Command Palette
Search for a command to run...
مجموعة بيانات بنية البلورات LLM4Mat-Bench
التاريخ
عنوان URL للنشر
رابط الورقة البحثية
LLM4Mat-Bench عبارة عن مجموعة بيانات لتقييم نموذج اللغة متعدد الوسائط للتنبؤ بخصائص المواد تم إنشاؤها بشكل مشترك من قبل جامعة برينستون وجامعة تورنتو ومؤسسات أخرى. "نتائج الورقة ذات الصلة هي"LLM4Mat-Bench: معايرة نماذج اللغات الكبيرة للتنبؤ بخصائص المواديهدف هذا البحث إلى تقييم أداء نماذج اللغات الكبيرة (LLMs) في التنبؤ بخصائص المواد واكتشافها. تحتوي مجموعة البيانات على ما يقارب 1.97 مليون عينة من بنية البلورات من 10 قواعد بيانات عامة للمواد، تغطي 45 خاصية فيزيائية وكيميائية مختلفة للمواد. ويُعد هذا أكبر معيار حتى الآن لتقييم أداء نماذج اللغات الكبيرة (LLMs) في التنبؤ بخصائص المواد.
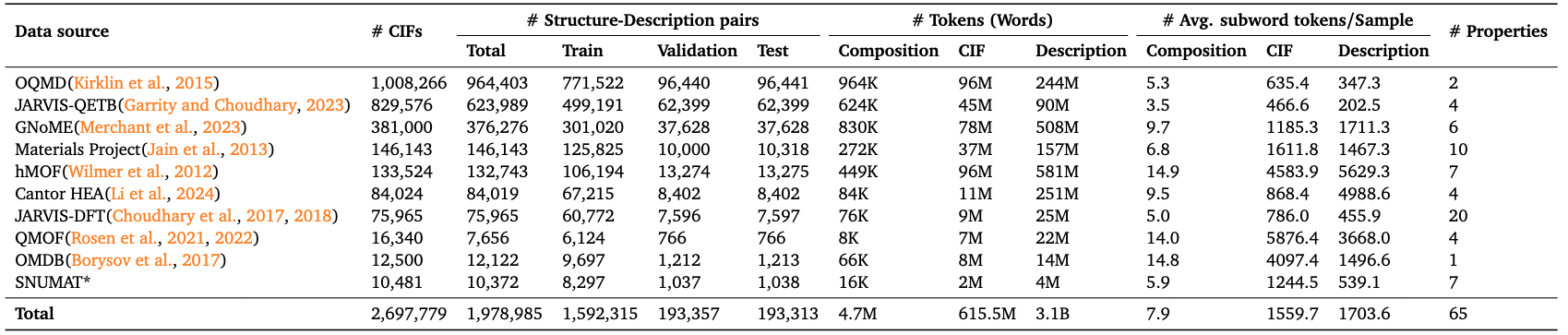
إجمالي كمية البيانات:
- وضع تكوين البلورة (التكوين): حوالي 4.7 مليون رمز
- وضع البنية البلورية (CIF): حوالي 615.5 مليون رمز
- وصف النص: حوالي 3.1 مليار رمز تتضمن عملية بناء مجموعة البيانات هذه جمع ملفات CIF الأصلية وخصائص المواد من قواعد بيانات المواد الرئيسية المتعددة، وإنشاء أوصاف لغة هيكلية تلقائيًا استنادًا إلى البنية البلورية، وبالتالي تشكيل عينة بيانات هيكلية موحدة ومتعددة الوسائط. يحتوي كل سجل عينة على معرف المادة المقابلة، والصيغة الكيميائية، وقيم الخصائص (مثل فجوة النطاق، وطاقة التكوين، والكثافة، ومعامل المرونة، وما إلى ذلك) وغيرها من المعلومات. الهدف الأساسي لبرنامج LLM4Mat-Bench هو تعزيز التكامل المتبادل بين علم المواد ومعالجة اللغة الطبيعية، وتعزيز البحث وتطوير التطبيقات في مجالات تقييم النموذج المحدد للمهمة، والتنبؤ بالخصائص، وضبط التعليمات. إن خصائصها المتعددة المصادر والوسائط والنطاق الواسع تجعلها مرجعًا مهمًا في أبحاث نماذج اللغة المادية.
بناء الذكاء الاصطناعي بالذكاء الاصطناعي
من الفكرة إلى الإطلاق — سرّع تطوير الذكاء الاصطناعي الخاص بك مع المساعدة البرمجية المجانية بالذكاء الاصطناعي، وبيئة جاهزة للاستخدام، وأفضل أسعار لوحدات معالجة الرسومات.