Command Palette
Search for a command to run...
أطلقت شركة Google DeepMind تطبيق Perch 2.0، الذي يغطي ما يقرب من 15000 نوع، مما يمثل حالة جديدة من التطور في التصنيف والكشف الحيوي الصوتي.

تلعب الصوتيات الحيوية، كأداة مهمة تربط بين علم الأحياء والبيئة، دورًا محوريًا في الحفاظ على التنوع البيولوجي ورصده. اعتمدت الأبحاث المبكرة على أساليب معالجة الإشارات التقليدية، مثل مطابقة القوالب، مما كشف تدريجيًا عن محدوديتها بسبب عدم كفاءتها ونقص دقتها في ظل البيئات الصوتية الطبيعية المعقدة والبيانات واسعة النطاق.
في السنوات الأخيرة، دفع النمو الهائل لتكنولوجيا الذكاء الاصطناعي (AI) التعلم العميق وغيره من الأساليب إلى استبدال الأساليب التقليدية، لتصبح أدوات أساسية لكشف وتصنيف الأحداث الصوتية الحيوية. على سبيل المثال، أظهر نموذج BirdNET، المُدرّب على بيانات صوتية مُصنّفة للطيور على نطاق واسع، أداءً استثنائيًا في التعرف على بصمات أصوات الطيور: فهو لا يُميّز بدقة أصوات الأنواع المختلفة فحسب، بل يُمكّن أيضًا من تحديد هوية كل طائر إلى حد ما. علاوة على ذلك، حققت نماذج مثل Perch 1.0، من خلال التحسين والتكرار المستمرين، إنجازاتٍ قيّمة في مجال الصوتيات الحيوية، مُقدّمةً دعمًا تقنيًا قويًا لرصد التنوع البيولوجي والحفاظ عليه.
منذ بضعة أيام،Perch 2.0، الذي تم إطلاقه بشكل مشترك من قبل Google DeepMind وGoogle Research،يرتقي برنامج Perch 2.0 بأبحاث الصوتيات الحيوية إلى آفاق جديدة، إذ يعتمد تصنيف الأنواع كمهمة تدريبية أساسية. فهو لا يقتصر على دمج بيانات تدريب إضافية من مجموعات غير طيورية فحسب، بل يستخدم أيضًا استراتيجيات جديدة لزيادة البيانات وأهدافًا تدريبية.لقد قام هذا النموذج بتحديث SOTA الحالي في معيارين حيويين صوتيين موثوقين، BirdSET وBEANS.ويظهر هذا المنتج إمكانات أداء قوية وآفاق تطبيق واسعة.
وقد تم نشر نتائج البحث ذات الصلة كنسخة أولية على arXiv تحت عنوان "Perch 2.0: The Bittern Lesson for Bioacoustics".
عنوان الورقة:
https://arxiv.org/abs/2508.04665
اتبع الحساب الرسمي ورد "Bioacoustics" للحصول على ملف PDF كامل
مجموعة البيانات: معيار بناء وتقييم بيانات التدريب
دمجت هذه الدراسة أربع مجموعات بيانات صوتية مُسمّاة لتدريب النموذج: Xeno-Canto، وiNaturalist، وTierstimmenarchiv، وFSD50K.يُشكلان معًا الدعم الأساسي للبيانات لتعلم النماذج. وكما هو موضح في الجدول أدناه، يُعدّ Xeno-Canto وiNaturalist مستودعين كبيرين لعلوم المواطنين: الأول يُتاح عبر واجهة برمجة تطبيقات عامة، بينما يُشتقّ الثاني من تسجيلات صوتية مُصنّفة على أنها بحثية على منصة GBIF. يحتوي كلاهما على عدد كبير من التسجيلات الصوتية للطيور وغيرها من الكائنات. كما يُركّز Tierstimmenarchiv، أرشيف أصوات الحيوانات التابع لمتحف برلين للتاريخ الطبيعي، على علم الصوتيات الحيوية. وأخيرًا، يُكمّل FSD50K هذا المجال بمجموعة متنوعة من الأصوات غير المتعلقة بالطيور.
تحتوي هذه الفئات الأربع من البيانات على إجمالي 14,795 فئة.من بين هذه الأنواع، كان 14,597 نوعًا، بينما كانت الـ 198 المتبقية أحداثًا صوتية غير متعلقة بالأنواع. لا يضمن هذا التغطية الشاملة للفئات التعلم العميق للإشارات الصوتية الحيوية فحسب، بل يُوسّع أيضًا نطاق تطبيق النموذج من خلال تضمين بيانات صوتية غير متعلقة بالطيور. ومع ذلك، نظرًا لاستخدام مجموعات البيانات الثلاث الأولى أنظمة تصنيف مختلفة للأنواع، قام فريق البحث يدويًا برسم خرائط وتوحيد أسماء الفئات، وحذف تسجيلات الخفافيش التي لم يكن من الممكن تمثيلها باستخدام معلمات الطيف المحددة لضمان اتساق البيانات وإمكانية تطبيقها.
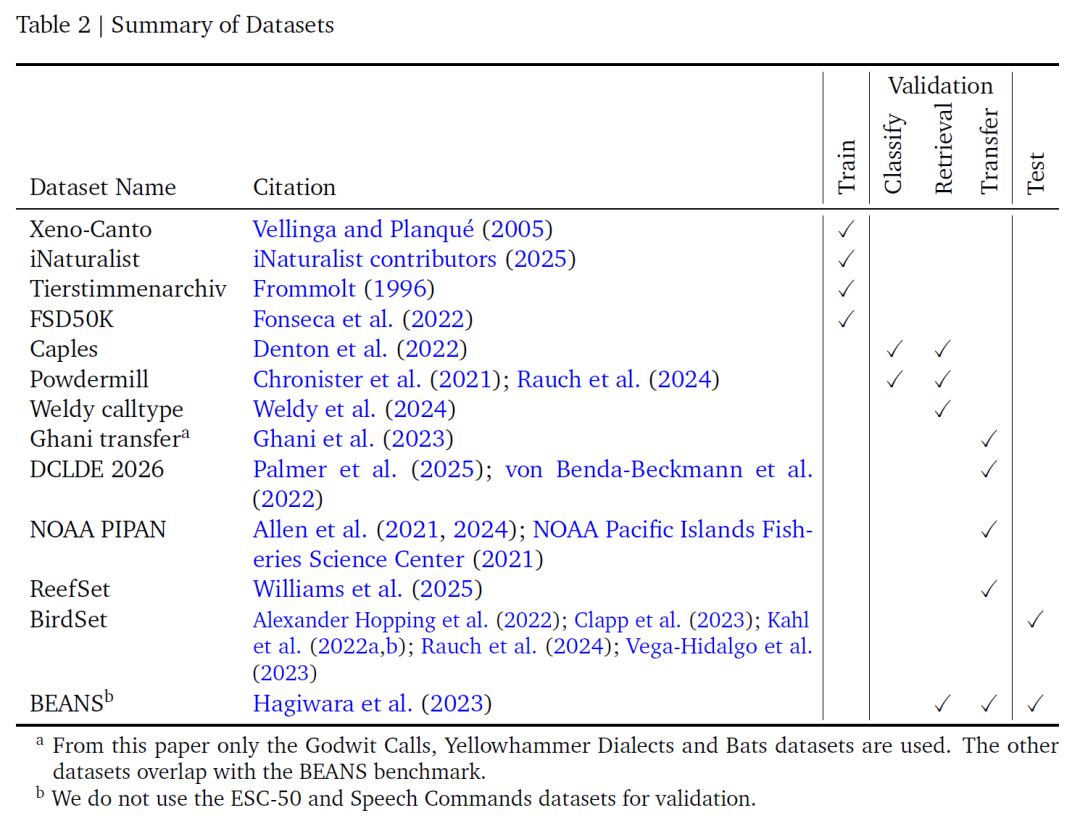
مع الأخذ في الاعتبار أن مدة تسجيل مصادر البيانات المختلفة تختلف بشكل كبير (من أقل من ثانية واحدة إلى أكثر من ساعة، ومعظمها 5-150 ثانية)، ويتم تثبيت النموذج بمقاطع مدتها 5 ثوانٍ كمدخلات،قام فريق البحث بتصميم استراتيجيتين لاختيار النوافذ:استراتيجية النافذة العشوائية تعترض 5 ثوانٍ عشوائيًا عند اختيار تسجيل. مع أن هذا قد يشمل مقاطع لم تُصدر فيها الأنواع المستهدفة أصواتًا، مما قد يُسبب بعض تشويش التسمية، إلا أنه عادةً ما يكون ضمن نطاق مقبول. تتبع استراتيجية ذروة الطاقة فكرة Perch 1.0 وتستخدم تحويل الموجات لاختيار منطقة الـ 6 ثوانٍ ذات الطاقة الأقوى في التسجيل. ثم تُختار 5 ثوانٍ عشوائيًا من هذه المنطقة لتحسين صحة العينة بناءً على افتراض أن "المناطق عالية الطاقة هي الأكثر احتمالًا لاحتواء أصوات الأنواع المستهدفة".تتوافق هذه الطريقة مع منطق تصميم الكاشف للنماذج مثل BirdNET، ويمكنها التقاط الإشارات الصوتية الفعالة بدقة أكبر.
لتحسين قدرة النموذج على التكيف مع البيئات الصوتية المعقدة بشكل أكبر، اعتمد فريق البحث متغيرًا لزيادة البيانات من خلال المزج.إنشاء إشارة مركبة عن طريق مزج نوافذ صوتية متعددة:أولاً، يُحدَّد عدد الإشارات الصوتية المختلطة بأخذ عينات من توزيع بيتا ثنائي الحد، ثم تُؤخَذ عينات من الأوزان عبر توزيع ديريتشليت المتماثل. تُجمَع الإشارات المتعددة المختارة بأوزانها، وتُعَيَّر المكاسب.
بخلاف المزيج الأصلي، تستخدم هذه الطريقة متوسطًا مرجحًا لمتجهات الأهداف متعددة الترددات بدلاً من متجهات الترددات الأحادية، مما يضمن إمكانية تحديد جميع الأصوات داخل النافذة (بغض النظر عن مستوى الصوت) بثقة عالية. إن ضبط المعلمات ذات الصلة كمعلمات فائقة السرعة يُحسّن قدرة النموذج على تمييز الأصوات المتداخلة ويُحسّن دقة التصنيف.
يعتمد تقييم النموذج على معيارين موثوقين: BirdSet وBEANS. يحتوي BirdSet على ست مجموعات بيانات للمناظر الصوتية مُعلّق عليها بالكامل من الولايات المتحدة الأمريكية، وهاواي، وبيرو، وكولومبيا. لا يُجرى أي ضبط دقيق أثناء التقييم، ويُستخدَم مُخرَج مُصنِّف التعلم النموذجي مُباشرةً؛ يُغطِّي BEANS ١٢ مهمة اختبار مُتعدِّدة الفئات (تشمل الطيور، والثدييات البرية والبحرية، والأنورا، والحشرات). تُستخدم مجموعة التدريب الخاصة به فقط لتدريب المجسات الخطية والنماذج الأولية، كما لا تُعَدَّل شبكة التضمين.
Perch 2.0: نموذج تدريب مسبق عالي الأداء للتقنيات الحيوية الصوتية
يتكون نموذج هندسة Perch 2.0 من واجهة أمامية ونموذج تضمين ومجموعة من رؤوس الإخراج.تعمل هذه الأجزاء معًا لتحقيق العملية الكاملة من الإشارة الصوتية إلى تحديد الأنواع.
في،الواجهة الأمامية مسؤولة عن تحويل الصوت الخام إلى نموذج مميز يمكن للنموذج معالجته.يستقبل الصوت الأحادي المأخوذ بتردد 32 كيلو هرتز، وبالنسبة لشريحة مدتها 5 ثوانٍ (تحتوي على 160.000 نقطة أخذ عينات)، فإنه يولد طيفًا لوغاريتميًا يحتوي على 500 إطار و128 نطاقًا من اللوغاريتم لكل إطار من خلال المعالجة بطول نافذة 20 مللي ثانية وطول قفزة 10 مللي ثانية، يغطي نطاق التردد من 60 هرتز إلى 16 كيلو هرتز، مما يوفر ميزات أساسية للتحليل اللاحق.
تستخدم شبكة التضمين بنية EfficientNet-B3هذه شبكة متبقية ملتوية تحتوي على 120 مليون معلمة، مما يزيد من كفاءة المعلمات باستخدام تصميم ملتوي قابل للفصل بعمق. مقارنةً بشبكة EfficientNet-B1 التي تحتوي على 78 مليون معلمة والمستخدمة في الإصدار السابق من Perch، فهي أكبر حجمًا لمواكبة نمو بيانات التدريب.
بعد المعالجة عبر شبكة التضمين، يتم الحصول على تضمين مكاني ذي شكل (5، 3، 1536) (الأبعاد تتوافق مع قنوات الزمن والتردد والخصائص على التوالي). بعد حساب متوسط الأبعاد المكانية، يمكن الحصول على تضمين عالمي ذي 1536 بُعدًا، والذي يُعدّ السمة الأساسية للتصنيف اللاحق.
رأس الإخراج مسؤول عن مهام التنبؤ والتعلم المحددة.يتكون من ثلاثة أجزاء: يقوم المصنف الخطي بإسقاط التضمين العالمي في مساحة فئة ذات 14795 بُعدًا، ومن خلال التدريب، يجعل تضمينات الأنواع المختلفة قابلة للفصل خطيًا، مما يحسن تأثير الكشف الخطي عند التكيف مع المهام الجديدة؛ يأخذ مصنف تعلم النموذج الأولي التضمين المكاني كمدخل، ويتعلم 4 نماذج أولية لكل فئة، ويختار النموذج الأولي ذو أقصى تنشيط للتنبؤ. هذا التصميم مشتق من AudioProtoPNet في مجال الصوتيات الحيوية؛ رأس التنبؤ بالمصدر هو مصنف خطي يتنبأ بمصدر التسجيل الأصلي للمقطع الصوتي بناءً على التضمين العالمي. نظرًا لأن مجموعة التدريب تحتوي على أكثر من 1.5 مليون تسجيل مصدر، فإنها تحقق حسابًا فعالًا من خلال إسقاط منخفض الرتبة للرتبة 512، مما يخدم تعلم خسارة التنبؤ بالمصدر ذاتية الإشراف.
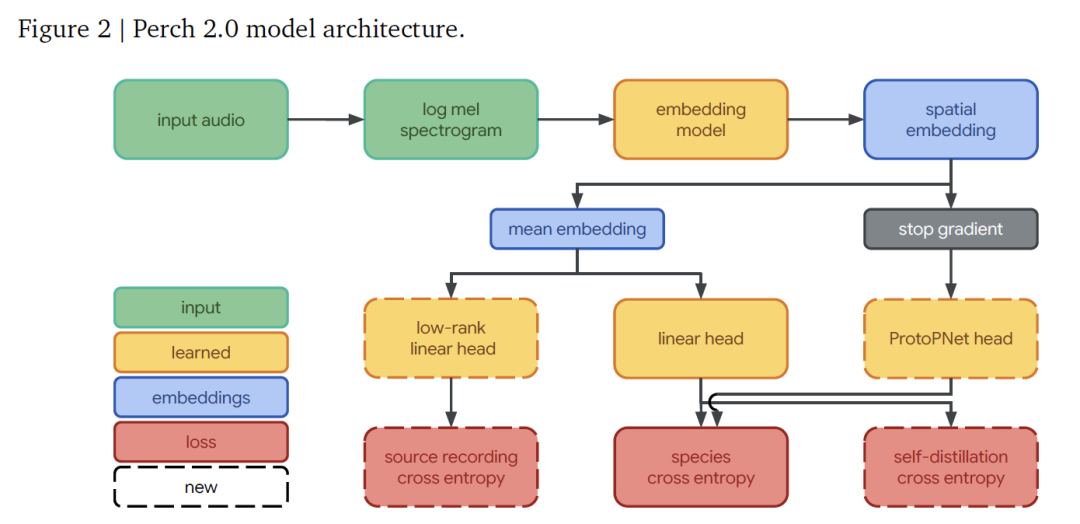
يتم تحسين التدريب النموذجي من البداية إلى النهاية من خلال ثلاثة أهداف مستقلة:
* تستخدم الإنتروبيا المتقاطعة لتصنيف الأنواع تنشيط سوفت ماكس وفقدان الإنتروبيا المتقاطعة للمصنفات الخطية، مما يؤدي إلى تعيين أوزان موحدة للفئات المستهدفة؛
في آلية التقطير الذاتي، يعمل مصنف التعلم النموذجي بمثابة "معلم" حيث تعمل تنبؤاته على توجيه المصنف الخطي "الطالب" مع تعظيم الفرق في النموذج الأولي من خلال الخسارة المتعامدة، ولا ينتشر التدرج مرة أخرى إلى شبكة التضمين؛
* يتم استخدام التنبؤ بالمصدر كهدف خاضع للإشراف الذاتي، مع التعامل مع التسجيلات الأصلية كفئات مستقلة للتدريب، ودفع النموذج لالتقاط الميزات البارزة.
يتم تقسيم التدريب إلى مرحلتين:ركزت المرحلة الأولى على تدريب مصنف التعلم النموذجي (بدون التقطير الذاتي، حتى 300000 خطوة)؛ ومكنت المرحلة الثانية من التقطير الذاتي (حتى 400000 خطوة)، وكلاهما باستخدام مُحسِّن Adam.
يعتمد اختيار المعلمات الفائقة على خوارزمية Vizier.في المرحلة الأولى، يتم البحث عن معدل التعلم ومعدل التسرب، وما إلى ذلك، ويُحدد النموذج الأمثل بعد جولتين من الفرز. في المرحلة الثانية، يُزاد وزن فقدان التقطير الذاتي ويستمر البحث. تُستخدم طريقتا أخذ العينات النافذة طوال العملية.
تُظهر النتائج أن المرحلة الأولى تُفضّل خلط إشارتين إلى خمس إشارات، مع وزن خسارة متوقعة للمصدر يتراوح بين 0.1 و0.9؛ بينما تميل مرحلة التقطير الذاتي إلى امتلاك معدل تعلم منخفض، واستخدام خلط أقل، وإعطاء وزن عالٍ يتراوح بين 1.5 و4.5 لخسارة التقطير الذاتي. تدعم هذه المعلمات أداء النموذج.
تقييم قدرة التعميم لـ Perch 2.0: الأداء الأساسي والقيمة العملية
يركز تقييم Perch 2.0 على قدرته على التعميم، بفحص أدائه في تسجيلات أصوات الطيور (والتي تختلف اختلافًا كبيرًا عن تسجيلات التدريب) ومهام تحديد الأنواع غير المرتبطة بالأنواع (مثل تحديد نوع النداء)، بالإضافة إلى قدرته على الانتقال إلى مجموعات غير طيورية مثل الخفافيش والثدييات البحرية. ونظرًا لأن الممارسين غالبًا ما يتعاملون مع كميات ضئيلة من البيانات المُصنّفة أو معدومة،المبدأ الأساسي للتقييم هو التحقق من فعالية "الشبكة المضمنة المجمدة".وهذا يعني أنه من خلال استخراج الميزات في وقت واحد، يمكن التكيف بسرعة مع المهام الجديدة مثل التجميع والتعلم من العينات الصغيرة.
تتحقق مرحلة اختيار النموذج من الناحية العملية من ثلاثة جوانب:
* أداء المصنف المدرب مسبقًا، باستخدام ROC-AUC لتقييم قدرات التنبؤ بالأنواع الجاهزة على مجموعة بيانات الطيور الموضحة بالكامل؛
* استرجاع عينة واحدة، باستخدام مسافة جيب التمام لقياس التجميع وأداء البحث؛
* الهجرة الخطية، محاكاة سيناريوهات العينة الصغيرة لاختبار القدرة على التكيف.
يتم حساب درجات هذه المهام بالمتوسط الهندسي، وتعكس النتائج النهائية للمجموعات الفرعية الـ19 قابلية الاستخدام الفعلية للنموذج.
وبناءً على معياري BirdSet وBEANS، تظهر نتائج تقييم هذه الدراسة في الجدول التالي:يتمتع Perch 2.0 بأداء متميز في العديد من المؤشرات، وخاصة ROC-AUC، وهو الأفضل في الوقت الحالي.ولا يتطلب الأمر أي ضبط دقيق؛ حيث إن استراتيجيات التدريب الخاصة بنافذتها العشوائية ونافذة ذروة الطاقة لها أداء مماثل، وربما يرجع ذلك إلى أن التقطير الذاتي يخفف من تأثير ضوضاء الملصق.
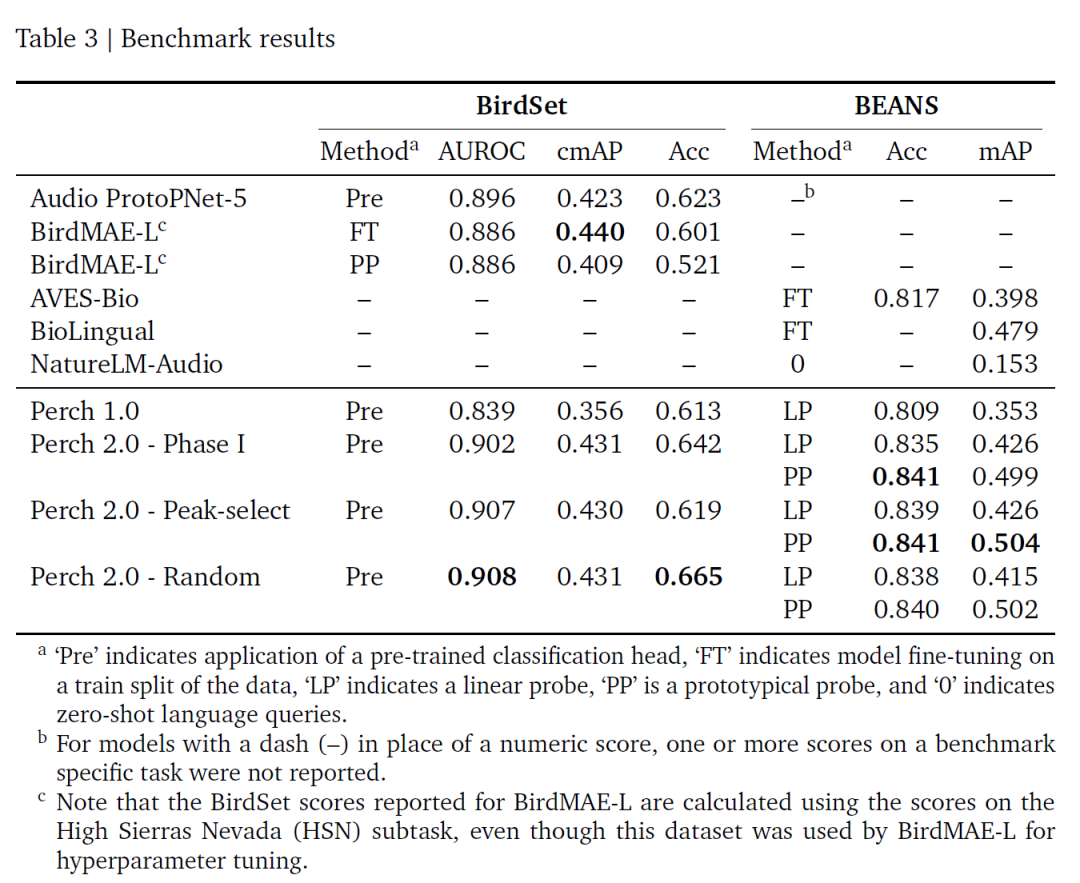
بشكل عام، يعتمد Perch 2.0 على التعلم المُشرف، ويرتبط ارتباطًا وثيقًا بالخصائص الصوتية الحيوية. يُظهر الاختراق الذي حققه Perch 2.0 أنلا يتطلب التعلم الانتقالي عالي الجودة نماذج ضخمة للغاية؛ فالنماذج الخاضعة للإشراف والمضبوطة بدقة جنبًا إلى جنب مع تعزيز البيانات والأهداف المساعدة يمكن أن تحقق أداءً جيدًا.تصميمه الثابت للتضمين (الذي يُغني عن الضبط الدقيق المتكرر) يُقلل من تكلفة معالجة البيانات واسعة النطاق، ويُمكّن من النمذجة الرشيقة. وستشمل التوجهات المستقبلية في هذا المجال بناء معايير تقييم واقعية، وتطوير مهام جديدة باستخدام البيانات الوصفية، واستكشاف التعلم شبه المُشرف.
تقاطع الصوتيات الحيوية والذكاء الاصطناعي
عند تقاطع علم الصوتيات الحيوية والذكاء الاصطناعي، أدت اتجاهات البحث مثل التعلم الانتقالي بين الفئات، وتصميم الهدف الخاضع للإشراف الذاتي، وتحسين شبكة التضمين الثابتة إلى استكشاف واسع النطاق في الأوساط الأكاديمية ومجتمعات الأعمال في جميع أنحاء العالم.
تعمل تقنية التدريب التنافسي الافتراضي لمسافة جيب التمام (CD-VAT) التي طورها فريق جامعة كامبريدج على تحسين القدرة على التمييز بين التضمينات الصوتية من خلال تنظيم الاتساق.يستعيد تحسنًا في معدل الخطأ بنسبة 32.51%TP3T في مهمة التحقق من مكبر الصوت على نطاق واسع،يقدم نموذجًا جديدًا للتعلم شبه الخاضع للإشراف في التعرف على الكلام.
معهد ماساتشوستس للتكنولوجيا ومركز CETI يتعاونان في أبحاث بصمة صوت حوت العنبر.من خلال التعلم الآلي، يتم فصل "أبجدية الصوت" المكونة من الإيقاع والمقياس والارتعاش والزخرفة.وقد تبين أن تعقيد نظام الاتصال لديهم أكبر بكثير من المتوقع - حيث تمتلك قبيلة الحيتان العنبر في شرق البحر الكاريبي وحدها ما لا يقل عن 143 تركيبة صوتية مميزة، كما أن قدرتها على حمل المعلومات تتجاوز حتى البنية الأساسية للغة البشرية.
تمكنت تقنية التصوير الضوئي الصوتي التي طورتها مؤسسة ETH في زيورخ من اختراق حد الحيود الصوتي عن طريق تحميل كبسولات دقيقة بجسيمات نانوية من أكسيد الحديد.تحقيق تصوير فائق الدقة للأوعية الدموية الدقيقة في الأنسجة العميقة (دقة تصل إلى 20 ميكرون)،وقد أظهرت إمكانات المراقبة الديناميكية متعددة المعلمات في علم الدماغ وأبحاث الأورام.
في نفس الوقت،لقد جمع مشروع BirdNET مفتوح المصدر 150 مليون تسجيل في جميع أنحاء العالم.لقد أصبح أداةً مرجعيةً للرصد البيئي. يُمكن تشغيل نسخته الخفيفة، BirdNET-Lite، آنيًا على أجهزة طرفية مثل Raspberry Pi، مما يدعم تحديد أكثر من 6000 نوع من الطيور، ويوفر حلاً منخفض التكلفة لأبحاث التنوع البيولوجي.
يجمع نظام التعرف على أصوات الطيور بالذكاء الاصطناعي الذي نشرته شركة Hylable اليابانية في حديقة Hibiya بين مجموعة متعددة الميكروفونات مع DNN.تحقيق إخراج متزامن لموقع مصدر الصوت وتحديد الأنواع، مع معدل دقة يزيد عن 95%.وقد تم توسيع إطارها الفني ليشمل مجالات التقييم البيئي للمساحات الخضراء الحضرية وبناء المرافق الخالية من العوائق.
ومن الجدير بالذكر أنيستكشف مشروع Zoonomia التابع لشركة Google DeepMind الآليات التطورية للتشابهات الصوتية بين الأنواع من خلال دمج البيانات الجينومية والصوتية من 240 نوعًا من الثدييات.وجدت الدراسة أن توزيع الطاقة التوافقية لنباح الكلاب المبهج (نسبة الطاقة التوافقية من الثالث إلى الخامس 0.78±0.12) متماثل إلى حد كبير مع صفارات الدلافين الاجتماعية (0.81±0.09). لا يوفر هذا الارتباط البيولوجي الجزيئي أساسًا لنموذج الهجرة بين الأنواع فحسب، بل يُلهم أيضًا مسارًا جديدًا لنمذجة "الذكاء الاصطناعي المستوحى بيولوجيًا" - دمج معلومات الشجرة التطورية في تدريب الشبكة المُدمجة، وبالتالي تجاوز قيود النماذج الصوتية الحيوية التقليدية.
تُضفي هذه الاستكشافات بُعدًا جديدًا على دمج علم الصوتيات الحيوية والذكاء الاصطناعي. فعندما يلتقي عمق البحث الأكاديمي مع اتساع نطاق التطبيق الصناعي، تُلتقط وتُفسر إشارات الحياة التي كانت مختبئة في مظلات الغابات المطيرة والشعاب المرجانية في أعماق البحار بشكل أوضح، لتتحول في نهاية المطاف إلى أدلة عملية لحماية الأنواع المهددة بالانقراض وحلول ذكية للتعايش المتناغم بين المدن والطبيعة.
روابط مرجعية:
1.https://mp.weixin.qq.com/s/ZWBg8zAQq0nSRapqDeETsQ
2.https://mp.weixin.qq.com/s/UdGi6iSW-j_kcAaSsGW3-A
3.https://mp.weixin.qq.com/s/57sXpOs7vRhmopPubXTSXQ
امسح رمز الاستجابة السريعة المقابل للوصول إلى أوراق AI4S عالية الجودة من عام 2023 إلى عام 2024 حسب المجال، بما في ذلك تقارير التفسير المتعمق⬇️









