HyperAI
Command Palette
Search for a command to run...
HiPO 하이브리드 전략 최적화 프레임워크
HiPO(하이브리드 정책 최적화)는 2025년 9월 콰이쇼우와 난징대학교 연구팀에 의해 제안되었습니다. 관련 연구 결과는 "HiPO: LLM의 동적 추론을 위한 하이브리드 정책 최적화".
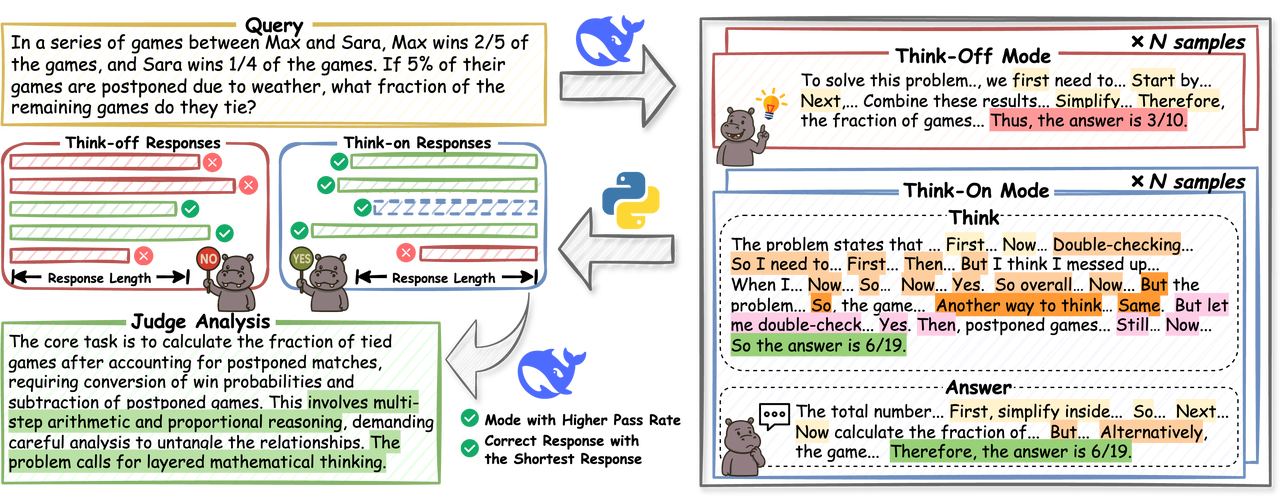
HiPO는 LLM이 상세 추론을 수행할 시점(Think-on)과 직접 응답을 제공할 시점(Think-off)을 선택적으로 결정할 수 있도록 하는 적응형 추론 제어 프레임워크입니다. 특히, HiPO는 Think-on 및 Think-off 응답을 쌍으로 제공하는 하이브리드 데이터 파이프라인과 상세 추론에 대한 과도한 의존을 피하면서 정확도와 효율성의 균형을 유지하는 하이브리드 강화 학습 보상 시스템을 결합합니다. 수학 및 프로그래밍 벤치마크 실험 결과, HiPO는 정확도를 유지하거나 향상시키면서 토큰 길이를 크게 줄일 수 있음을 보여줍니다.