Command Palette
Search for a command to run...
تصنيف التعليقات السامة عبر اللغات باستخدام الجigsaw: EDA + النموذج
الملخص
Please provide the title and abstract you would like me to translate.
One-sentence Summary
The authors propose CLANN, a cross-language adversarial neural network that employs adversarial training to learn features discriminative for question-question similarity reranking yet invariant across languages, achieving sizable improvements over a strong non-adversarial baseline when adapting from labeled source data to unlabeled target data in community question answering.
Key Contributions
- Introduces a cross-language adaptation framework for question-question similarity reranking that leverages labeled source-language training data and only unlabeled target-language data.
- Proposes the cross-language adversarial neural network (CLANN), which applies adversarial training to learn high-level features that are discriminative for similarity matching while remaining invariant across input languages.
- Demonstrates through empirical evaluation that this adversarial approach yields sizable performance improvements over strong non-adversarial baseline systems.
Introduction
The authors tackle the challenge of cross-language adaptation for question similarity reranking in community question answering systems. Building multilingual NLP pipelines traditionally requires expensive per-language annotations or relies on machine translation, which often degrades semantic quality and introduces unintended sentiment shifts. To bypass these bottlenecks, the authors leverage adversarial training to learn a unified representation that remains highly discriminative for similarity classification while staying invariant across English and Arabic inputs. By pairing a task-specific neural network with a language discriminator and applying gradient reversal during backpropagation, their CLANN model effectively adapts to a target language using only unlabeled examples. This approach eliminates the need for costly translation pipelines or extensive target-language labeling, delivering performance that closely matches strong monolingual baselines.
Dataset
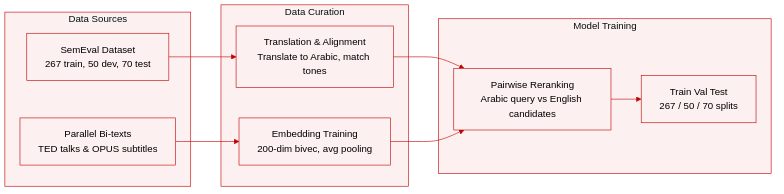
The authors construct a cross-language question similarity reranking dataset built upon the SemEval-2016 Task 3 benchmark. They simulate a multilingual retrieval scenario by professionally translating the original English questions into Arabic, then using those Arabic queries to rank English candidate questions.
• Dataset Composition and Sources: The core dataset originates from SemEval-2016 Task 3, augmented with an additional unlabeled collection of English questions. For bilingual representation learning, the authors extract parallel Arabic-English bi-texts from TED talk transcripts and OPUS movie subtitles, selecting these conversational corpora to closely match the informal tone of community question answering forums.
• Subset Breakdown: The benchmark provides 267 training, 50 development, and 70 test questions. Each input question is paired with 10 IR-retrieved candidate questions, yielding 2,670, 500, and 700 candidates per split. The supplementary unlabeled set adds 221 English questions with 1,863 corresponding candidates, all translated into Arabic to expand model exposure.
• Data Processing and Representation: Question-level representations are generated by averaging the word embeddings of all tokens within a question. The authors train 200-dimensional Arabic-English cross-language embeddings using the bivec framework, applying a context window of 5 and iterating for 5 epochs. A bilingual dictionary is extracted from the parallel corpora to anchor the shared embedding space.
• Model Usage and Training Setup: The data is structured for pairwise reranking, where the model compares an Arabic input question against its English candidates. The averaged cross-language embeddings enable direct semantic comparison across languages, allowing the system to rank English candidates based on their similarity to the Arabic query during training and evaluation.
Method
The authors leverage a cross-language adversarial neural network (CLANN) framework to address the problem of cross-language question-question similarity reranking in community question answering. The model is designed to adapt a system trained on a source language (English) to a target language (Arabic) using labeled data from the source and only unlabeled data from the target. The architecture takes as input a question pair (q,q′), where q is the new question in the target language (Arabic) and q′ is a retrieved question in the source language (English). Both questions are first mapped to fixed-length vectors zq and zq′ using pre-trained word embeddings, which can be derived from monolingual or cross-lingual embedding models.
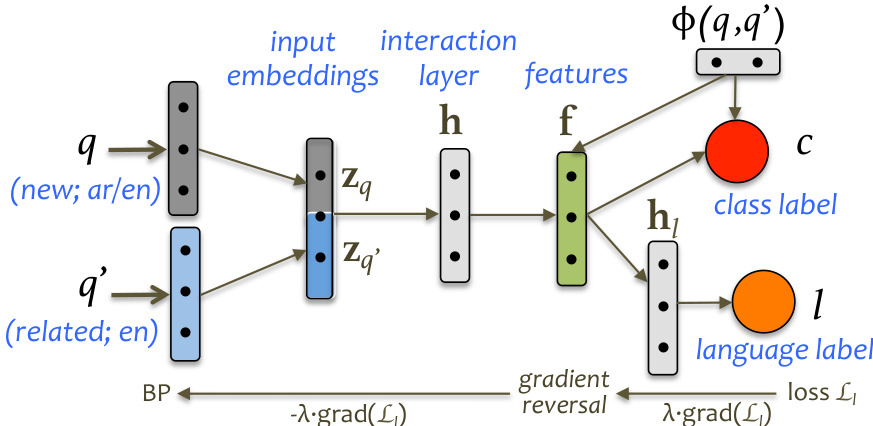
Refer to the framework diagram. The input embeddings are passed through a shared interaction layer, which consists of two non-linear hidden layers. The first hidden layer computes h=g(U[zq;zq′]), where U is the weight matrix and g is a ReLU activation function. The second hidden layer computes f=g(V[h;ϕ(q,q′)]), where V is the weight matrix and ϕ(q,q′) represents a set of pairwise features encoding similarity and task-specific properties between the two questions. These pairwise features are concatenated with the representation from the first hidden layer and also directly fed into the output layer.
The output layer computes a sigmoid score c^θ=sigmoid(wT[f;ϕ(q,q′)]), which estimates the posterior probability p(c=1∣q,q′,θ) for the class label c (1 for similar, 0 for not similar). The model is trained to minimize the negative log-likelihood of the gold labels, Lc(θ)=−clogc^θ−(1−c)log(1−c^θ).
To achieve language-invariant representations, the framework incorporates a language discriminator network that takes the internal representation f as input and attempts to classify the language of the input question q (English or Arabic). This discriminator computes a language label l using a sigmoid function, l^ω=sigmoid(wlThl), where hl=g(Ulf). Its loss, Ll(ω)=−llogl^ω−(1−l)log(1−l^ω), is used to train the discriminator to distinguish the source from the target language.
The overall training objective combines the classification and language discrimination losses: L(θ,ω)=∑nLcn(θ)−λ[∑nLln(ω)+∑n=N+1MLln(ω)]. The model is trained via a min-max optimization, where the shared parameters {U,V,w} are optimized to minimize the combined loss, while the discriminator parameters {Ul,wl} are optimized to maximize it. This is implemented through gradient reversal, where the gradients of the language loss Ll(ω) are reversed when backpropagated to the shared layers, effectively making the task classifier learn representations that are adversarial to the language discriminator. The training process uses stochastic gradient descent with a dynamic weighting schedule for the hyperparameter λ to balance the two components.
Experiment
The experiments evaluate a cross-language question similarity framework by comparing a cross-language adversarial network against a standard feed-forward baseline across both English-Arabic and Arabic-English directions. The setup validates the effectiveness of adversarial adaptation in two scenarios: an unsupervised setting using only unlabeled target data and a semi-supervised setting that supplements this with a subset of labeled target examples. The results indicate that adversarial training consistently outperforms the baseline even with reduced source data. Additionally, incorporating limited labeled target examples successfully restores performance to levels comparable to full supervised training, demonstrating the framework's robustness and adaptability for cross-language applications.
The authors compare the performance of their cross-language adversarial network (CLANN) against a feed-forward neural network (FNN) in both unsupervised and semi-supervised settings across two language directions. Results show that CLANN consistently outperforms FNN, with semi-supervised training yielding improvements over unsupervised adaptation and bringing performance close to that achieved with full labeled training data. CLANN outperforms FNN in both unsupervised and semi-supervised settings across language directions. Semi-supervised training with labeled data from the target language improves performance over unsupervised adaptation. The gains from semi-supervised training are consistent and significant, approaching the performance of models trained on full labeled data.
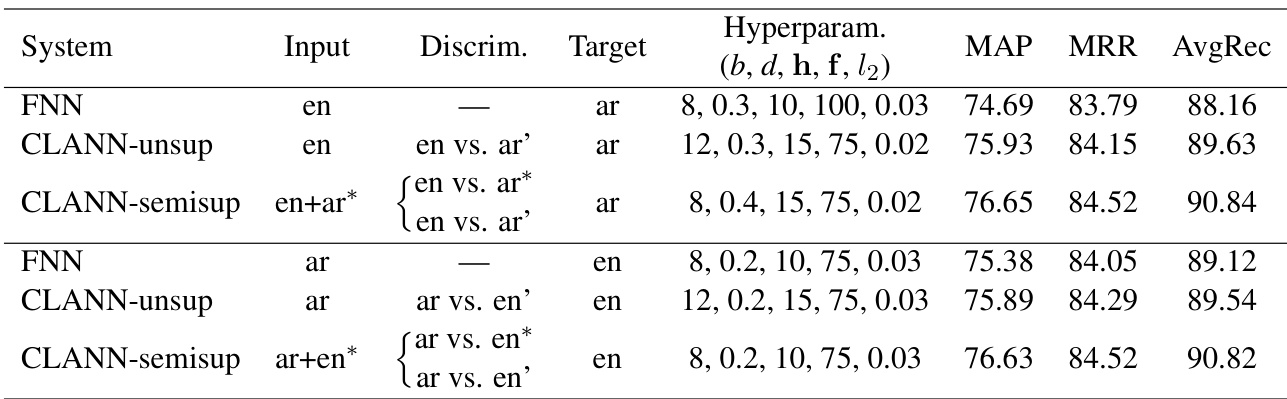
The authors compare the performance of their cross-language adversarial network (CLANN) against a feed-forward neural network (FNN) in both unsupervised and semi-supervised settings across two language directions. Results show that CLANN consistently outperforms FNN, with improvements observed across all evaluation metrics, and that semi-supervised training further enhances performance compared to unsupervised adaptation. CLANN outperforms FNN in both language directions and across all evaluation metrics. Semi-supervised training with labeled data from the target language boosts performance compared to unsupervised adaptation. The adversarial framework effectively leverages both labeled and unlabeled data in cross-language settings.

The authors present cross-language adaptation results comparing their CLANN model to a baseline FNN, showing improvements in performance when using adversarial adaptation. The results demonstrate that CLANN outperforms the baseline across multiple evaluation metrics in both language directions, with consistent gains in unsupervised and semi-supervised settings. CLANN achieves higher performance than the baseline FNN in cross-language adaptation tasks. The model shows consistent improvements across evaluation metrics in both language directions. Adversarial adaptation provides a significant boost in performance compared to non-adversarial methods.
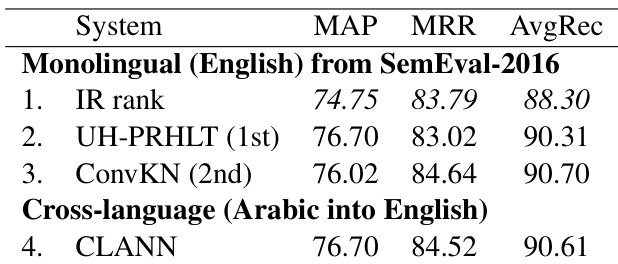
The experiments evaluate a cross-language adversarial network against a standard feed-forward baseline across two language directions in both unsupervised and semi-supervised settings. The results validate that adversarial adaptation significantly enhances cross-language transfer compared to non-adversarial approaches, with the model consistently outperforming the baseline. Incorporating limited target-language labels further improves adaptation, demonstrating that semi-supervised training effectively bridges the performance gap between unsupervised methods and fully supervised models. Overall, the framework successfully leverages both labeled and unlabeled data to achieve robust cross-lingual generalization.