Command Palette
Search for a command to run...
MemLens: 대규모 비전-언어 모델의 다중 모달 장기 메모션 벤치마킹
MemLens: 대규모 비전-언어 모델의 다중 모달 장기 메모션 벤치마킹
초록
메모리는 대규모 비전-언어 모델(LVLMs)이 길고 다중 모달적인 상호작용을 처리하는 데 필수적이며, 이러한 기능을 제공하는 두 가지 방법론적 방향은 장문 컨텍스트 LVLMs와 메모리 증강 에이전트입니다. 그러나 기존 벤치마크 중 진정한 의미의 다중 모달 증거가 필요한 질문들에 대해 이 두 가지를 체계적으로 비교하는 연구는 없습니다. 이러한 격차를 해소하기 위해, 우리는 다중 세션 대화에서의 메모리를 위한 포괄적인 벤치마크인 MEMLENS를 소개합니다. MEMLENS는 교차 모달 토큰 카운팅 체계 하에서 4가지 표준 컨텍스트 길이(32K-256K tokens)에서 5가지 메모리 능력(정보 추출, 다중 세션 추론, 시간적 추론, 지식 업데이트, 답변 거부)에 걸쳐 789개의 질문으로 구성됩니다. 이미지 제거 연구는 MEMLENS 해결에 시각적 증거가 필요함을 확인합니다: 증거 이미지가 포함된 질문의 80.4%에서 증거 이미지를 제거하면 두 개의 최첨단 LVLM의 정확도가 2% 미만으로 떨어집니다. 27개의 LVLMs와 7개의 메모리 증강 에이전트를 평가한 결과, 장문 컨텍스트 LVLMs는 직접적인 시각적 기반화를 통해 높은 단문 컨텍스트 정확도를 달성하지만 대화 길이가 증가함에 따라 성능이 저하되는 반면, 메모리 에이전트는 길이 안정성을 보이지만 저장 시간 압축 과정에서 시각적 충실도를 상실합니다. 다중 세션 추론은 대부분의 시스템을 30% 미만으로 제한하며, 어느 접근법 단독으로는 이 과제를 해결하지 못합니다. 이러한 결과는 장문 컨텍스트 어텐션과 구조화된 다중 모달 검색을 결합한 하이브리드 아키텍처의 필요성을 시사합니다. 우리의 코드는 https://github.com/xrenaf/MEMLENS에서 사용할 수 있습니다.
One-sentence Summary
MEMLENS is a comprehensive benchmark for multimodal long-term memory comprising 789 questions across five memory abilities and four standard context lengths ranging from 32K to 256K tokens under a cross-modal token-counting scheme to evaluate 27 large vision-language models and 7 memory-augmented agents, revealing that long-context LVLMs degrade as conversations grow while memory agents lose visual fidelity under storage-time compression, with multi-session reasoning capping most systems below 30% and neither approach alone solving the task.
Key Contributions
- The paper introduces MEMLENS, a comprehensive benchmark for memory in multimodal multi-session conversations comprising 789 questions across five memory abilities. This resource operates under a cross-modal token-counting scheme with four standard context lengths ranging from 32K to 256K tokens.
- An image-ablation study confirms that solving MEMLENS requires visual evidence by removing evidence images during testing. This experiment drops two frontier LVLMs below 2% accuracy on the 80.4% of questions whose evidence includes images.
- Comparative evaluation of 27 LVLMs and 7 memory-augmented agents shows that long-context models degrade as conversations grow while memory agents lose visual fidelity. Results demonstrate that multi-session reasoning caps most systems below 30%, indicating neither approach alone solves the task.
Introduction
Large Vision-Language Models are increasingly deployed in scenarios requiring the retention of information across extended multimodal contexts. Current evaluation methods often lack standardized metrics for assessing long-term memory or rely on inefficient manual grading processes. The authors introduce MEMLENS, a benchmark designed to rigorously test these memory capabilities in vision-language systems. To ensure scalable and consistent assessment, they leverage an LLM-as-Judge framework that prioritizes final committed answers over intermediate reasoning traces.
Dataset
-
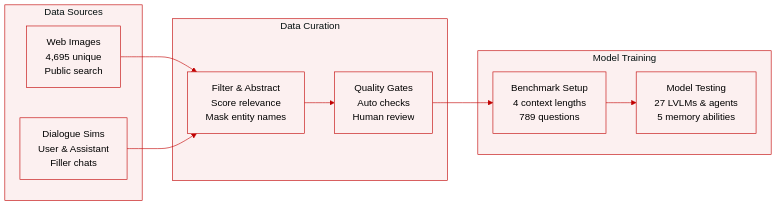
Dataset Composition and Sources
- The authors introduce MEMLENS, a benchmark comprising 789 questions designed to evaluate memory in multimodal multi-session conversations.
- The data is instantiated at four standardized context lengths (32K, 64K, 128K, and 256K tokens) using a cross-modal token-counting scheme.
- Visual evidence consists of 4,695 unique images retrieved from public web searches via iCrawler against a non-person-centric topic ontology.
- Dialogue sessions are simulated using GPT-5.1 as the user and Gemini-3-Pro as the assistant, with filler sessions drawn from ShareGPT and UltraChat to maintain authentic conversational patterns.
-
Key Details for Each Subset
- The dataset covers five core memory abilities: Information Extraction, Multi-Session Reasoning, Temporal Reasoning, Knowledge Update, and Answer Refusal.
- Information Extraction includes subtypes like Entity questions that require a two-hop chain of visual identification followed by text retrieval.
- Multi-Session Reasoning evaluates aggregation across three to eight sessions through counting, arithmetic, or entity resolution operations.
- Cross-modal dependency is enforced such that 65.7% of questions are image-essential, meaning the answer is unrecoverable without the evidence image.
- Answer Refusal items remove all supporting evidence to test if the model can decline to answer rather than hallucinate.
-
Usage in the Model Evaluation
- The benchmark is used exclusively for evaluation to compare 27 LVLMs and 7 memory-augmented agents across all four context lengths.
- The authors explicitly state that the dataset is not intended as a training resource to avoid compromising its diagnostic value.
- Evaluation results highlight that long-context LVLMs achieve high short-context accuracy but degrade as conversations grow, while memory agents remain length-stable but lose visual fidelity.
- Performance is tracked per memory ability to ensure that strong information extraction does not falsely predict success in multi-session reasoning.
-
Processing and Construction Details
- A four-stage pipeline builds the data, starting with topic sampling and ending with conversation history assembly where evidence sessions are interleaved with distractors.
- Entity abstraction replaces specific names in text with anaphors referencing the image to enforce joint visual-textual reasoning.
- Image filtering applies multi-channel relevance scoring using CLIP and SigLIP, followed by negative-content checks for watermarks and logos.
- Quality control involves automated text-only judges to prevent shortcuts and three rounds of human review to verify naturalness and evidence recoverability.
- Metadata for each image includes source URLs, retrieval timestamps, perceptual hashes, and model scores to support reproducibility and takedown requests.
Method
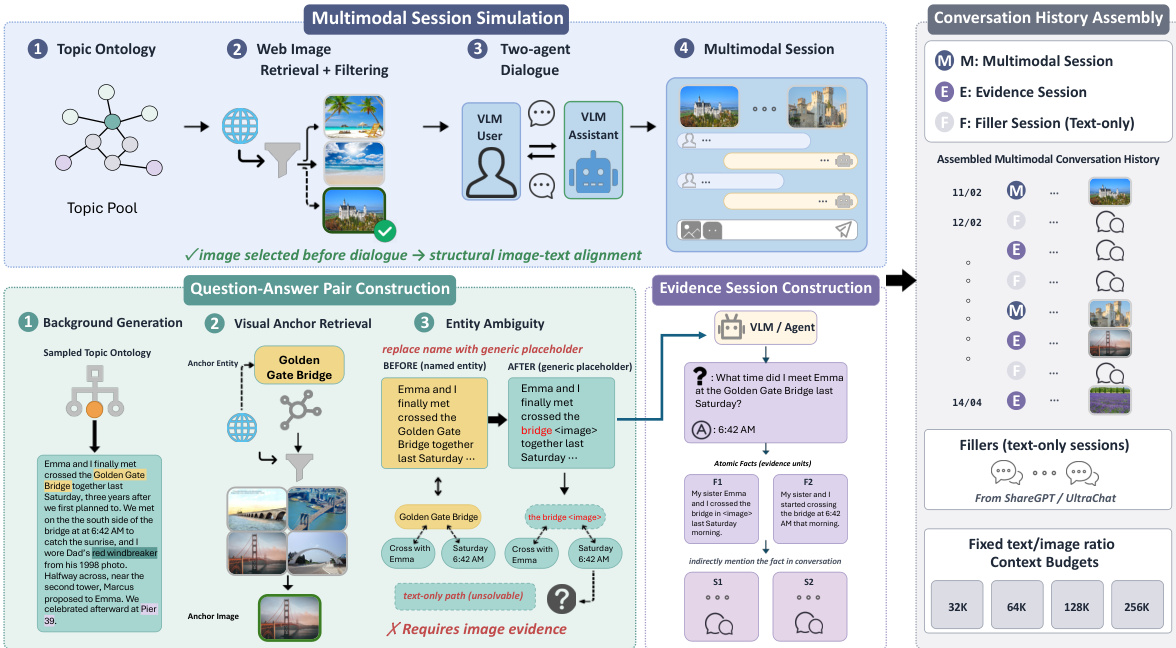
The authors propose a comprehensive pipeline for synthesizing multimodal conversation data, designed to rigorously test retrieval capabilities within long-context scenarios. The overall framework integrates session simulation, question-answer pair construction, and history assembly to create complex, interleaved dialogue histories. Refer to the framework diagram.
The process begins with Multimodal Session Simulation, which generates the "haystack" or background conversation. This module initiates with a Topic Ontology to define the thematic scope. Web images are subsequently retrieved and filtered to ensure visual quality before being integrated into a two-agent dialogue between a VLM User and a VLM Assistant. The generation is driven by a persona profile and conversation summary, utilizing a specific prompt template that encourages natural photo sharing within the message body. This approach ensures that the resulting sessions remain authentically multimodal rather than text-only sessions with images appended as side annotations.
To introduce specific retrieval challenges, the pipeline employs a Question-Answer Pair Construction module. This section starts with Background Generation sampled from the topic ontology, followed by Visual Anchor Retrieval to identify key entities, such as a specific landmark. A critical step involves Entity Ambiguity, where specific named entities in the text are replaced with generic placeholders. This modification ensures that the associated fact cannot be resolved through text alone, thereby requiring the model to utilize the visual anchor as evidence.
Once the atomic facts are established, the Evidence Session Construction module wraps them into multi-turn sessions that are structurally indistinguishable from the main conversation. A VLM or Agent generates these sessions using a tailored prompt that targets a length of 250 to 350 words per turn. The instructions direct the assistant to provide helpful context and knowledge-oriented follow-ups while avoiding personal or social questions. A six-stage validator chain, covering rule-based length, photo directives, and semantic leakage, determines whether a generated turn is accepted or regenerated.
Finally, the Conversation History Assembly module combines these components into a unified timeline. The assembly interleaves Multimodal Sessions (M), Evidence Sessions (E), and Filler Sessions (F), which are text-only. This mixing strategy creates a long-context input with fixed text-to-image ratios, supporting various context budgets ranging from 32K to 256K tokens.
Experiment
This study evaluates 27 LVLMs and seven memory-augmented agents across varying context lengths on the MEMLENS benchmark to assess long-context memory capabilities. Experiments reveal that LVLMs suffer performance degradation at longer contexts due to evidence dilution, whereas memory agents maintain length invariance but lag on visually grounded tasks because of lossy information compression during storage. Analysis of error types and correlations confirms distinct difficulty axes for retrieval and aggregation, motivating hybrid designs that preserve pixel-level evidence while managing context scaling.
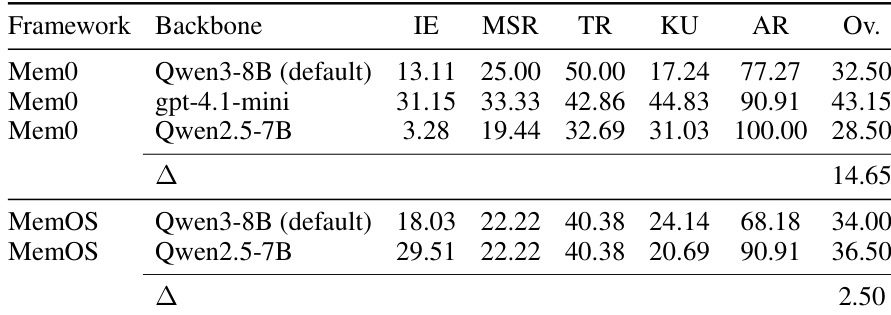
The study investigates how backbone model selection impacts the performance of Mem0 and MemOS memory frameworks across various reasoning tasks. Results indicate that Mem0 is highly sensitive to backbone choice with significant performance variance, whereas MemOS maintains stable or slightly improved accuracy with alternative backbones. This suggests that architectural integration and model calibration play a crucial role alongside raw backbone capability. Mem0 exhibits a wide performance gap across backbones, with the gpt-4.1-mini variant achieving the highest overall accuracy. MemOS shows robustness to backbone substitution, where switching to Qwen2.5-7B yields a marginal improvement over the default model. Different backbones prioritize different capabilities, such as one variant achieving superior answer refusal rates while another leads in temporal reasoning.
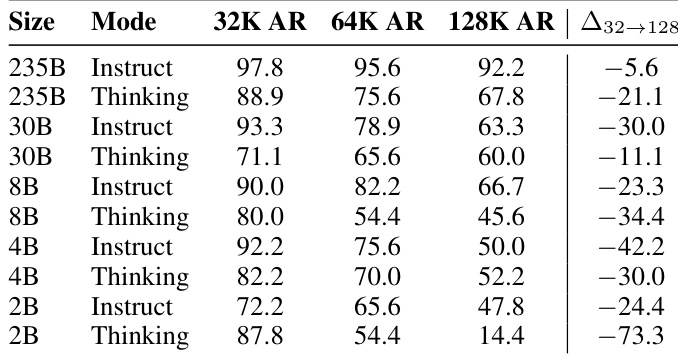
The the the table evaluates Answer Refusal accuracy across varying model sizes and operational modes at increasing context lengths. Results show a consistent decline in performance as context expands, with the degradation being most pronounced for smaller models and specific decoding modes. This trend highlights the vulnerability of abstention behavior in long-context scenarios, particularly for smaller architectures. Refusal accuracy consistently decreases as context length expands from 32K to 128K across all configurations. Larger models demonstrate better retention of refusal accuracy compared to smaller models at longer context lengths. The smallest model in Thinking mode suffers the most severe performance collapse, indicating a critical failure in abstention behavior.
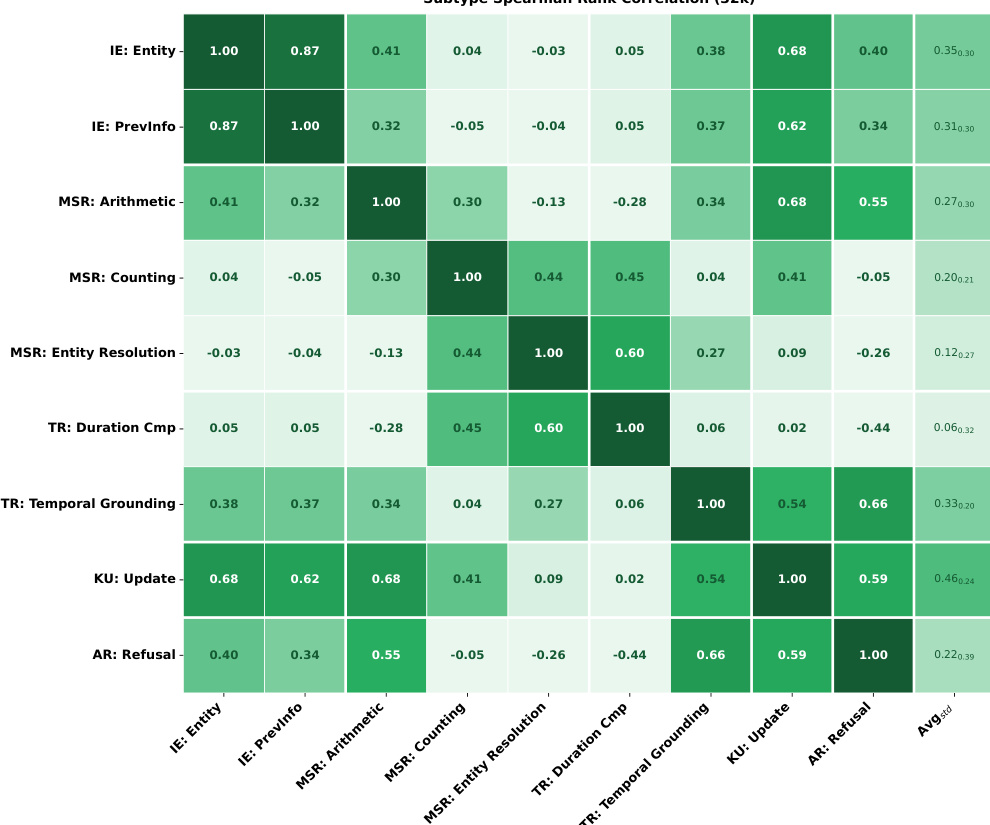
The authors analyze pairwise Spearman correlations among memory ability subtypes at 32K context length across 34 evaluated models to determine if tasks measure a single capability. The heatmap reveals substantial variation in correlations, indicating that memory abilities are distinct rather than monolithic. Specifically, retrieval-oriented tasks cluster together while reasoning-heavy tasks show independent performance profiles. Information Extraction and Knowledge Update tasks demonstrate the strongest positive correlations, indicating a shared dependency on evidence retrieval capabilities. Multi-Session Reasoning subtypes exhibit weak or negligible correlations with Information Extraction tasks, highlighting a distinct aggregation challenge separate from retrieval. Answer Refusal shows divergent relationships across task types, correlating positively with Knowledge Update but negatively with Temporal Reasoning duration comparisons.
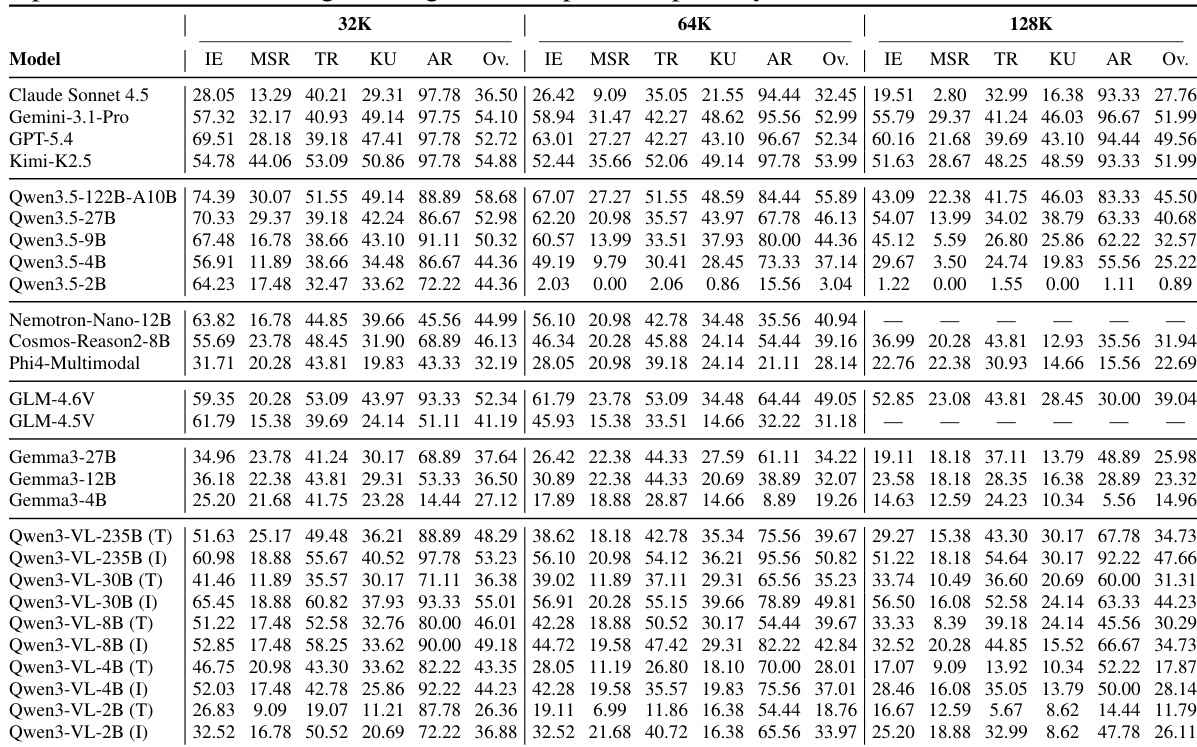
The evaluation reveals that while short-context accuracy is similar across top models, performance diverges significantly as context length increases to 128K. Closed-source systems generally maintain higher robustness compared to open-weight models, which suffer from steeper declines in hallucination control and retrieval tasks. Additionally, memory-augmented agents exhibit different scaling behaviors, remaining length-invariant but lagging behind direct LVLMs on visually grounded tasks. Performance gaps widen at longer context lengths, with open-weight models showing substantial accuracy drops compared to closed-source leaders. Multi-Session Reasoning remains the most challenging task type for all systems, while Answer Refusal accuracy degrades notably as context grows. No single model family dominates all memory abilities, with different architectures excelling in specific categories like Temporal Reasoning versus Knowledge Update.
The authors validate their LLM-as-Judge evaluation protocol by comparing its scoring against human consensus, revealing specific patterns of leniency where the automated judge incorrectly credits answers. The analysis highlights that Information Extraction and Answer Refusal tasks generate the most disagreements, driven by the judge accepting partial factual matches and hedge phrases respectively. Information Extraction errors are characterized by the judge accepting partial matches on short factual answers. Answer Refusal disagreements arise when hedge phrases are incorrectly credited as valid refusals. Knowledge Update conflicts stem from mismatches between verbose correct answers and literal requirements.

The study evaluates memory frameworks and model capabilities across varying backbone selections, context lengths, and task types to assess robustness and specialization. Results indicate that architectural integration impacts stability more than raw capability, while performance generally degrades as context length increases with smaller models suffering severe declines in abstention behavior. Furthermore, correlation analysis reveals memory abilities are distinct rather than monolithic, and automated evaluation protocols exhibit specific leniency patterns in information extraction and refusal tasks compared to human consensus.