Command Palette
Search for a command to run...
시각이 소리를 대신할 때
시각이 소리를 대신할 때
Xiaofei Wen Wenjie Jacky Mo Xingyu Fu Rui Cai Tinghui Zhu Wendi Li Yanan Xie Muhao Chen Peng Qi
초록
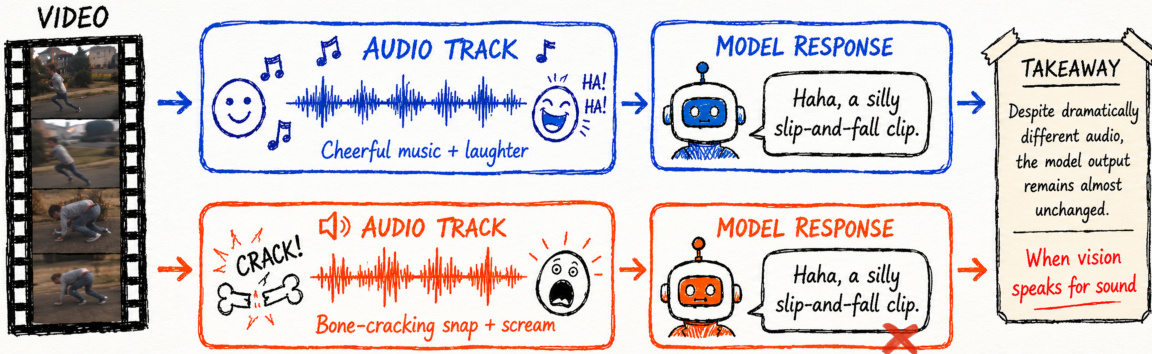
비디오 처리 능력을 갖춘 다모달 대형 언어 모델(MLLMs)의 급속한 발전에도 불구하고, 우리는 이러한 모델들의 비디오 내 음성 이해가 종종 시각에 기반하고 있음을 발견했습니다. 즉, 모델들은 오디오 스트림을 검증하기보다는 시각적 단서에 의존하여 음향 정보를 추론하거나 환각(hallucinate)합니다. 이러한 문제는 Google과 OpenAI와 같은 제공업체들이 개발한 최첨단의 오픈소스 오미 모델과 주요 폐쇄형 모델 모두에서 나타납니다. 우리는 이러한 실패 모드를 오디오-비주얼 클레버 한스(Clever Hans) 효과로 특징짓습니다. 이는 모델들이 거짓으로 오디오에 기반한 것처럼 보이지만, 실제로는 오디오와 시각 스트림이 진정으로 정렬되어 있는지 검증하지 않고 시각-음향 상관관계를 활용한다는 것을 의미합니다. 이러한 행동을 체계적으로 연구하기 위해, 우리는 세 가지 반사실적 오디오 수정을 기반으로 하는 개입 기반 탐색 프레임워크인 Thud를 소개합니다. 여기에는 시간적 동기화를 테스트하는 Shift, 소리 존재 여부를 테스트하는 Mute, 그리고 오디오-비주얼 일관성을 테스트하는 Swap이 포함됩니다. 진단을 넘어, 우리는 두 단계 정렬 레시피를 추가로 연구합니다. 개입에서 도출된 선호도 쌍은 오디오 검증을 가르치는 반면, 이벤트 수준의 일반 비디오 선호도는 모델이 과도하게 특화되는 것을 규제합니다. 우리가 개발한 10K 샘플 레시피는 세 가지 개입 차원 전반에서 평균 성능을 28%p 향상시켰으며, 일반 비디오 및 오디오-비주얼 QA 벤치마크에서도 성능을 약간 향상시켰습니다.
One-sentence Summary
The authors propose THUD, an intervention-driven probing framework that diagnoses and mitigates the audio-visual Clever Hans effect in video MLLMs by employing Shift, Mute, and Swap counterfactual audio edits alongside a two-stage alignment recipe to enforce genuine acoustic verification, improving average performance across intervention dimensions by 28 percentage points while slightly enhancing general video and audio-visual QA benchmarks.
Key Contributions
- Introduce THUD, an intervention-driven probing framework that evaluates audio-visual grounding through three counterfactual audio edits: Shift for temporal synchronization, Mute for sound existence, and Swap for audio-visual consistency. This framework systematically diagnoses how video-capable multimodal models rely on visual-semantic shortcuts rather than verifying actual acoustic streams.
- Develop a two-stage preference alignment recipe that combines intervention-derived audio verification signals with event-level general video preferences to prevent over-specialization. This approach explicitly trains models to cross-check audio presence and alignment under broken visual-acoustic correlations.
- Demonstrate that applying this 10K-sample alignment recipe increases average performance across the three intervention dimensions by 28 percentage points while delivering modest gains on standard video and audio-visual question answering benchmarks.
Introduction
Video-capable multimodal large language models are rapidly advancing, making audio-visual understanding a critical capability for applications ranging from assistive technologies to safety-critical monitoring. Despite strong benchmark scores, the authors find that these models frequently exhibit a Clever Hans effect, relying on visual-semantic shortcuts to hallucinate acoustic information instead of genuinely verifying the audio stream. Standard evaluation protocols mask this limitation by preserving natural cross-modal correlations, leaving a significant gap in reliable audio-visual grounding. To address this challenge, the authors introduce THUD, an intervention-driven diagnostic framework that uses counterfactual audio edits to systematically audit temporal synchronization, audio existence, and cross-modal consistency. They further demonstrate that targeted preference alignment combining these counterfactual interventions with general video data substantially improves genuine audio verification while maintaining robust general video understanding.
Dataset
-
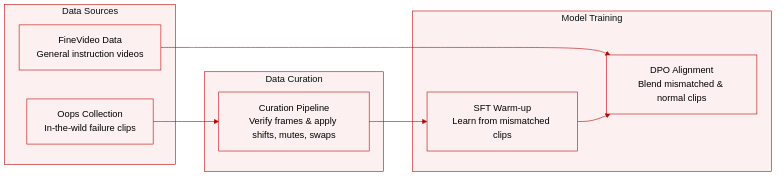
Dataset Composition and Sources: The authors construct a two-part dataset designed for audio-visual grounding evaluation and model alignment. The core intervention dataset is sourced from the Oops collection, which features in-the-wild videos of unintentional human actions and failures. For broader contextual training, the authors supplement this with general video instruction data drawn from FineVideo.
-
Subset Details and Filtering Rules: The intervention subset applies three controlled modifications to original clips: Shift (displacing audio by a temporal offset), Mute (replacing audio with silence), and Swap (replacing audio with a track from a different video). Exact sample counts are not specified, but the authors enforce strict quality filters. Visual timestamps must align within 0.8 seconds across Gemini, GPT, and Claude, while acoustic timestamps require human verification within 0.5 seconds. Clips with unclear event onsets, weak or masked audio, or swapped tracks that are trivially identical or completely unrelated are discarded. The general video subset is enriched through Gemini re-annotation and human verification, yielding four instruction types: description, localization, attribution, and audio-dependent QA.
-
Training Usage and Mixture Strategy: The paper employs a two-stage alignment pipeline. During the supervised fine-tuning warm-up phase, the model trains exclusively on the intervention-derived preference pairs to establish audio-aware response patterns. In the subsequent direct preference optimization stage, the authors mix intervention preference pairs with the general video instruction data. This mixture prevents over-specialization to counterfactual cases while encouraging the model to verify audio evidence rather than relying on visual shortcuts.
-
Processing, Cropping, and Metadata Construction: To enable precise temporal verification, the authors convert videos into temporally ordered frame units by dividing each clip into non-overlapping windows and sampling representative frames per unit. Initial annotations are generated via Gemini using a structured JSON prompt that captures event descriptions, precise timestamps, and confidence levels. These annotations are cross-verified using the frame-unit format. After validation, the three intervention operators are applied to generate final preference pairs, where the chosen response reflects accurate audio-visual grounding and the rejected response highlights visually plausible but incorrect assumptions. The resulting assets are paired with intervention metadata and reserved for diagnostic evaluation and alignment research.
Method
The authors leverage a two-stage post-training pipeline to align multimodal models beyond visual shortcuts by integrating intervention-based data with general video instruction data. The overall framework is designed to detect and correct reliance on visual-semantic correlations while preserving broad video understanding capabilities.
The pipeline begins with the construction of intervention data, which deliberately breaks natural audio-visual correlations through three types of physical interventions: Shift, Mute, and Swap. As shown in the figure below, these interventions manipulate the temporal alignment, presence, or consistency of audio and visual signals. Specifically, Shift introduces temporal displacement by shifting the audio track relative to the video, Mute removes the audio stream entirely, and Swap substitutes the original audio with a mismatched one. These interventions are applied to source videos that exhibit salient acoustic consequences, ensuring that the resulting data exposes model behavior under counterfactual conditions.
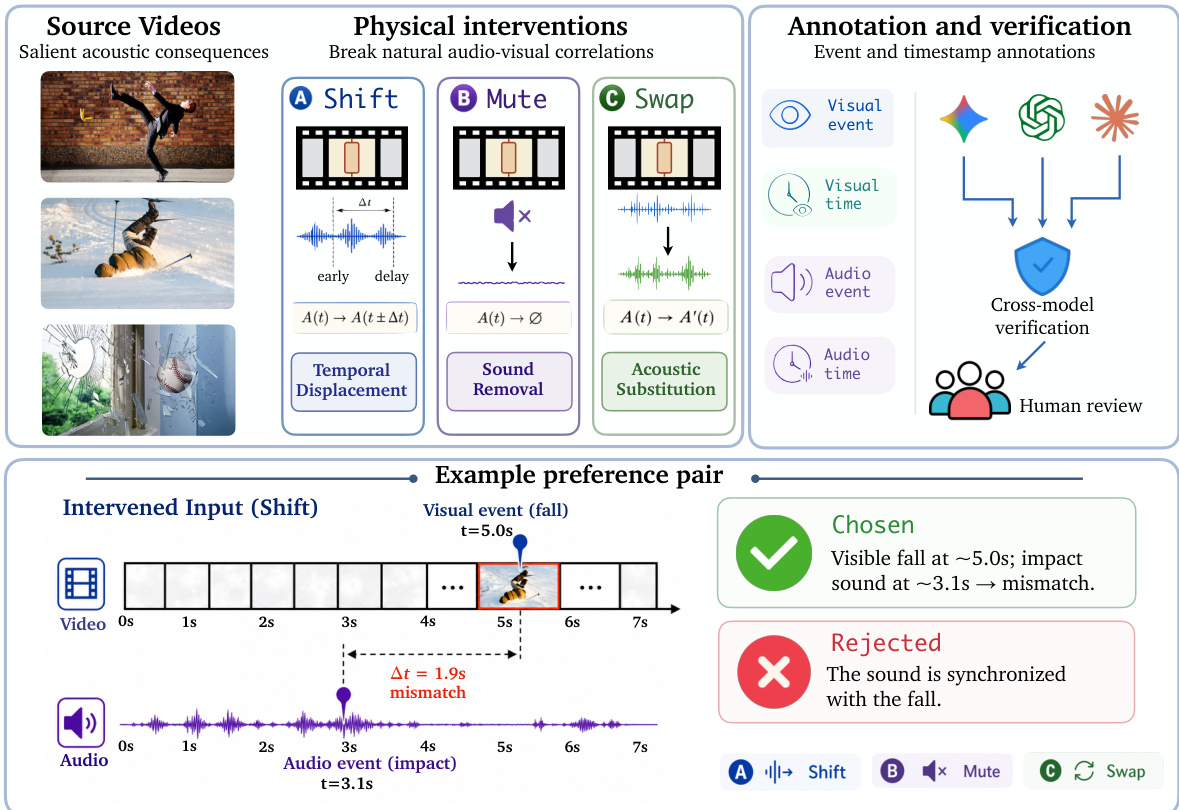
Following intervention, the data undergoes annotation and verification. Event-time labels are assigned to both visual and audio events, and preference pairs are constructed by comparing chosen and rejected responses based on cross-model verification and human review. This process generates labeled examples where the model is expected to reject visually plausible but audio-incorrect interpretations, thereby reinforcing correct audio-visual grounding.
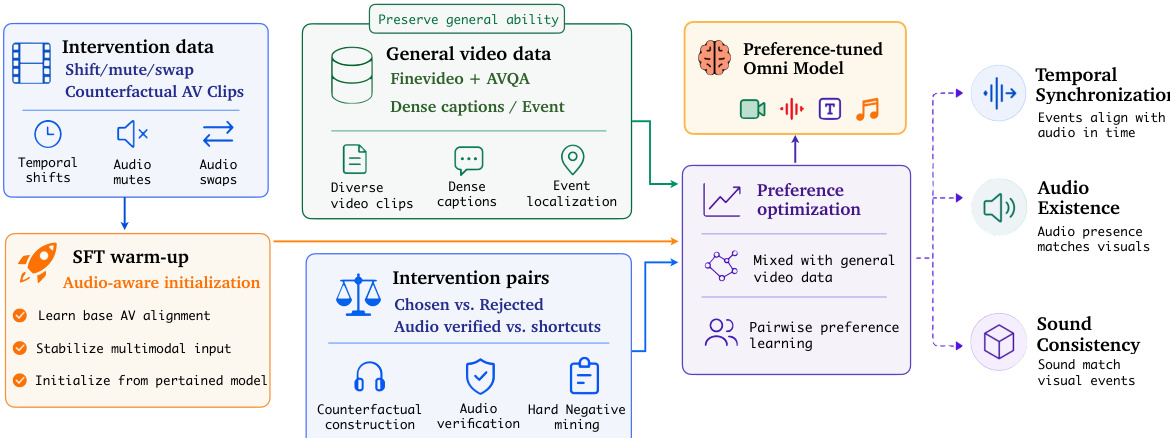
The training process consists of two distinct stages. In Stage 1, a supervised fine-tuning (SFT) warm-up is performed on the intervention data to establish basic audio-aware patterns. This stage initializes the model to recognize and respond appropriately to audio-visual mismatches. In Stage 2, the model undergoes preference optimization using a mixture of intervention preference pairs and general video data. The intervention pairs guide the model to reject visually plausible but audio-inconsistent outputs, while the general video data acts as a regularizer to preserve broad multimodal comprehension. This dual objective ensures that the model learns to verify audio signals rather than relying on visual priors.
Experiment
The evaluation assesses audio-visual grounding under natural and counterfactual conditions targeting temporal synchronization, sound existence, and cross-modal consistency, validating that current models heavily rely on visual priors and default synchronization assumptions rather than genuine audio verification. A subsequent experiment validates whether targeted preference alignment can correct these flaws without an alignment tax, demonstrating that counterfactual temporal and general video data substantially enhance robust temporal grounding and offset localization while preserving general multimodal capabilities. Finally, extending the training to audio existence and source consistency further reduces performance collapses across all interventions, confirming that deliberate cross-modal supervision effectively mitigates shortcut reliance and fosters reliable audio-visual understanding.
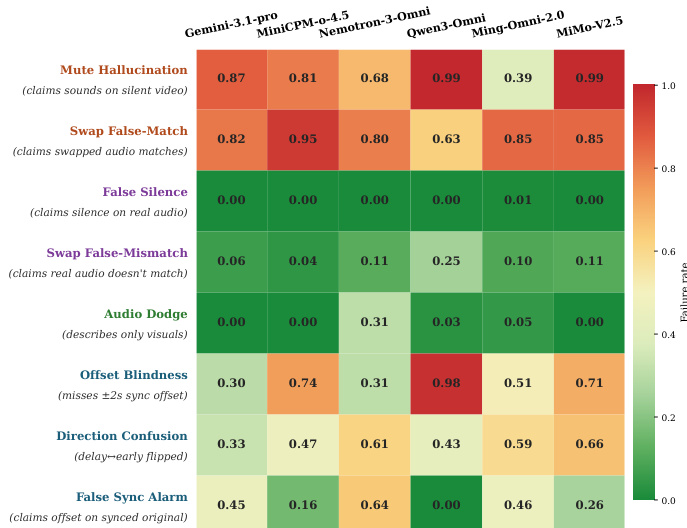
The authors analyze the reliance of multimodal models on visual shortcuts in audio-visual grounding tasks, using a heatmap to show failure rates across different models and intervention conditions. Results indicate that most models exhibit strong audio hallucination and temporal misalignment, with significant performance drops under counterfactual interventions, suggesting a dependence on visual priors rather than genuine audio-visual alignment. The analysis highlights systematic biases toward synced predictions and poor temporal offset detection, especially in models that fail to verify audio presence and timing. Most models show high failure rates in audio hallucination and temporal misalignment, indicating reliance on visual shortcuts rather than true audio-visual grounding. Models consistently prefer synced predictions, leading to high false sync alarms and poor detection of audio offsets, especially under small temporal shifts. The heatmap reveals systematic biases in error patterns, with models rarely denying real audio or correctly identifying the direction of temporal mismatches.
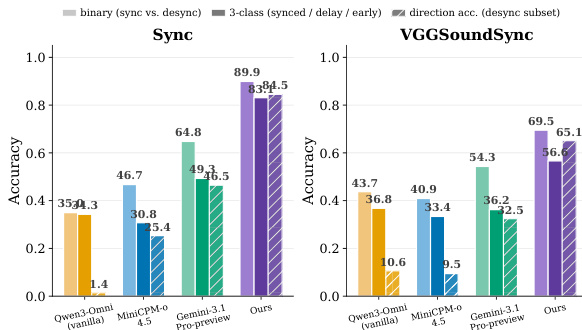
The authors examine audio-visual grounding in multimodal models, focusing on their reliance on visual shortcuts and the effectiveness of targeted alignment training. Results show that most models exhibit strong performance collapses under counterfactual interventions, indicating a dependence on visual-semantic priors rather than genuine audio-visual alignment. A targeted alignment approach improves temporal synchronization while preserving general capabilities, with the best model achieving significantly higher accuracy across both binary and fine-grained temporal tasks. Most models show large performance drops under counterfactual interventions, suggesting reliance on visual shortcuts rather than true audio-visual grounding. Targeted alignment training improves temporal synchronization without harming general video understanding, achieving better accuracy on both binary and fine-grained temporal tasks. The best model maintains robust performance across different temporal offset magnitudes and outperforms baselines in detecting and localizing desynchronization.
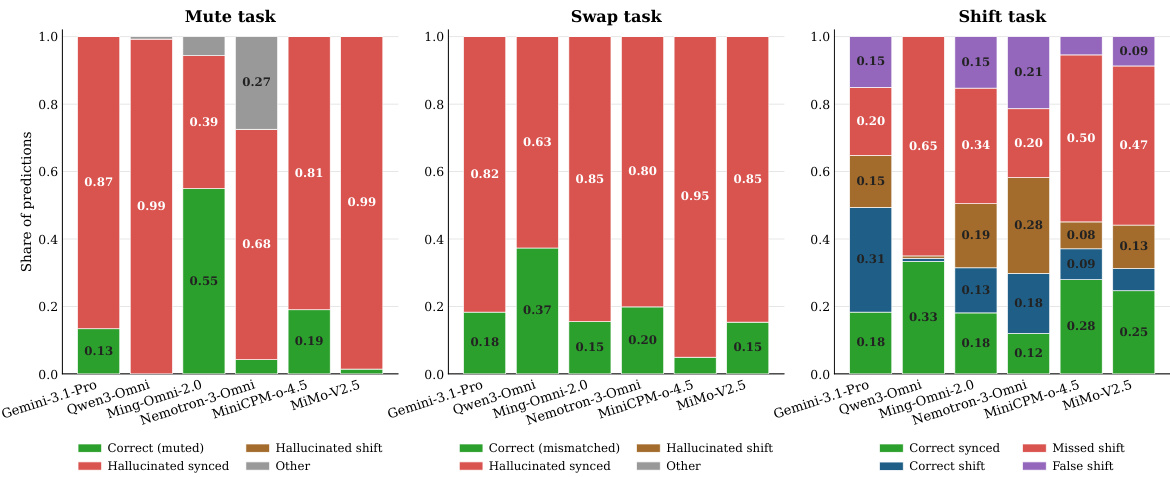
The authors analyze model performance across three audio-visual intervention tasks—Mute, Swap, and Shift—using stacked bar charts to show the distribution of predictions. Results indicate that most models exhibit strong reliance on visual shortcuts, particularly in hallucinating audio presence or synchrony, with minimal correct detection of audio absence or temporal misalignment. The best-performing models show improved accuracy in identifying desynchronized audio-visual pairs, especially in the Shift task, suggesting targeted training can enhance temporal grounding without degrading general capabilities. Models frequently hallucinate audio presence or synchrony, with minimal correct detection of audio absence or temporal misalignment. Performance drops significantly under counterfactual interventions, indicating strong reliance on visual shortcuts rather than genuine audio-visual alignment. Targeted training improves temporal grounding, with models showing stronger accuracy in detecting and localizing audio-visual desynchronization.
The authors analyze the performance of several multimodal models on audio-visual grounding tasks, focusing on their reliance on visual shortcuts and their ability to detect audio-visual inconsistencies. Results show that most models exhibit large performance drops under counterfactual interventions, indicating a strong dependence on visual priors rather than genuine audio-visual alignment. Targeted alignment training improves temporal grounding without degrading general capabilities, and the best-performing models demonstrate robustness to temporal shifts and accurate localization of audio-video misalignments. Most models show significant performance drops under counterfactual interventions, suggesting reliance on visual shortcuts rather than verifying audio presence, timing, and consistency. Targeted alignment training improves temporal synchronization without harming general video understanding, indicating effective learning of cross-modal alignment. The best-performing models exhibit robustness to temporal shifts and can accurately localize the direction and magnitude of audio-video misalignments, moving beyond simple desynchronization detection.
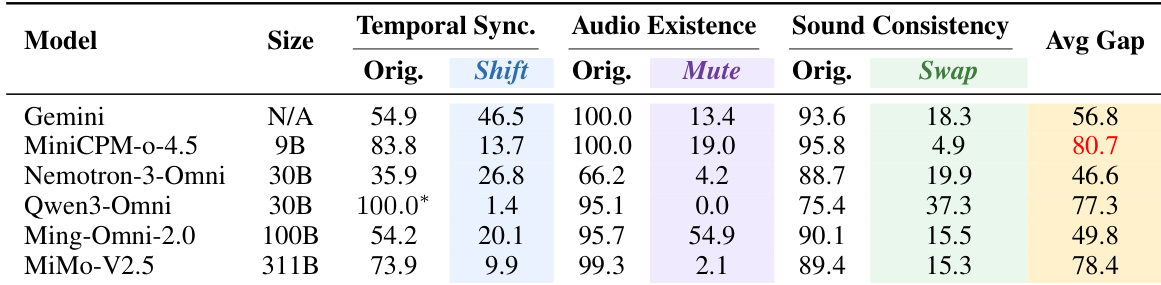
The authors compare the performance of various models on combined accuracy tasks involving audio-visual interventions and original conditions. Results show that their model outperforms others in both Mute and Swap intervention settings, indicating improved alignment and reduced reliance on visual shortcuts. The proposed model achieves the highest combined accuracy in both Mute and Swap intervention scenarios compared to other models. Performance improvements are observed across different models, with the proposed model showing significant gains in Mute and Swap tasks. The results suggest that the model is more effective at handling audio-visual interventions without falling back on visual priors.
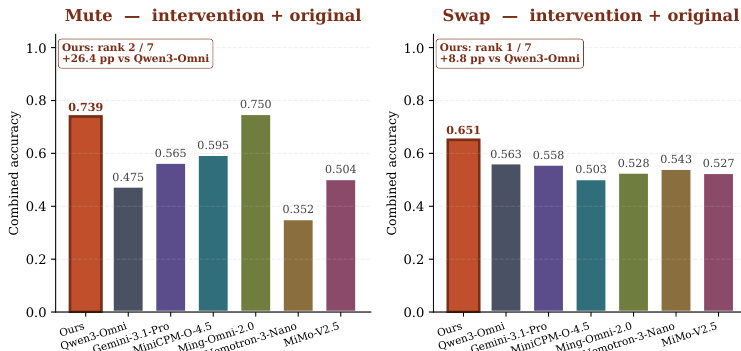
The evaluation assesses multimodal models' audio-visual grounding capabilities by applying counterfactual interventions such as muting, swapping, and shifting audio to validate their reliance on visual shortcuts versus genuine cross-modal alignment. Results reveal that most models heavily depend on visual priors, frequently hallucinating audio presence or synchrony and failing to detect temporal misalignments under disrupted conditions. Targeted alignment training effectively addresses this limitation by improving temporal synchronization and desynchronization localization without compromising general video understanding. Ultimately, the experiments demonstrate that explicit cross-modal training enables models to move beyond superficial visual dependencies and achieve robust audio-visual grounding.