Command Palette
Search for a command to run...
딥시크-OCR 2: 시각적 인과 흐름
딥시크-OCR 2: 시각적 인과 흐름
Haoran Wei Yaofeng Sun Yukun Li
DeepSeek-OCR 2 시각적 인과 흐름
초록
우리는 새로운 인코더인 DeepEncoderV2가 이미지의 시각적 의미에 따라 시각 토큰을 동적으로 재정렬할 수 있는 가능성을 탐구하기 위해 DeepSeek-OCR 2를 제안한다. 기존의 시각-언어 모델(VLM)은 이미지를 LLM에 입력할 때 항상 고정된 래스터 스캔 순서(상단 왼쪽에서 하단 오른쪽으로)와 고정된 위치 인코딩을 사용하여 시각 토큰을 처리한다. 그러나 이는 인간의 시각 인지 방식과 모순된다. 인간의 시각은 본질적인 논리적 구조에 의해 유도되는 유연하면서도 의미적으로 일관된 스캔 패턴을 따르기 때문이다. 특히 복잡한 레이아웃을 가진 이미지의 경우, 인간의 시각은 인과적 정보를 기반으로 한 순차적 처리를 보인다. 이러한 인지 메커니즘을 영감으로 삼아, DeepEncoder V2는 인과적 추론 능력을 갖춘 인코더를 설계하여, LLM 기반의 콘텐츠 해석 전에 시각 토큰을 지능적으로 재정렬할 수 있도록 한다. 본 연구는 새로운 패러다임을 탐구한다: 2차원 이미지 이해는 두 개의 연속된 1차원 인과적 추론 구조를 통해 효과적으로 달성될 수 있는가? 이를 통해 진정한 2차원 추론을 가능하게 하는 새로운 아키텍처 접근법을 제시한다. 코드 및 모델 가중치는 http://github.com/deepseek-ai/DeepSeek-OCR-2 에 공개되어 있다.
One-sentence Summary
DeepSeek-AI researchers introduce DeepSeek-OCR 2, featuring DeepEncoder V2, which dynamically reorders visual tokens using causal reasoning to replace rigid raster-scan processing, thereby enabling more human-like, semantically coherent image understanding for enhanced OCR and document analysis.
Key Contributions
- We introduce DeepEncoder V2, a vision encoder that dynamically reorders visual tokens using causal reasoning derived from image semantics, replacing rigid raster-scan order to better align with human visual perception.
- The encoder employs bidirectional and causal attention mechanisms to enable 1D sequential reasoning over 2D images, forming a two-cascaded 1D paradigm that advances toward genuine 2D understanding without flattening spatial structure.
- Evaluated on document OCR tasks involving complex layouts, formulas, and tables, DeepSeek-OCR 2 achieves meaningful performance gains over DeepSeek-OCR while preserving high token compression, validating the architectural shift toward semantically guided visual processing.
Introduction
The authors leverage a novel vision encoder, DeepEncoder V2, to challenge the rigid raster-scan token ordering used in most vision-language models, which ignores semantic structure and mimics human visual perception more closely. Prior models treat image patches as fixed sequences, introducing an inductive bias that hinders reasoning over complex layouts like documents or formulas. DeepEncoder V2 introduces causal flow queries and hybrid attention masks to dynamically reorder visual tokens based on semantic context, enabling the model to process images through cascaded 1D causal reasoning—a step toward genuine 2D understanding. Their architecture also lays groundwork for unified multimodal encoding, where shared parameters can process text, vision, and potentially other modalities via modality-specific queries.
Dataset
- The authors use a training dataset composed of OCR 1.0, OCR 2.0, and general vision data, with OCR data making up 80% of the training mixture.
- OCR 1.0 is sampled more evenly by partitioning pages into text, formulas, and tables at a 3:1:1 ratio to improve balance.
- Layout detection labels are refined by merging semantically similar categories—for example, “figure caption” and “figure title” are unified.
- For evaluation, they use OmniDocBench v1.5, which includes 1,355 document pages across 9 categories in both Chinese and English, covering magazines, academic papers, and research reports.
- The benchmark’s diversity and evaluation criteria help validate DeepSeek-OCR 2’s performance, especially the impact of DeepEncoder V2.
Method
The authors leverage a novel encoder architecture, DeepEncoder V2, to enable causal visual reasoning within a vision-language modeling pipeline. This design replaces the CLIP-based vision encoder of DeepEncoder with a compact language model (Qwen2-0.5B), repurposing its decoder-only structure to model visual token reordering through learnable causal flow queries. The overall framework, as shown in the figure below, retains the tokenization and decoding stages of DeepSeek-OCR but introduces a dual-stream attention mechanism within the encoder to decouple global visual representation from sequential causal modeling.
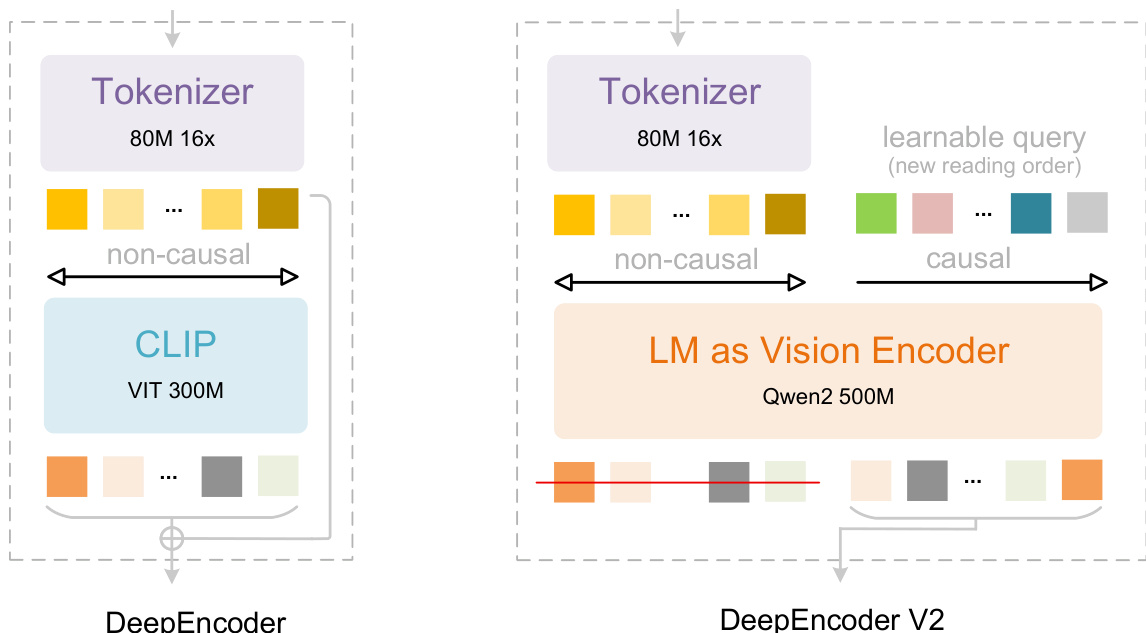
The vision tokenizer, inherited from DeepEncoder, employs an 80M-parameter SAM-base architecture followed by two convolutional layers to compress image patches into visual tokens at a 16x reduction ratio. This component outputs tokens with a hidden dimension of 896, optimized for compatibility with the downstream LLM encoder. The tokenizer’s efficiency enables substantial memory and compute savings, particularly when processing high-resolution inputs.
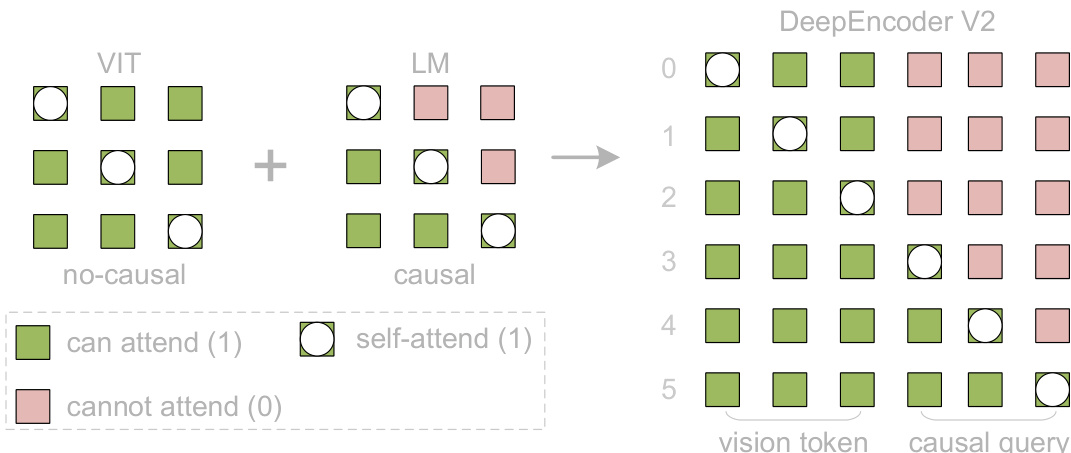
The core innovation lies in the LLM-style vision encoder, which processes a concatenated sequence of visual tokens followed by an equal number of learnable causal flow tokens. The attention mechanism is customized via a block mask: visual tokens engage in bidirectional self-attention (analogous to ViT), preserving global receptive fields, while causal flow tokens employ unidirectional, lower-triangular attention (identical to LLM decoders). This mask, visualized in the figure below, ensures that each causal query attends only to preceding visual tokens and prior queries, enabling the encoder to learn a semantically meaningful reordering of visual content.
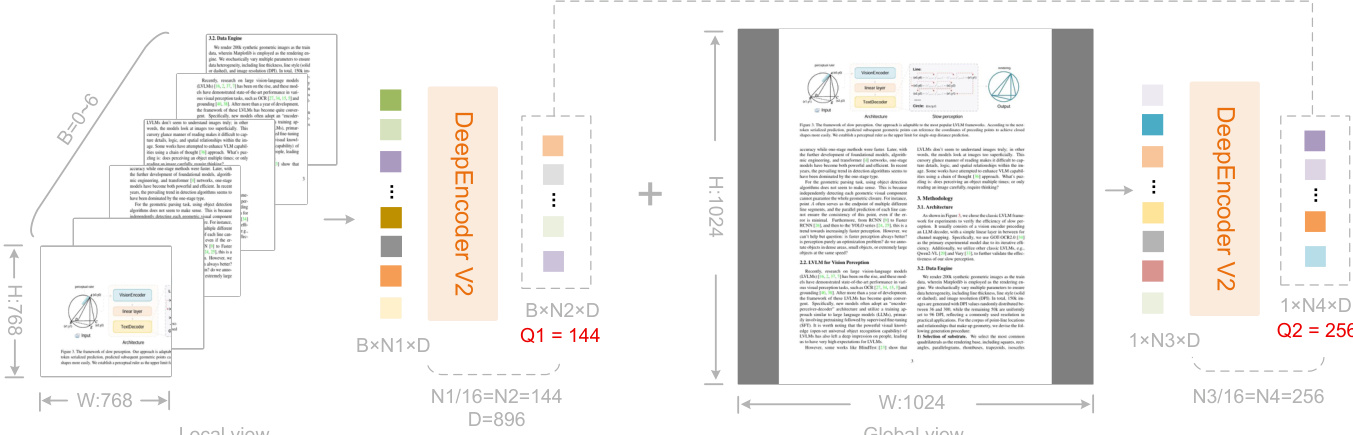
The number of causal flow tokens is dynamically determined by a multi-crop strategy: a global view at 1024×1024 yields 256 tokens, while up to six local crops at 768×768 contribute 144 tokens each, resulting in a total token count ranging from 256 to 1120. This design ensures consistent query cardinality across resolutions and aligns with the maximum visual token budget of Gemini-3 Pro. The figure below illustrates how local and global views are processed independently and concatenated to form the final token sequence.
Only the causal flow tokens — the latter half of the encoder’s output — are projected and fed into the DeepSeek-3B MoE decoder. This cascade design enables two-stage causal reasoning: the encoder performs semantic reordering of visual information, while the decoder executes autoregressive generation conditioned on this reordered sequence. The entire forward pass is formalized as:
O=D(πO(TL(E(I)⊕Q0;M)))where E maps the input image I to visual tokens V, Q0 denotes the learnable causal queries, ⊕ is sequence concatenation, TL is the L-layer Transformer with masked attention M, πO extracts the causal query outputs, and D is the MoE decoder producing output logits O.
Training proceeds in three stages: encoder pretraining with a lightweight decoder via next-token prediction, query enhancement with frozen tokenizer and joint optimization of encoder and decoder, and final decoder specialization with frozen encoder. The authors employ multi-resolution dataloaders, pipeline parallelism, and AdamW with cosine decay to scale training across 160 A100 GPUs.
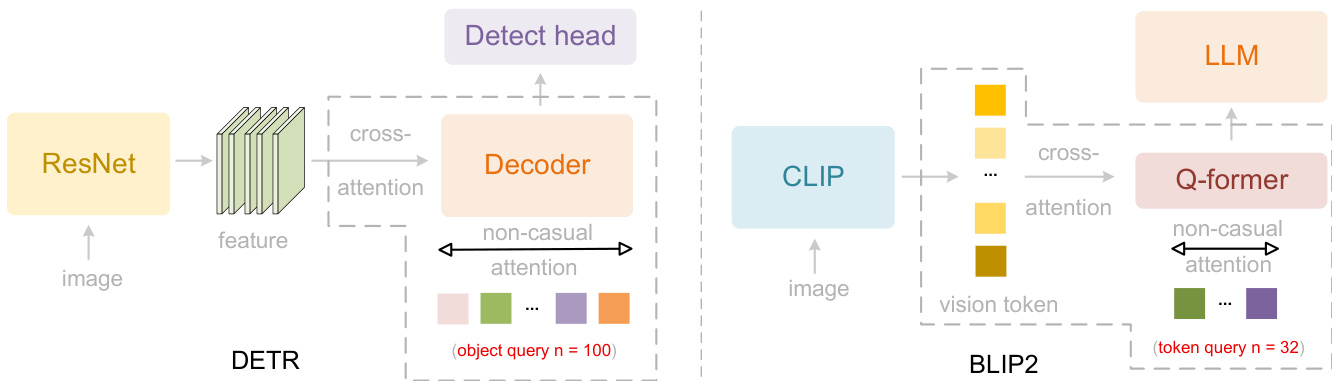
This architecture draws conceptual inspiration from parallelized query mechanisms in DETR and BLIP-2, as shown in the figure below, but adapts them to a causal, decoder-style encoder to bridge 2D spatial structure with 1D language modeling.
The resulting system, DeepSeek-OCR 2, maintains the image compression ratio and decoding efficiency of its predecessor while enabling substantial gains in visual reading logic through its causal encoder design.
Experiment
DeepSeek-OCR 2, trained by freezing DeepEncoder V2 and fine-tuning only the LLM, achieves 91.09% accuracy on OmniDocBench v1.5 with the smallest visual token budget, outperforming its predecessor by 3.73% and reducing reading order Edit Distance from 0.085 to 0.057. It also surpasses Gemini-3 Pro in document parsing ED (0.100 vs 0.115) under similar token constraints, confirming its efficient token compression and strong structural understanding. While it shows room for improvement on text-rich documents like newspapers due to token limits and data scarcity, it consistently excels in reading order across all document types. In production, it reduces repetition rates from 6.25% to 4.17% for user images and from 3.69% to 2.88% for PDFs, validating its practical robustness for LLM integration.
The authors compare DeepSeek-OCR 2 against DeepSeek-OCR in production settings using repetition rate as the primary metric. Results show DeepSeek-OCR 2 reduces repetition by 2.08% on online user log images and by 0.81% on PDF pretraining data, indicating improved practical reliability. DeepSeek-OCR 2 cuts repetition rate by 2.08% on user log images PDF data repetition drops 0.81% with DeepSeek-OCR 2 Lower repetition signals better logical visual comprehension in production

The authors evaluate DeepSeek OCR 2 against prior models on OmniDocBench v1.5, showing it achieves 91.09% overall accuracy with the smallest visual token budget. Results indicate significant improvements in text recognition and reading order accuracy compared to DeepSeek OCR, validating architectural enhancements. The model also shows strong performance across formula, the the table, and reading order tasks. DeepSeek OCR 2 achieves 91.09% overall accuracy with only 1120 visual tokens, outperforming models using 6000+ tokens. Reading order Edit Distance drops from 0.085 to 0.057, indicating better visual token arrangement by DeepEncoder V2. Text recognition Edit Distance improves by 0.025, and formula and the the table metrics rise by 6.17 and 3.05 points respectively.

The authors compare DeepSeek-OCR 2 with Gemini-3 Pro and Seed-1.8 using Edit Distance metrics across document elements. DeepSeek-OCR 2 achieves the lowest overall Edit Distance of 0.100 while using only 1120 visual tokens, outperforming Gemini-3 Pro (0.115) under a similar token budget. This indicates superior token efficiency and document parsing accuracy. DeepSeek-OCR 2 achieves 0.100 overall Edit Distance, lower than Gemini-3 Pro's 0.115 Uses only 1120 visual tokens, matching Gemini-3 Pro's token budget Shows improved performance in R-order (0.057) and the the table (0.096) metrics

The authors compare DeepSeek-OCR and DeepSeek-OCR 2 across nine document categories using Edit Distance metrics for text recognition and reading order. Results show DeepSeek-OCR 2 generally outperforms the baseline, especially in reading order accuracy, though it shows higher error on newspaper text. The comparison highlights both strengths and areas for improvement in the updated model. DeepSeek-OCR 2 improves reading order accuracy across all document types Newspaper text recognition remains a weakness with Edit Distance > 0.13 Text recognition improves in most categories except newspapers and notes

DeepSeek-OCR 2 is evaluated against its predecessor and competing models using repetition rate and Edit Distance metrics across production logs, PDFs, and the OmniDocBench v1.5 benchmark, demonstrating improved visual comprehension and token efficiency. It reduces repetition by 2.08% on user logs and 0.81% on PDF data, and achieves 91.09% overall accuracy with just 1120 visual tokens—surpassing models using 6000+ tokens—while improving reading order and text recognition accuracy. Compared to Gemini-3 Pro, it attains a lower overall Edit Distance of 0.100 under the same token budget, excelling particularly in reading order and the table parsing, though it still lags on newspaper text recognition.