Command Palette
Search for a command to run...
مقارنة بين طرق إعادة أخذ العينات والتجزئة المتكررة في الغابة العشوائية لتقدير التباين المقارب باستخدام السكين اللانهائي الصغر
مقارنة بين طرق إعادة أخذ العينات والتجزئة المتكررة في الغابة العشوائية لتقدير التباين المقارب باستخدام السكين اللانهائي الصغر
Cole Brokamp MB Rao Patrick Ryan Roman Jandarov
غابة عشوائية مطبقة على مجموعة بيانات LendingClub
الملخص
العنوان: (لم يتم توفير عنوان)
الملخص: تم مؤخراً تطبيق طريقة المقشر اللانهائي الصغر (Infinitesimal Jackknife - IJ) على غابات عشوائية لتباين التنبؤ الخاص بها. وقد تم التحقق من صحة هذه النظريات ضمن إطار عمل الغابات العشوائية التقليدي الذي يستخدم أشجار التصنيف والانحدار (CART) وإعادة أخذ العينات بالتبديل (bootstrap resampling). ومع ذلك، فقد تبين أن الغابات العشوائية التي تستخدم أشجار الاستدلال الشرطي (CI trees) وأخذ العينات الجزئية (subsampling) أقل عرضة لتحيز اختيار المتغيرات. في هذا البحث، أجرينا تجارب محاكاة باستخدام نهج جديد لاستكشاف قابلية تطبيق طريقة IJ على الغابات العشوائية التي تستخدم اختلافات في طريقة إعادة أخذ العينات والمتعلم الأساسي (base learner). تم محاكاة نقاط بيانات الاختبار، وتم تدريب كل منها باستخدام الغابات العشوائية على مئة مجموعة بيانات تدريب محاكاة، باستخدام تركيبات مختلفة من طرق إعادة أخذ العينات والمتعلمين الأساسيين. وقد أدى استخدام أشجار الاستدلال الشرطي بدلاً من أشجار CART التقليدية، وكذلك استخدام أخذ العينات الجزئية بدلاً من إعادة أخذ العينات بالتبديل، إلى تقدير أكثر دقة لتباين التنبؤ عند استخدام طريقة IJ. وقد تم دمج اختلافات الغابات العشوائية المذكورة هنا في حزمة برمجيات مفتوحة المصدر للغة البرمجة R.
One-sentence Summary
Simulation experiments demonstrate that applying the infinitesimal jackknife to random forests using conditional inference trees and subsampling yields significantly more accurate prediction variance estimates than traditional CART and bootstrap approaches, with these methodological variations now incorporated into an open-source R package.
Key Contributions
- This study establishes a simulation framework to evaluate the infinitesimal jackknife method for estimating prediction variance in random forests that replace traditional CART trees with conditional inference trees and bootstrap resampling with subsampling.
- Experiments across one hundred simulated training datasets demonstrate that combining conditional inference trees with subsampling produces much more accurate infinitesimal jackknife variance estimates than standard random forest configurations.
- The evaluated algorithmic variations are implemented in an open-source R package to facilitate practical deployment of the improved variance estimation technique.
Introduction
Random forests are widely deployed for predictive modeling, but accurately quantifying prediction uncertainty remains critical for reliable machine learning inference. While earlier research established that the infinitesimal jackknife can estimate prediction variances for standard random forests, its performance with modern algorithmic variants has not been rigorously validated. The authors leverage simulation experiments to evaluate the infinitesimal jackknife when paired with alternative resampling strategies like subsampling and different tree-building algorithms such as conditional inference trees. This analysis addresses a key methodological gap by determining whether these widely adopted modifications maintain accurate uncertainty quantification.
Dataset
- Dataset Composition and Sources: The authors generate entirely synthetic data using mathematical simulation functions rather than importing external records. The dataset consists of ten predictor variables sampled from normal distributions and eleven distinct synthetic outcomes created through predefined simulation rules.
- Subset Details: The data is organized into thirty-three unique dataset types, formed by combining eleven simulation functions with three training sample sizes (n=200, 1000, and 5000). Predictors X1 through X5 follow a standard normal distribution (mean 0, variance 1), while X6 through X10 are drawn from a normal distribution with a mean of 10 and variance of 5 to introduce a wider value range. Each simulation function utilizes a specific subset of predictors, indicated by the number in the dataset name, though all ten variables are supplied to the random forest model during training.
- Data Usage and Processing: The authors split the generated data into training sets of varying sizes and fixed evaluation sets. For each simulation function, they generate one hundred independent test points to assess prediction accuracy. The training sets are sampled repeatedly across the three specified sizes to evaluate model performance under different data volume conditions.
- Additional Processing Details: The synthetic outcomes are constructed using logical and arithmetic operations on the predictors. Logical combinations use indicator functions to represent AND and OR conditions, while arithmetic combinations apply SUM and SQ (sum of squares) transformations. The number embedded in each dataset name reflects how many predictors are actively involved in that specific simulation function, and no external filtering or cropping is applied since the pipeline relies entirely on controlled mathematical generation.
Method
The authors leverage a framework that integrates random forest predictions with variance estimation techniques to assess prediction uncertainty. The overall process begins with a distribution from which 100 test sets are generated. Each test set is used to produce 100 predictions and 100 variance predictions, forming the basis for subsequent analysis. The framework computes the empirical variance of these 100 predictions, which serves as an estimate of the variance of the prediction function. This variance is then combined with the absolute bias of the predictions to produce 100 absolute bias estimates. The average of these absolute bias estimates across all 100 estimates yields the empirical predictive bias.
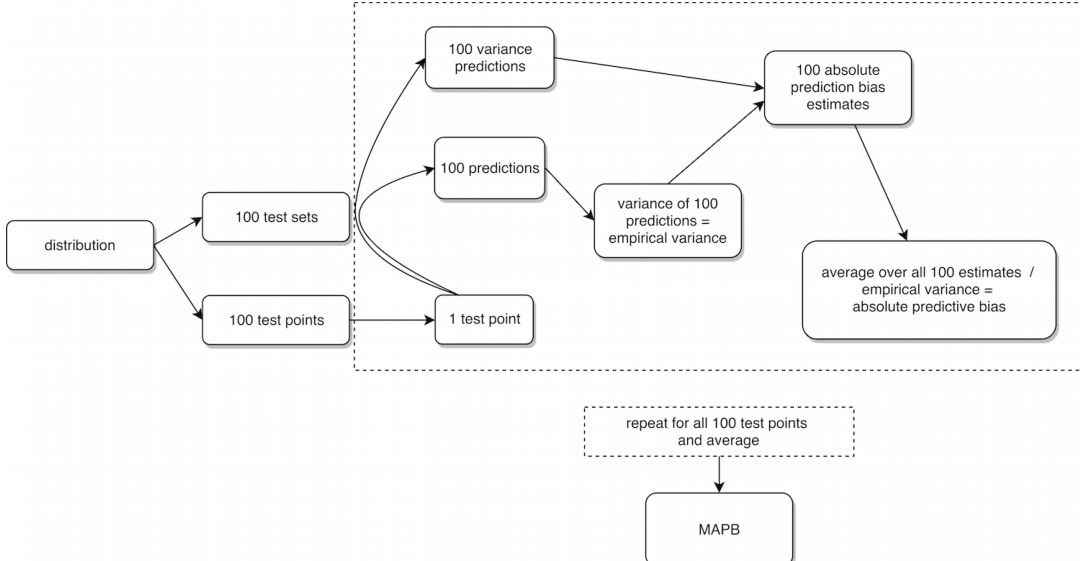
The process is repeated for all 100 test points, and the results are averaged to produce a final measure, referred to as MAPB. This iterative procedure ensures that the framework captures the variability and bias across the entire test set, providing a comprehensive assessment of prediction performance. The framework emphasizes the importance of both variance and bias in evaluating the reliability of predictions, particularly in the context of ensemble methods like random forests.
Experiment
The study evaluates the accuracy of random forest prediction variance estimation through simulations that systematically vary tree types, resampling methods, feature selection parameters, sample sizes, and underlying data distributions. These experimental variations validate the robustness of the variance estimator by demonstrating that conditional inference trees consistently reduce bias compared to traditional CART models, and that subsampling dramatically outperforms bootstrap sampling by enhancing tree decorrelation. Ultimately, the findings confirm that combining conditional inference trees with subsampling provides the most reliable variance estimates across diverse conditions, validating theoretical proofs while highlighting the performance limitations of bootstrap resampling in complex scenarios.
The authors conducted simulation experiments to evaluate the mean absolute predictive bias (MAPB) of variance estimates in random forests under different configurations, including tree type, resampling method, and sample size. Results show that subsampling consistently outperformed bootstrap sampling in reducing bias, and conditional inference trees generally led to lower bias than traditional CART trees across all conditions. Subsampling resulted in lower mean absolute predictive bias compared to bootstrap sampling across all conditions. Conditional inference trees consistently produced lower bias than traditional CART trees regardless of other simulation factors. The impact of sample size on bias varied by data distribution, with some showing increased bias at larger sample sizes.
The authors compare the performance of random forest variants using different tree types, resampling methods, and sample sizes, focusing on the mean absolute predictive bias as a measure of variance estimation accuracy. Results show that conditional inference trees and subsampling consistently reduce bias compared to traditional CART trees and bootstrap sampling, with the resampling method having the most significant impact on performance. Conditional inference trees consistently outperform traditional CART trees in reducing predictive bias across all distributions and sample sizes. Subsampling leads to lower bias than bootstrap sampling, with the best subsampling performance exceeding the worst bootstrap performance. The impact of increasing the number of variables used in tree splits is more pronounced with bootstrap sampling than with subsampling, especially for certain data distributions.
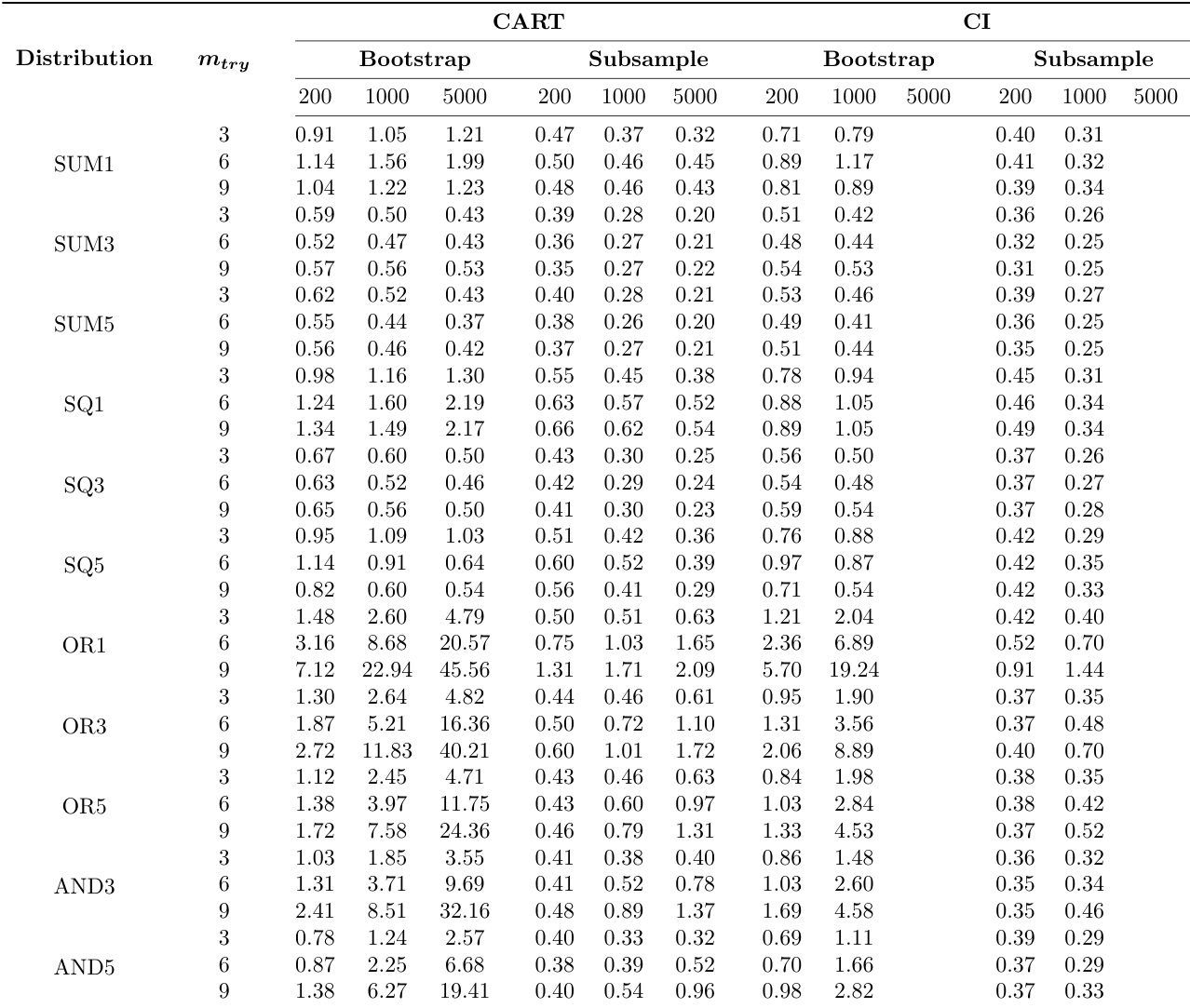
The authors conducted simulation experiments to evaluate the mean absolute predictive bias of variance estimates in random forests using different tree types, resampling methods, and parameter settings. Results show that conditional inference trees consistently outperform traditional CART trees, and subsampling leads to significantly lower bias compared to bootstrap resampling across all conditions. Conditional inference trees consistently reduce bias compared to traditional CART trees regardless of resampling method or sample size. Subsampling results in substantially lower bias than bootstrap resampling, with the best subsampling performance surpassing the best bootstrap performance in all cases. Increasing the number of variables used in the simulation functions leads to higher bias when using bootstrap resampling, particularly with conditional inference trees.

The authors analyze the empirical variance of random forest predictions across different data distributions and sample sizes, observing that the variance is generally lower for OR and AND distributions compared to SUM and SQ distributions, particularly as sample size increases. The results show that the empirical variance decreases with larger sample sizes for SUM and SQ distributions, but increases for OR and AND distributions, likely due to their lower baseline variance. These trends are consistent with the observed patterns in the mean absolute predictive bias. The empirical variance is consistently lower for OR and AND distributions compared to SUM and SQ distributions, especially at larger sample sizes. The empirical variance decreases with increasing sample size for SUM and SQ distributions, but increases for OR and AND distributions. The median empirical variance is higher for distributions involving more variables and wider ranges, particularly in SUM5 and SQ5.
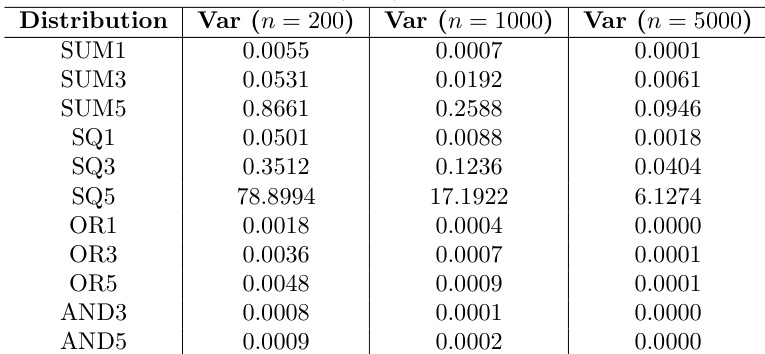
Simulation experiments assessed variance estimation accuracy in random forests by systematically varying tree architectures, resampling strategies, sample sizes, and underlying data distributions. The results validate that conditional inference trees and subsampling consistently yield lower predictive bias than traditional CART models and bootstrap resampling, with the resampling approach exerting the strongest performance influence. Additionally, empirical variance trajectories closely mirror bias patterns, demonstrating that distribution characteristics and sample size interact to produce divergent scaling behaviors rather than uniform improvements.