Command Palette
Search for a command to run...
استنادًا إلى أكثر من 176 ألف بيانات نقش، أصدرت Google DeepMind برنامج Aeneas، الذي حقق لأول مرة استعادة طولية عشوائية للنقوش الرومانية القديمة

جميع ذكريات الحضارة الإنسانية المبكرة مُخبأة في النقوش والكلمات. تُعد النقوش من أقدم أشكال الكتابة، إذ تُتيح للناس فرصةً لفهم أفكار الحضارات القديمة ولغتها وتاريخها. من مراسيم الإمبراطور إلى شواهد قبور العبيد، أصبحت هذه الكلمات المنقوشة على الألواح الحجرية والبرونزية دليلاً مباشراً على تحديد العصر وفهم الثقافة. يُقدر اكتشاف 1500 نقش لاتيني جديد سنوياً، إلا أن دراسة النقوش تواجه صعوباتٍ عديدة، مثل عدم اكتمال النصوص، وصعوبة تفسيرها، وقلة المعرفة.
في 23 يوليو 2025، نشر باحثون من Google DeepMind، بالتعاون مع جامعة نوتنغهام وجامعة وارويك وجامعات أخرى، ورقة بحثية بعنوان "وضع النصوص القديمة في سياقها باستخدام الشبكات العصبية التوليدية" في مجلة Nature الأكاديمية الرائدة في العالم.
يتضمن هذا البحث ثلاث نقاط ابتكارية رئيسية:
* يستطيع إينيس استقبال كلٍّ من النصوص المكتوبة وصور النقوش. تُعالَج الصور بواسطة شبكة عصبية بصرية سطحية، وتُدمج مع خصائص نصية، وهو أمرٌ مفيدٌ بشكلٍ خاص لمهام الإسناد الجغرافي.
* في السابق، كان الذكاء الاصطناعي قادرًا فقط على إصلاح النصوص ذات الطول المعروف، لكن إينياس اخترق قيود الإصلاح وكان رائدًا في القدرة على "إصلاح النصوص بأي طول" لأول مرة.
* تكمن قدرة إينياس الأساسية في إيجاد "النصوص المتوازية" الأكثر صلةً بالنقش المستهدف. لا تقتصر هذه النصوص المتوازية على عبارات متشابهة فحسب، بل تغطي أيضًا روابط عميقة كالخلفية الثقافية والوظائف الاجتماعية، متجاوزةً بذلك حدود مطابقة النصوص التقليدية.
هندسة النموذج: الشبكة العصبية التوليدية متعددة الوسائط Aeneas
Aeneas هي شبكة عصبية توليدية متعددة الوسائط.يُستخدم مُفكِّك تشفير قائم على مُحوِّل لمعالجة النص والصور المُدخلة للنقش، وتُستخدم شبكة عصبية بصرية سطحية لاسترجاع نقوش مُماثلة من مجموعة بيانات النقوش اللاتينية وفرزها حسب الصلة. يُعالج الجزء الأساسي من النموذج، "الجذع"، النص المُدخل.
صُمم Aeneas لتحليل سياق النقوش اللاتينية. يتكون هيكله من معالجة الإدخال، والوحدات الأساسية، ورؤوس المهام، وآليات السياق.
معالجة المدخلات:المدخل هو تسلسل أحرف النقش وصورة بدرجات الرمادي 224×224. يصل طول تسلسل الأحرف إلى 768 حرفًا، ويُستخدم الرمز "-" لتمييز الأحرف المفقودة المعروفة الطول، ويُستخدم الرمز "#" لتمييز الأحرف المفقودة غير المعروفة الطول، ويُستخدم الرمز < كعلامة بداية للجملة.
الوحدات الأساسية:يُعالَج النص بواسطة جذع مُحسَّن على مُفكِّك T5 Transformer، مُكوَّن من 16 طبقة، و8 رؤوس انتباه لكل طبقة، مع تضمين دوران الموضع النسبي، وتُعالَج الصورة بواسطة شبكة ResNet-8 البصرية. تُوجَّه مُخرَجات الجذع والشبكات البصرية بعد ذلك إلى شبكات عصبية مُخصَّصة في الرؤوس، والتي تستخدم النص لمعالجة مهام استعادة الحروف وتأريخها، ويُخصَّص كل رأس لمعالجة 3 مهام رئيسية في الكتابة.
رأس المهمة (رئيس المهمة):يتضمن الناتج رؤوس مهام مخصصة لإصلاح النص (بما في ذلك الرؤوس المساعدة لإصلاح الطول غير المعروف، باستخدام البحث الشعاعي لتوليد الفرضيات)، والإسناد الجغرافي (دمج النص والميزات المرئية لتصنيف 62 مقاطعة رومانية)، والإسناد الزمني (رسم تواريخ الخرائط في 160 فترة زمنية منفصلة من العقد)، كل ذلك مع خرائط الأهمية.
آلية السياق:من خلال دمج التمثيل الوسيط للجذع ورأس المهمة لتوليد تضمينات غنية تاريخيًا، يتم استرجاع النقوش المتوازية ذات الصلة بناءً على تشابه جيب التمام لمساعدة المؤرخين في أبحاثهم.
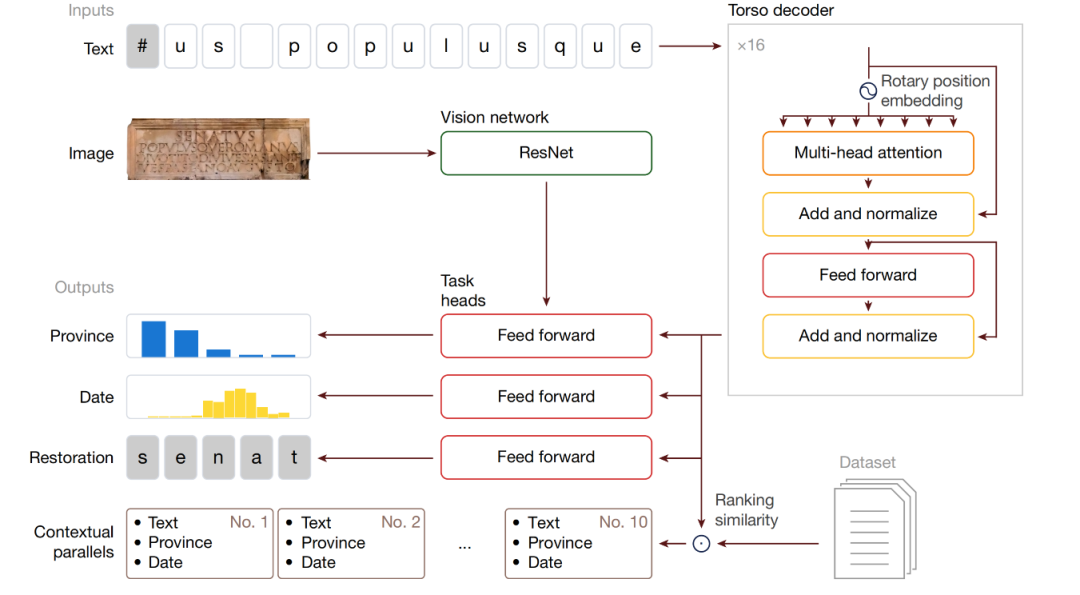
لنأخذ معالجة إينياس لعبارة "Senatus populusque Romanus" كمثال: بالنظر إلى صورة نقش ونسخته النصية (حيث تُميّز الأجزاء التالفة مجهولة الطول بالرمز "#")، يعالج إينياس النص باستخدام الجذوع. تتولى الرؤوس مسؤولية استعادة الأحرف، والتأريخ، والإسناد الجغرافي (تتضمن مهمة الإسناد الجغرافي أيضًا ميزات بصرية). تُدمج التمثيلات الوسيطة للجذوع في متجه تضمين موحد وغني تاريخيًا لاسترجاع نقوش مماثلة من مجموعة بيانات النقوش اللاتينية (LED) وفرزها حسب الصلة.
تجدر الإشارة إلى أنيتضمن نموذج Aeneas إدخالاً إضافيًا من شبكة الرؤية فقط لرؤوس الإسناد الجغرافي؛ ولا تستخدم مهام تلوين النص والإسناد الزمني النمط المرئي.تستبعد مهمة الاستعادة المدخلات البصرية لمنع تسرب المعلومات عن طريق الخطأ. ولأن جزءًا من النص مُقنّع بشكل مصطنع وموقعه الدقيق في الصورة غير معروف، فقد يستخدم النموذج أدلة بصرية لاستنتاج الأحرف المخفية واستعادتها، مما يُعرّض سلامة المهمة للخطر.
مجموعة البيانات: أكبر مجموعة بيانات قابلة للقراءة آليًا للنقوش اللاتينية
وتسمى قاعدة بيانات النصوص المستخدمة لتدريب نموذج إينيس بمجموعة بيانات النقوش اللاتينية (LED) في الدراسة، وهي أكبر مجموعة بيانات للنقوش اللاتينية يمكن تشغيلها آليًا حتى الآن. تأتي بيانات مجموعة بيانات LED الشاملة من أكثر ثلاث قواعد بيانات شاملة للنقوش اللاتينية: قاعدة بيانات النقوش الرومانية (EDR)، وقاعدة بيانات نقوش هايدلبرغ (EDH)، وقاعدة بيانات كلاوس-سلابي، والتي تحتوي على نقوش من القرن السابع قبل الميلاد إلى القرن الثامن الميلادي. ويمتد نطاق التغطية الجغرافية من المقاطعات الرومانية بريتانيا (بريطانيا حاليًا) ولوسيتانيا (البرتغال) غربًا إلى مصر وبلاد ما بين النهرين شرقًا. ولضمان اتساق مجموعة بيانات LED بأكملها، استخدمت الدراسة مُعرّفات في منصة بيانات Trismegistos لمعالجة أي غموض في البيانات، وطبقت مجموعة من قواعد التصفية لمعالجة التعليقات البشرية بشكل منهجي، بحيث يمكن معالجة النص بواسطة الآلات.
للحصول على بيانات وصفية موحدة،قامت الدراسة بتحويل كافة البيانات الوصفية المتعلقة بالتواريخ والفترات التاريخية إلى أرقام تتراوح من 800 قبل الميلاد إلى 800 ميلادي.تم استبعاد النقوش خارج هذا النطاق. ولتحسين قدرات التعلم والتعميم للنموذج، تم تحويل محتوى النص الأساسي في مجموعة البيانات إلى صيغة قابلة للتشغيل الآلي وفقًا للمعيار:
* إزالة أو توحيد تعليقات المؤرخين على النقش والاحتفاظ بالنسخة الأقرب إلى النقش الأصلي.
* لا يتم تحليل الاختصارات اللاتينية، في حين يتم الاحتفاظ بأشكال الكلمات التي تعرض تهجئات بديلة لأسباب زمنية أو ثنائية الاتجاه أو تصريفية حتى يتعلم النموذج الاختلافات الكتابية أو الجغرافية أو الزمنية المحددة.
* الحفاظ على الأحرف المفقودة التي تم استعادتها بواسطة المحرر أو التي لم يتمكن من استعادتها في النهاية، واستخدام علامات الجنيه (#) كعلامات مكانية عندما يكون العدد الدقيق للأحرف المفقودة غير مؤكد، وتقليص المسافات الإضافية لضمان إخراج موجز.
* قم بإزالة الأحرف غير اللاتينية، مع ترك الأحرف اللاتينية فقط، وعلامات الترقيم المحددة مسبقًا، والعناصر النائبة.
* تصفية النقوش المكررة. تُعتبر النصوص التي تتجاوز حد تشابه المحتوى 90% مكررة.
بعد تحويل التنسيق، قامت الدراسة بتقسيم مصابيح LED إلى مجموعات تدريب وتحقق واختبار بناءً على الرقم الأخير من معرف النقش الفريد، مما يضمن توزيعًا متساويًا للصور عبر المجموعات الفرعية.

بعد تنفيذ عملية التصفية التلقائية، حصلت الدراسة على صور نقش قابلة للاستخدام من مجموعة البيانات من خلال تطبيق عتبة على الهيستوغرام اللوني لإزالة الصور المكونة بشكل أساسي من لون نقي واحد، باستخدام تباين مصفوفة لابلاس لتحديد الصور الضبابية والتخلص منها، وتحويل الصور المنظفة إلى صور بدرجات الرمادي. تحتوي مجموعة بيانات LED على إجمالي 176,861 نقشًا، ولكن معظمها تالف جزئيًا، ويمكن فقط لـ 5% نقشًا إنتاج صور مقابلة قابلة للاستخدام.
الاستنتاج/الأداء التجريبي
قام الباحثون بتقييم أداء نموذج إينيس من ثلاثة جوانب: تنفيذ المهمة، وخط الأساس للأسماء، وآلية السياق، وكفاءة البحث.
* علم الأسماء هو دراسة أصل وبنية وتطور ومعنى الأسماء الصحيحة مثل أسماء الأشخاص والأماكن والقبائل والآلهة.
مؤشرات تنفيذ المهام
وتستخدم هذه الدراسة ثلاثة مؤشرات لاستعادة النص، والإسناد الجغرافي والإسناد الزمني لتشكيل إطار تقييمي.ومن بينها، استخدم الباحثون أساليب اصطناعية لتدمير نص بطول تعسفي وأرسلوا النموذج لتوليد كائنات تم إصلاحها؛ وفي مهمة الإسناد الجغرافي، تم استخدام مؤشرات الدقة القياسية Top-1 وTop-3 لتقييم الأداء؛ وبالنسبة لإسناد الوقت، تم استخدام مؤشر قابل للتفسير لتقييم القرب الزمني بين النتائج المتوقعة والبيانات الحقيقية.
تظهر التجارب أن بنية Aeneas توفر قدرات متعددة الوسائط.قادر على استعادة تسلسلات نصية ذات طول غير معروف،كما يمكن تكييفها مع أي لغة قديمة ووسائط مكتوبة مثل ورق البردي والعملات المعدنية، مما يلتقط العلاقة بين النقوش والتاريخ في عملية وضع النصوص القديمة في سياقها.
خط الأساس للأسماء
يصبح التقييم الآلي لبيانات التعريف المستمدة من Onomastics بواسطة نموذج Aeneas مؤشرًا رئيسيًا لقدراته على التنبؤ بالإسناد.نظرًا لعدم وجود قائمة مُجمَّعة مسبقًا للأسماء الرومانية الصحيحة،قام فريق البحث بإزالة 350 عنصرًا يدويًا من مستودع الأسماء الصحيحة والتي لا تمثل الأسماء الصحيحة.تم استبعاد الإدخالات الأقصر أو التي تحتوي على أحرف غير لاتينية بسبب غموض الاستخدام، مما أدى إلى إنشاء قائمة مختارة تضم حوالي 38000 اسم علم.
لتعزيز قوة النهج، تم تحديد الكلمات الأكثر شيوعًا في مجموعة البيانات وتصفيتها لتتكون فقط من إدخالات من قائمة مختارة من الأسماء الصحيحة، وتم بعد ذلك حساب متوسط توزيعها الزمني والجغرافي في مجموعة بيانات التدريب حتى يتمكن نموذج Aeneas من الاستفادة من بيانات الأسماء الصحيحة المعالجة للتنبؤ بتاريخ ومنشأ النقوش الجديدة عند تحليلها.
يمكن تطبيق طريقة تقييم نموذج Aeneas لهذه المهمة على مجموعة البيانات بأكملها وتحقيق قابلية التوسع المحسنة.
آلية السياق وكفاءة البحث
قامت الدراسة بتقييم فعالية آلية وضع السياق لنموذج إينيس كأداة أساسية للبحث التاريخي. وشارك في التقييم 23 من علماء النقوش من خلفيات متنوعة بشكل مجهول.بناءً على الخبرة المكتسبة من تنفيذ ثلاث مهام نقش، تم تقييم كفاءة استخدام آلية سياق إينيس كأداة مساعدة في البحث:
* يمكن لنموذج إينيس أن يقلل بشكل كبير من الوقت المستغرق في البحث عن المعلومات ذات الصلة، مما يسمح للباحثين بالتركيز على التفسير التاريخي الأعمق وبناء أسئلة البحث.
* المعلومات المسترجعة بواسطة نموذج إينيس دقيقة وتوفر رؤى قيمة حول نوع وسياق النقش، مما يساعد على تقدم مهمة البحث.
* يقوم إينياس بتوسيع نطاق البحث وتحسين النتائج من خلال تحديد المعلومات ذات الصلة المهمة ولكن التي لم تتم ملاحظتها سابقًا وميزات النص التي تم تجاهلها.
يشكك بعض الخبراء في صحة
قال ديفيد غالبريث، الخبير التقني في مجال الذكاء الاصطناعي: "يُمثل إينياس بداية الذكاء الاصطناعي في مجال التاريخ". ولا يُعدّ إنجاز إينياس تقدمًا تقنيًا فحسب، بل يُشير أيضًا إلى التكامل العميق بين العلوم الإنسانية والذكاء الاصطناعي. بالنسبة للمؤرخين، فهو ليس بديلًا عن الباحثين، بل هو بمثابة "مساعد خارق" يُقلّل من الجهد الميكانيكي ويُوسّع آفاق البحث. وفي الوقت نفسه، يُثبت إينياس، في مجال الذكاء الاصطناعي، إمكانات النماذج متعددة الوسائط والسياقية في معالجة بيانات العلوم الإنسانية المعقدة، ويُقدّم نموذجًا للتطوير المُستقبلي للأبحاث المتعلقة باللغات القديمة الأخرى.
لا يزال لدى إينيس حدود. في مواجهة هذا الإنجاز، أعرب خبير آخر في مجال الذكاء الاصطناعي عن قلقه من أن "الاعتماد المفرط على الذكاء الاصطناعي لسد الثغرات سيثير تساؤلات حول مصداقيته".

من المُسلّم به أن الذكاء الاصطناعي أداة، وليس بديلاً حقيقياً. في بيانات التدريب، لا تحتوي سوى 5% من النقوش على صور، وعدد النقوش في بعض المناطق (مثل صقلية) والفترات الزمنية (مثل ما قبل 600 قبل الميلاد) غير كافٍ، مما يُؤدي إلى انخفاض دقة التنبؤ. هذه كلها تحذيرات بأن تقنية الذكاء الاصطناعي الحالية لا تزال غير ناضجة، وعلينا أن نختار بعقلانية دورها في البحث العلمي والحياة.








