answer text and the initial confidence score. The model is trained on manually annotated data that provides ideal rankings derived from human feedback, allowing it to learn a more accurate ranking function. The re-ranking algorithm processes each candidate by computing a similarity score based on n-gram features extracted from both the query and the answer, including unigrams, bigrams, and trigrams. Three distance metrics are used as features: the Jaccard distance, cosine similarity, and the number of n-gram matches. These features are fed into a gradient boosted regression tree to predict a refined confidence score for each candidate. The final ranking is obtained by sorting the candidates according to their re-ranked scores in descending order. This approach enables the system to improve the quality of the top results without requiring retraining of the initial QA model.
Experiment
The baseline evaluation tested multiple QA pipeline configurations and training corpora to establish a robust foundation for subsequent experiments, ultimately selecting a TensorFlow embedding model enhanced with spell-checking and user annotations. The re-ranking evaluation then validated whether a secondary ranking model could enhance the system's deployed performance by reordering the initial top-10 candidates through cross-validation. Qualitative results demonstrate that while the re-ranking approach consistently improves ranking accuracy and reciprocal rank, the overall gains remain modest due to feature simplicity and the constraint of operating solely within the pre-ranked results. Consequently, the study concludes that re-ranking offers a viable but incremental enhancement for existing QA systems, highlighting the need for advanced feature engineering, meta-models for error detection, and active learning strategies to achieve more substantial performance breakthroughs.
The authors evaluate a question answering system by comparing baseline performance with a re-ranking approach, showing consistent improvements across most metrics when re-ranking is applied. The re-ranking method enhances top-1 to top-9 accuracy and mean reciprocal rank, with diminishing gains at higher ranks, while top-10 accuracy remains unchanged due to the constraint of selecting only from top-10 candidates. Re-ranking improves top-1 to top-9 accuracy and mean reciprocal rank compared to the baseline. The improvement diminishes as the rank increases, with no gain in top-10 accuracy. The re-ranking method operates within the top-10 candidate set, limiting its ability to improve beyond existing results.
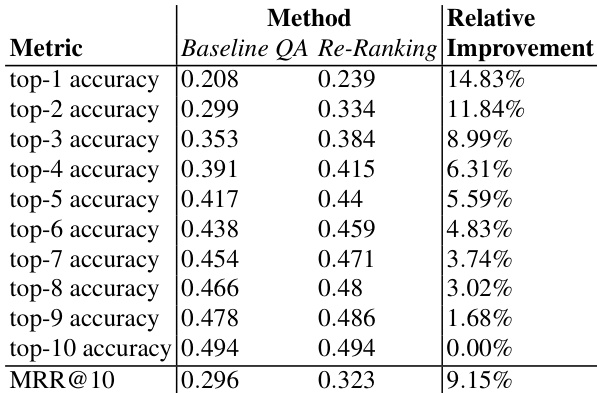
The authors evaluate different configurations of question answering pipelines, focusing on the impact of training data, spell-checking, and model architecture on performance metrics such as accuracy and mean reciprocal rank. The tensorflow embedding pipeline with spell-checking and 100 epochs achieves the best results, which is selected as the baseline for re-ranking experiments. The re-ranking approach consistently improves performance, particularly for top-1 accuracy, but the gains diminish for higher ranks and remain limited due to constraints on the candidate set. Performance improves with more user annotations and the use of spell-checking across pipeline configurations. The tensorflow embedding pipeline outperforms the spacy sklearn pipeline, especially with spell-checking and appropriate training epochs. Re-ranking enhances top-1 accuracy and mean reciprocal rank, but improvements are limited for higher ranks and do not extend beyond the top-10 candidates.
The authors evaluate the performance of question answering pipelines using different configurations and training corpora, focusing on accuracy and mean reciprocal rank metrics. Results show that incorporating user annotations and spell-checking improves performance, with the tensorflow embedding pipeline outperforming the spacy sklearn pipeline. Re-ranking the top-10 results consistently improves accuracy and MRR, though the gains diminish for higher ranks. Incorporating user annotations and spell-checking improves the performance of both baseline pipelines. The tensorflow embedding pipeline consistently outperforms the spacy sklearn pipeline across all configurations. Re-ranking the top-10 results improves accuracy and MRR, with the highest gains observed at lower ranks.
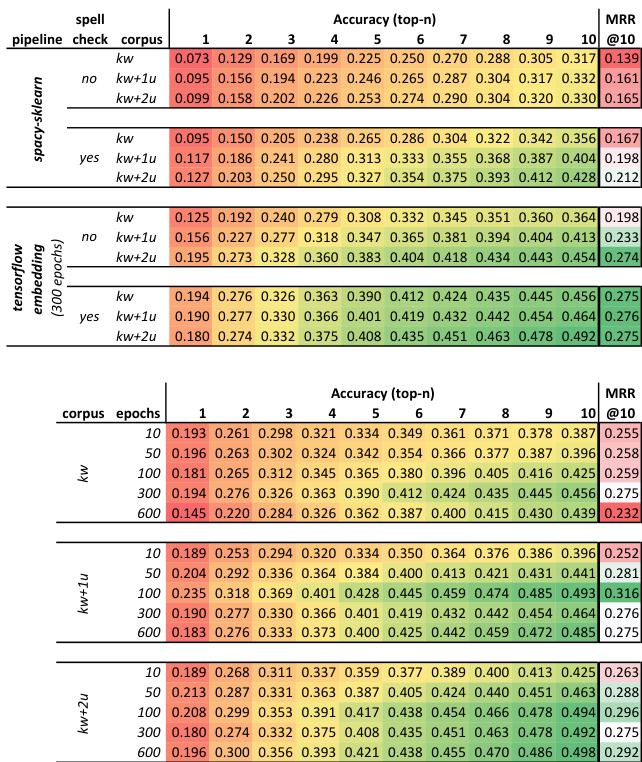
The experiments evaluate question answering systems by testing various pipeline configurations, including different embedding architectures, spell-checking integration, training epochs, and user annotations, alongside a re-ranking strategy applied to the top candidate results. The configuration trials validate that the TensorFlow-based pipeline consistently outperforms the SpaCy alternative, particularly when augmented with spell-checking and adequate training data. The re-ranking evaluation confirms that post-processing the initial candidate set effectively elevates the accuracy of top-ranked answers, although its impact naturally plateaus at deeper ranks due to the fixed selection boundary. Overall, the findings demonstrate that integrating robust foundational models with targeted refinement steps yields the most reliable question answering performance.