Command Palette
Search for a command to run...
مجموعة بيانات معيار استرجاع النصوص BRIGHT
التاريخ
الحجم
عنوان URL للنشر
رابط الورقة البحثية
* هذه المجموعة من البيانات تدعم الاستخدام عبر الإنترنت.انقر هنا للقفز.
تُعد مجموعة البيانات هذه معيارًا جديدًا لاسترجاع النصوص تم إطلاقه في عام 2024 من قبل جامعة هونج كونج وجامعة برينستون وجامعة واشنطن وGoogle Cloud AI Research.برايت: معيار واقعي وتحدي للاسترجاع المكثف بالاستدلال".
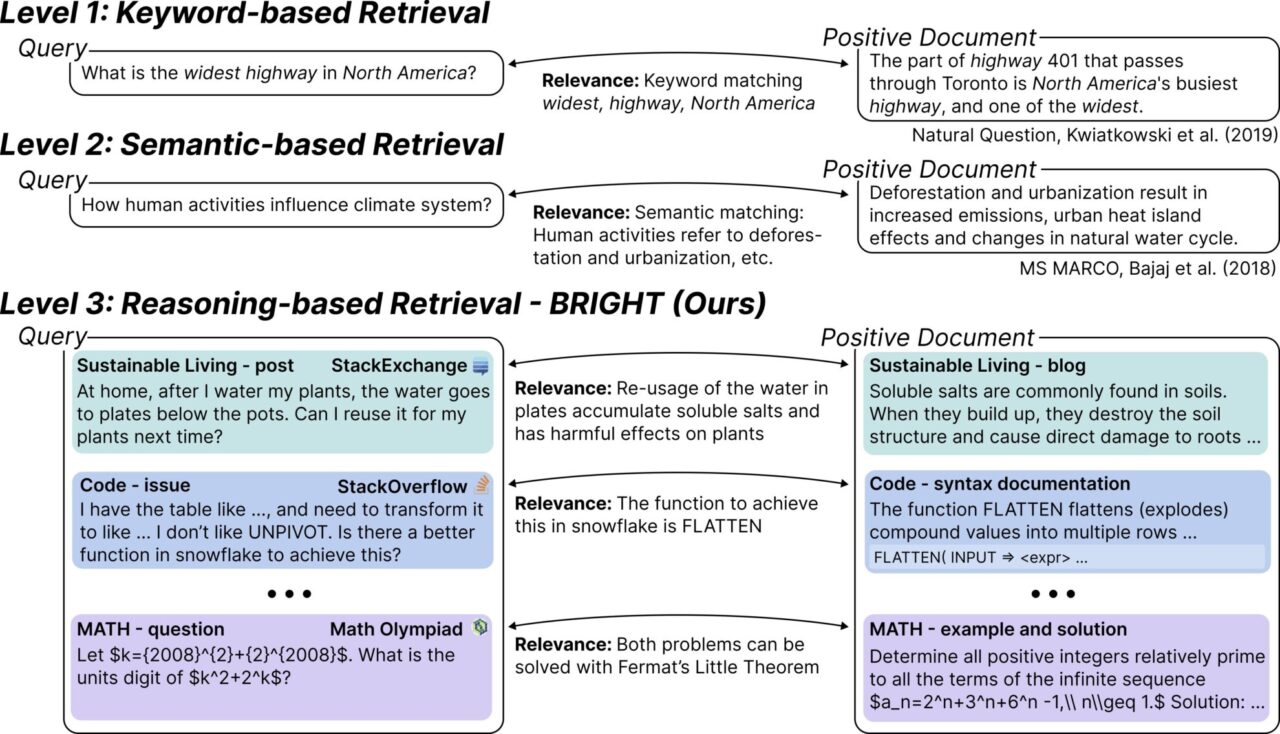
BRIGHT هو أول معيار لاسترجاع النصوص يتطلب التفكير العميق لاسترجاع المستندات ذات الصلة. قام فريق البحث بجمع 1385 استعلامًا حقيقيًا من مجالات مختلفة (StackExchange، وLeetCode، ومسابقات الرياضيات)، والتي جاءت جميعها من بيانات اصطناعية حقيقية. قام الفريق بربط هذه الاستعلامات بصفحات الويب المرتبطة بإجابات StackExchange والنظرية المحددة في مسائل أولمبياد الرياضيات.
تم تصميمه خصيصًا لتقييم واختبار أداء أنظمة الاسترجاع عند معالجة الاستعلامات المعقدة. لا تتطلب هذه الاستعلامات مطابقة الكلمات الرئيسية فحسب، بل تتطلب أيضًا قدرات التفكير العميق لتحديد المستندات ذات الصلة. ببساطة، يقوم BRIGHT باختبار ما إذا كان نظام الاسترجاع قادرًا على "فهم" المنطق والسياق وراء الاستعلام، وليس فقط النص السطحي. على سبيل المثال، يريد أحد علماء الاقتصاد العثور على وثائق توضح كيفية تأثير الأنشطة البشرية على نظام المناخ. لا تتعلق هذه المشكلة فقط بمطابقة الكلمات الرئيسية، بل تتطلب فهم العلاقة بين الأنشطة البشرية (مثل إزالة الغابات والتوسع الحضري) وتغير المناخ.
بناء الذكاء الاصطناعي بالذكاء الاصطناعي
من الفكرة إلى الإطلاق — سرّع تطوير الذكاء الاصطناعي الخاص بك مع المساعدة البرمجية المجانية بالذكاء الاصطناعي، وبيئة جاهزة للاستخدام، وأفضل أسعار لوحدات معالجة الرسومات.