Command Palette
Search for a command to run...
IQuest-Coder-V1 기술 보고서
IQuest-Coder-V1 기술 보고서
초록
본 보고서에서는 코드 대규모 언어 모델(LLM)의 새로운 세대인 IQuest-Coder-V1 시리즈(7B/14B/40B/40B-Loop)를 소개한다. 기존의 정적 코드 표현을 넘어서, 소프트웨어 논리의 동적 진화를 파이프라인의 다양한 단계에서 포착하는 ‘코드 흐름 다단계 학습 패러다임’을 제안한다. 본 모델들은 진화적 파이프라인을 통해 개발되었으며, 초기 사전 학습 단계에서는 코드 사실, 저장소 데이터, 코드 완성 데이터를 기반으로 한다. 이후, 32k 컨텍스트에서 추론 및 에이전트적 행동 경로를 통합하는 전용 중간 학습 단계를 수행하여 깊이 있는 논리적 기반을 구축한다. 이어, 128k 컨텍스트에서 저장소 규모의 데이터를 활용한 학습을 통해 모델의 성능을 강화한다. 이후, 최종적으로 전문화된 코딩 능력을 갖춘 후처리 학습을 수행하며, 이 과정은 두 가지 전문화된 경로로 분기된다: 추론 기반 강화 학습을 활용하는 ‘사고 경로’와 일반적인 도움 제공에 최적화된 ‘지시 경로’이다. IQuest-Coder-V1은 에이전트 기반 소프트웨어 공학, 경쟁 프로그래밍, 복잡한 도구 활용 등 코드 지능의 핵심 차원에서 경쟁 모델들 중 최고 수준의 성능을 달성한다. 배포 제약을 해결하기 위해, IQuest-Coder-V1-Loop 버전은 모델 용량과 배포 크기 사이의 균형을 최적화하기 위한 반복 메커니즘을 도입하여, 효율성과 효과성 간의 상호보완적 관계를 아키텍처적으로 개선한 새로운 접근을 제시한다. 우리는 IQuest-Coder-V1 시리즈의 공개, 특히 사전 학습 기반에서 최종 사고 모델과 지시 모델에 이르는 완전한 백박스 체크포인트 체인의 제공이 자율 코드 지능 및 실제 에이전트 시스템 연구의 발전에 기여할 것이라고 믿는다.그림 1. IQuest-Coder-V1의 다양한 벤치마크에서의 성능. LiveCodeBench v6의 점수는 IQuest-Coder-V1-40B-Loop-Thinking 모델에서 도출되었으며, 나머지 점수는 IQuest-Coder-V1-40B-Loop-Instruct 모델에서 산출되었다. 주황색 점선은 선택된 모델들의 평균 점수를 나타낸다.
One-sentence Summary
The IQuest-Coder-V1 team introduces the 7B/14B/40B/40B-Loop code LLM family, trained via a code-flow multi-stage paradigm that evolves software logic through pre-training on code facts and repositories, mid-training with reasoning and agentic trajectories in 32k and 128k contexts, and dual-path post-training via reasoning-driven RL and instruction optimization, achieving state-of-the-art performance in agentic software engineering, competitive programming, and complex tool use.
Key Contributions
- We introduce the code-flow multi-stage training paradigm, which evolves software logic through pre-training on code facts and repositories, mid-training with reasoning and agentic trajectories in 32k–128k-context, and bifurcated post-training via reasoning-driven RL and instruction-tuning for thinking and instruct paths.
- IQuest-Coder-V1 achieves state-of-the-art performance on agentic software engineering, competitive programming, and complex tool use benchmarks, including LiveCodeBench v6 (via the 40B-Loop-Thinking model) and other tasks evaluated on the 40B-Loop-Instruct variant.
- The IQuest-Coder-V1-Loop variant incorporates a recurrent mechanism to optimize the capacity-efficiency trade-off for deployment, and the full open-sourced training pipeline—from pre-training bases to final models—enables reproducibility and advances autonomous code intelligence research.
Introduction
The authors leverage a novel code-flow multi-stage training paradigm to build IQuest-Coder-V1, a family of code LLMs designed to model the dynamic evolution of software logic across development phases. Prior models often treat code as static, limiting their ability to handle complex, real-world engineering tasks that require reasoning over repository-scale context and evolving logic. To overcome this, the authors introduce an evolutionary pipeline with specialized mid-training using 32k and 128k context windows, followed by bifurcated post-training paths—reasoning-driven RL for deep analysis and instruction-tuning for general assistance. Their main contribution includes state-of-the-art performance across agentic software engineering, competitive programming, and tool use, plus the IQuest-Coder-V1-Loop variant, which uses recurrent mechanisms to optimize deployment efficiency without sacrificing capability. They also open-source the full training chain to accelerate research in autonomous code systems.
Dataset

The authors use a multi-stage, highly curated dataset to train IQuest-Coder, combining web-scale corpora with domain-specific code and reasoning data. Here’s how the dataset is structured and used:
-
General Corpus (Stage 1):
- Sourced primarily from Common Crawl, cleaned via regex filters and hierarchical deduplication (exact + fuzzy matching using embedding models).
- Decontaminated to exclude overlaps with standard benchmarks.
- Code snippets undergo AST analysis to verify syntactic validity, supporting code-flow training.
- Domain-specific proxy classifiers (small models trained to emulate larger ones) filter data by information density, educational value, and toxicity — outperforming FastText baselines.
- CodeSimpleQA-Instruct (66M samples) is integrated to inject factual, objective Q&A pairs generated via LLMs under constraints for time-invariance and single correct answers.
-
Repository Evolution Data:
- Built as triplets: (R_old, P, R_new), where R_old and R_new are code states from the 40%-80% lifecycle percentile (mature phase), and P is the patch between them.
- Ensures temporal continuity and meaningful code changes, avoiding early instability or late fragmentation.
-
Code Completion Data (FIM Format):
- Constructed at file and repo levels using Fill-In-the-Middle (FIM) format: ||.
- File-level: single document split via random character or line boundaries.
- Repo-level: adds semantically similar snippets from the same repo as context.
- Syntax-based construction uses ASTs to extract expression-, statement-, and function-level segments, preserving structural integrity.
- Task formats include: <fim_prefix>{pre}|{suf}|{mid}|{im_end}|> (file) and <repo_name>{repo} <|file_sep|>{path1} {content1} <|file_sep|>{path2} {content2} <|file_SEP|>{path3} ... {pre}|{suf} <fim_middle|>{mid}|{im_end}|> (repo).
-
Mid-Training (Stage 2):
- Uses same core data categories: Reasoning QA (math, coding, logic), Agent trajectories, code commits, and FIM data.
- Reasoning QA teaches structured decomposition and consistency; Agent trajectories simulate closed-loop intelligence via action-observation-revision cycles with feedback (logs, errors, tests).
- Stage 2.1 trains at 32K context; Stage 2.2 extends to 128K to enable repository-scale reasoning.
-
Evaluation Benchmarks:
- CrossCodeEval (Python, Java, TypeScript, C#) tests cross-file completion.
- Aider’s Polyglot benchmark (C++, Go, Java, JavaScript, Python, Rust) evaluates multilingual editing on 225 hardest Exercism problems.
All data undergoes strict quality filtering and structural validation to support scalable, high-fidelity code modeling.
Method
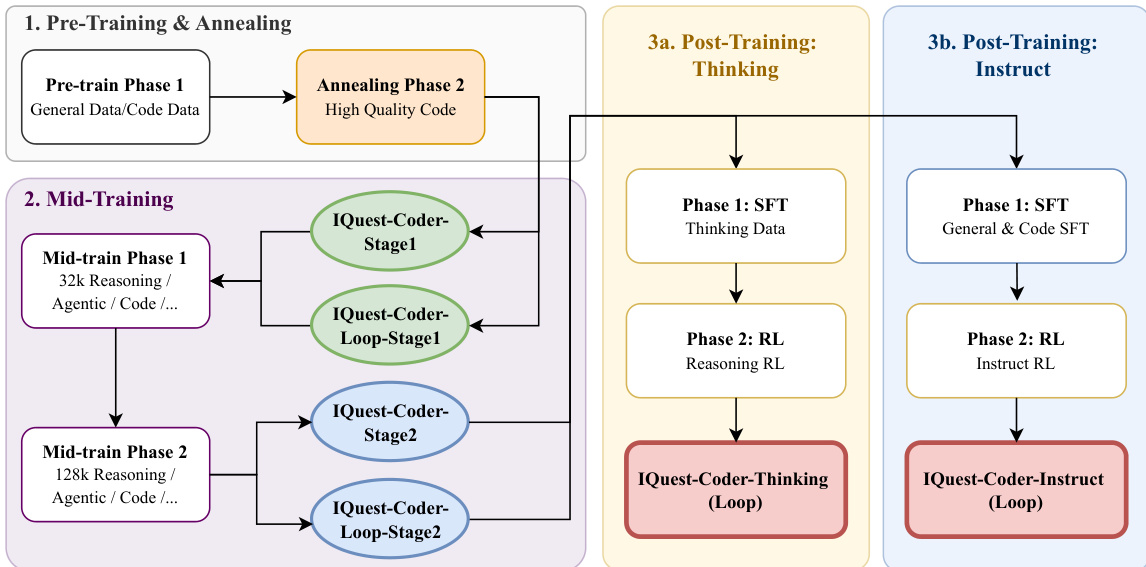
The authors leverage a structured, multi-phase training pipeline—termed the Code-Flow pipeline—to systematically evolve logical and agentic capabilities in the IQuest-Coder-V1 series. The framework is organized into three primary stages: pre-training and annealing, mid-training, and bifurcated post-training, each designed to progressively specialize the model while preserving general intelligence. The process begins with pre-training and annealing, where the model is first exposed to a mixture of general and code-specific data in Stage 1, followed by an annealing phase focused exclusively on high-quality, curated code corpora. This primes the model’s representations for complex reasoning tasks by reinforcing syntactic and semantic patterns inherent in real-world codebases. Refer to the framework diagram for the flow of this initial phase.
Experiment
Our model is evaluated across diverse code generation, reasoning, efficiency, and agentic tasks against a broad set of state-of-the-art baselines including Claude, GPT, Gemini, Qwen, and StarCoder2. It achieves strong results on EvalPlus, BigCodeBench, FullStackBench, and LiveCodeBench for code generation; excels in forward and inverse reasoning on CRUXEval; and scores competitively on Mercury for runtime efficiency and on Spider and BIRD for Text-to-SQL. In agentic settings, it attains a 76.2 score on SWE-bench Verified and performs robustly on Terminal-Bench and general tool-use benchmarks like Mind2Web and BFCL, while maintaining high safety compliance across Tulu 3 benchmarks with balanced refusal behavior on harmful prompts.
The authors evaluate code generation performance across six programming languages, reporting scores and relative changes compared to baseline models. Results show consistent gains in most language pairs, with notable improvements in Java and TypeScript, while some cases show slight declines in Python and C#. Java-to-JavaScript shows a 12.62% improvement over baseline Python-to-C# and Python-to-Rust show declines of 1.69% and 2.72% TypeScript-to-JavaScript and Go-to-Rust show gains of 4.69% and 2.86%

The authors evaluate multiple code generation models across Python, Java, TypeScript, and C#, reporting exact match and edit similarity scores. IQuest-Coder-V1-40B achieves the highest average edit similarity and strong exact match scores, outperforming other 20B+ models in most languages. Results indicate competitive performance in both functional correctness and structural similarity across programming languages. IQuest-Coder-V1-40B leads in average edit similarity (85.7) among 20B+ models It achieves top exact match in Java (57.9) and strong scores in Python (49.0) and C# (63.4) StarCoder2-7B underperforms with lowest average exact match (8.3) and edit similarity (70.8)

The authors evaluate their model across agentic coding and general tool-use tasks, comparing it with open-source and closed-API models. Results show the model achieves competitive scores on Terminal-Bench, SWE-Verified, Mind2Web, and BFCL V3, particularly excelling in SWE-Verified with a 76.2 score. Performance is strong relative to similarly sized open models and approaches some closed-source systems. IQuest-Coder-V1-40B-Loop-Instruct scores 76.2 on SWE-Verified, outperforming most open models. The model achieves 52.5 on Terminal-Bench and 64.3 on Mind2Web, showing broad agentic capability. Performance on BFCL V3 reaches 73.9, indicating strong multi-step tool-use reasoning.

The authors evaluate multiple code-focused language models on Text to SQL tasks using Bird and Spider benchmarks. Results show that IQuest-Coder-V1-40B-Instruct achieves 70.5 on Bird and 92.2 on Spider, outperforming most open-source models and matching or exceeding several closed-source systems. The the the table highlights performance differences across model sizes and architectures, with closed-API models generally showing strong execution accuracy. IQuest-Coder-V1-40B-Instruct leads open-source models with 92.2 Spider accuracy Closed-API models like Gemini-3-Flash-preview score 87.2 on Spider Qwen3-Coder-480B-A35B-Instruct achieves 81.2 on Spider despite lower Bird score

The authors evaluate multiple code-focused language models across CruxEval and LiveCodeBench benchmarks, grouping them by parameter scale and architecture. Results show that IQuest-Coder-V1 variants, particularly the 40B Loop-Thinking model, achieve top scores in Output-COT and LiveCodeBench V6, outperforming many larger or closed-source models. Closed-API models like Gemini-3 and Claude-Opus-4.5 remain competitive but do not consistently surpass the best open models in all metrics. IQuest-Coder-V1-40B-Loop-Thinking leads in Output-COT with 99.4 and LiveCodeBench V6 with 81.1 Closed-API models like Gemini-3-Flash-preview score high in CruxEval but trail in LiveCodeBench V6 Qwen3-235B-A22B-Thinking-2507 shows strong CruxEval Output-COT at 89.5 but lower LiveCodeBench scores

The authors evaluate IQuest-Coder-V1-40B across cross-language code generation, agentic coding, Text-to-SQL, and code reasoning benchmarks, showing consistent gains in Java and TypeScript translation while noting slight declines in Python and C#. The model achieves top edit similarity (85.7) and exact match scores in Java (57.9), C# (63.4), and Python (49.0), outperforming most 20B+ models, and excels in agentic tasks with a 76.2 on SWE-Verified, 52.5 on Terminal-Bench, and 73.9 on BFCL V3. In Text-to-SQL, it leads open-source models with 92.2 on Spider and 70.5 on Bird, while its Loop-Thinking variant tops Output-COT (99.4) and LiveCodeBench V6 (81.1), rivaling or surpassing several closed-source systems.