Command Palette
Search for a command to run...
KVPO: KV 의미 탐색을 통한 자동 회귀 비디오 정렬을 위한 ODE-네이티브 GRPO
KVPO: KV 의미 탐색을 통한 자동 회귀 비디오 정렬을 위한 ODE-네이티브 GRPO
Ruicheng Zhang Kaixi Cong Jun Zhou Zhizhou Zhong Zunnan Xu Shuiyang Mao Wei Liu Xiu Li
초록
스트리밍 자기회귀(AR) 비디오 생성기를 인간의 선호도와 정렬하는 것은 어렵습니다. 기존 강화학습 방법은 주로 노이즈 기반 탐색과 SDE 기반 대리 정책(policy)에 의존하는데, 이는 증류된 AR 모델의 결정론적 ODE 동역학과 불일치하며, 장기적 일관성에 중요한 고수준 의미론적 스토리라인 진행보다는 저수준 외관을 교란시키는 경향이 있습니다. 이러한 한계를 해결하기 위해, 우리는 스트리밍 비디오 생성기를 정렬하기 위한 ODE 네이티브 온라인 그룹 상대 정책 최적화(Group Relative Policy Optimization, GRPO) 프레임워크인 KVPO를 제시합니다. 다양성 탐색을 위해, KVPO는 확률적 노이즈의 원천을 역사적 KV 캐시로 이동시키는 인과-의미론적 탐색(causal-semantic exploration) 패러다임을 도입합니다. 역사적 KV 엔트리를 확률적으로 라우팅함으로써, 데이터 매니폴드 위에 엄격하게 머무르면서 의미론적으로 다양한 생성 분기를 구성합니다. 정책 모델링을 위해, KVPO는 흐름 일치(flow-matching) 속도 공간에서 분기 가능성을 정량화하고 네이티브 ODE 공식과 완전히 일치하는 보상 가중 대비 목적 함수(reward-weighted contrastive objective)를 생성하는 궤적 속도 에너지(Trajectory Velocity Energy, TVE) 기반 속도 필드 대리 정책을 도입합니다. 여러 증류된 AR 비디오 생성기에 대한 실험은 단일 프롬프트 단편 비디오 및 다중 프롬프트 장편 비디오 설정 모두에서 시각적 품질, 운동 품질, 텍스트-비디오 정렬 일관성 있는 개선을 보여줍니다.
One-sentence Summary
the paper present KVPO, an ODE-native online Group Relative Policy Optimization framework that aligns streaming autoregressive video generators by replacing noise-based exploration with causal-semantic routing of historical KV cache entries and a velocity-field surrogate policy based on Trajectory Velocity Energy, yielding consistent gains in visual quality, motion quality, and text-video alignment across single-prompt short and multi-prompt long video settings.
Key Contributions
- The paper introduces KVPO, an ODE-native online Group Relative Policy Optimization framework that aligns streaming autoregressive video generators by conducting preference optimization directly within the flow-matching velocity-field space.
- The method replaces stochastic noise perturbation with a causal-semantic exploration mechanism that stochastically routes historical key-value cache entries to construct semantically diverse generation branches while preserving strict on-manifold trajectory coherence.
- A velocity-field surrogate policy based on Trajectory Velocity Energy yields a reward-weighted contrastive objective that embeds preference optimization into native ODE dynamics. Empirical evaluations on distilled autoregressive video generators demonstrate consistent improvements in visual quality, motion fidelity, and text-video alignment across both single-prompt short-video and multi-prompt long-video settings.
Introduction
Real-time interactive video generation requires low-latency, streaming synthesis that preserves long-horizon coherence and semantic progression, yet aligning distilled autoregressive video models with human preferences remains a significant hurdle. Existing alignment methods struggle because reward-weighted distillation lacks active exploration, while stochastic noise injection breaks the native deterministic flow, perturbs low-level appearance, and pushes generations off the data manifold. Even recent geometric distance-based approaches fail to capture intrinsic preference structures due to unrealistic latent space assumptions. To overcome these limitations, the authors introduce KVPO, an ODE-native online policy optimization framework that replaces unstructured noise with strategic routing of historical key-value cache entries. By operating directly within the flow-matching velocity-field space, the framework enables causal-semantic exploration and constructs a surrogate policy using Trajectory Velocity Energy, effectively embedding preference alignment into the model's native dynamics while maintaining on-manifold coherence and narrative diversity.
Method
The authors present KVPO, an ODE-native online Group Relative Policy Optimization framework designed for aligning streaming autoregressive video generators with human preferences. The overall architecture operates in three primary phases: causal-semantic exploration, velocity-field surrogate policy modeling, and policy optimization, as illustrated in the framework diagram.
The framework begins with causal-semantic exploration, which is implemented through a mechanism called Causal History Routing (CHR). This approach redirects diversity exploration from stochastic noise to the historical Key-Value (KV) cache, specifically targeting the local cache within a controllable window. The local cache is structured with a fixed 9-slot layout: the last three slots store the most recent frames, while the first six are filled stochastically from older historical frames. For each generation branch, a set of indices from the older history is sampled to populate these six slots, creating semantically diverse generation trajectories. The sink KV, which stores the earliest frames, remains unchanged to preserve long-range coherence. This process generates multiple candidate branches from a shared initial noise, enabling exploration of different narrative paths without disrupting the underlying data manifold.

As shown in the figure below, this causal-semantic exploration produces diverse branches that maintain high-level structural coherence, unlike noise-space exploration which often results in off-manifold distortions and low-level structural failures.
Following exploration, the framework enters the replay phase for policy modeling. The intermediate latent states from the perturbed blocks within the exploration window are replayed under the original, unperturbed deployment-time context. This allows the model to assess its own generative tendency towards each candidate branch. The core of the surrogate policy is the Trajectory Velocity Energy (TVE), which is defined as the aggregated squared residual between the cached rollout velocity targets and the velocities predicted by the model during replay. This energy metric quantifies the likelihood of the current policy generating a given branch under the unperturbed context.
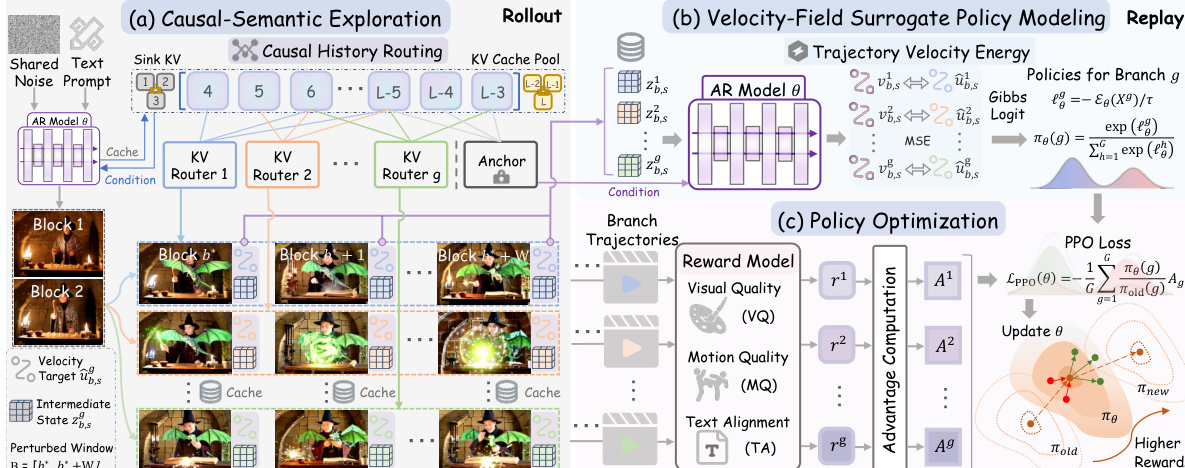
The TVE values are then converted into a normalized branch distribution using a Gibbs parameterization, forming the surrogate policy. The policy probability for a branch is inversely proportional to its TVE, ensuring that branches with lower energy (i.e., more likely under the current policy) receive higher probability. This policy is differentiable and depends only on relative energy scores, making it suitable for gradient-based optimization.
The final phase is policy optimization, which uses the computed surrogate policy to update the autoregressive model. The framework computes a reward for each branch and the anchor trajectory, and then calculates the normalized advantage for each branch. The PPO objective is then optimized, with the importance ratio derived from the surrogate policy probabilities. To prevent the policy from drifting too far from the pretrained distribution, a KL divergence penalty is applied. The total training objective combines the PPO loss with this KL regularization term.

Experiment
KVPO was evaluated on state-of-the-art autoregressive video generators across single-prompt short and multi-prompt long generation tasks, with performance benchmarked against established post-training baselines. Comprehensive assessments demonstrate that the method consistently enhances semantic coherence, visual fidelity, and cross-segment consistency while effectively preserving subject identity during complex prompt transitions, a finding further validated by human preference studies that attribute these gains to causal-semantic exploration and velocity-field surrogate policies. Ablation analyses confirm that precise tuning of causal history routing and velocity-field-based optimization are essential for stable training, establishing KVPO as a robust framework for aligning video generators with intricate narrative preferences.
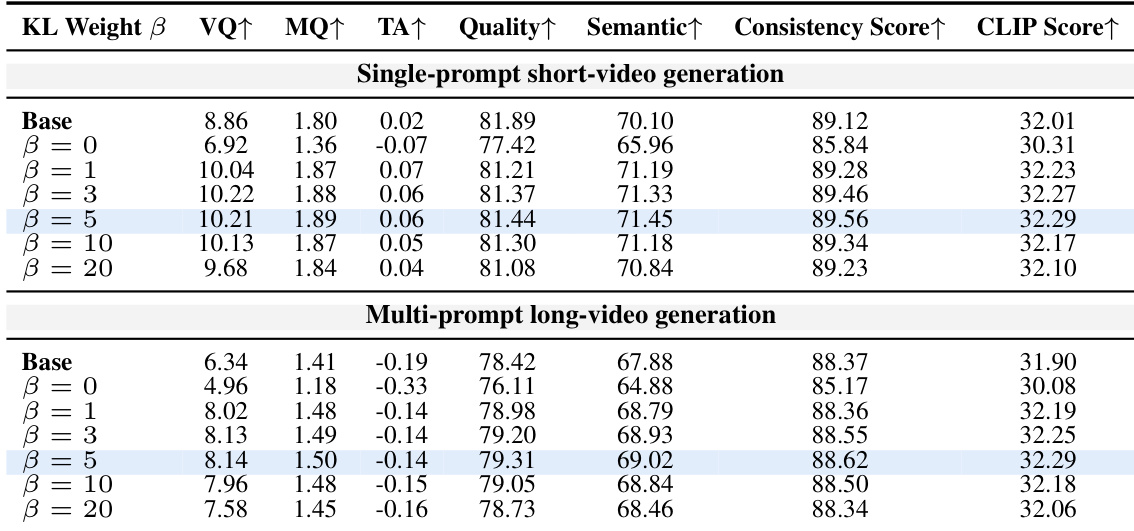
The authors evaluate KVPO on autoregressive video generation models, comparing performance across single-prompt short-video and multi-prompt long-video settings. Results show consistent improvements across multiple metrics when using KVPO, with the optimal configuration achieved at a specific hyperparameter setting, particularly in long-video generation. KVPO improves performance across all evaluated metrics in both short-video and long-video generation tasks. The optimal performance is achieved at a specific hyperparameter setting, with diminishing returns or degradation at higher values. KVPO demonstrates consistent superiority over baselines, particularly in long-video generation, indicating better handling of complex, multi-prompt scenarios.
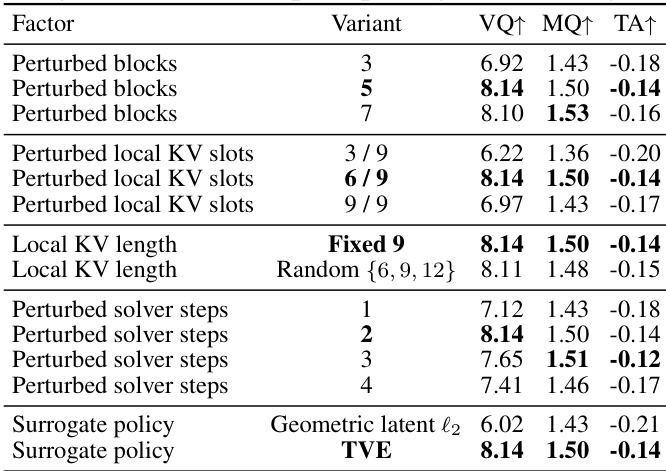
The authors conduct an ablation study on the core components of KVPO, focusing on the impact of different hyperparameters in the causal history routing mechanism and the surrogate policy design. Results show that specific configurations, such as perturbing a certain number of blocks and solver steps, lead to optimal performance across multiple metrics, while alternative policy formulations significantly degrade results. The study demonstrates that the choice of perturbation strategy and policy type is critical for maintaining both performance and stability. Perturbing a specific number of blocks and local KV slots achieves the best balance between performance and memory efficiency. Optimal performance is achieved with a fixed local KV length and perturbing the first two solver steps. The velocity-field-based surrogate policy outperforms a geometric latent space policy, highlighting the importance of alignment with the model's intrinsic dynamics.
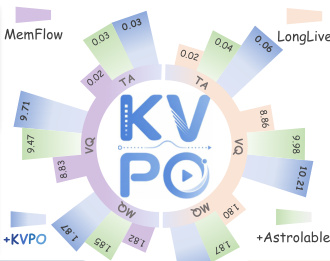
The authors evaluate KVPO on two autoregressive video generators, LongLive and MemFlow, comparing it against Astrolabe in both single-prompt short-video and multi-prompt long-video generation settings. Results show consistent improvements across all metrics, with KVPO outperforming baselines in both settings and achieving higher human preference ratings. The method demonstrates enhanced semantic coherence, motion continuity, and prompt grounding, attributed to causal-semantic exploration and a velocity-field surrogate policy. KVPO achieves consistent improvements over baselines across all evaluation metrics in both short-video and long-video generation settings. KVPO outperforms Astrolabe in both settings, with the performance gap widening in multi-prompt long-video generation. Ablation studies confirm the importance of causal history routing and the velocity-field surrogate policy for optimal performance.
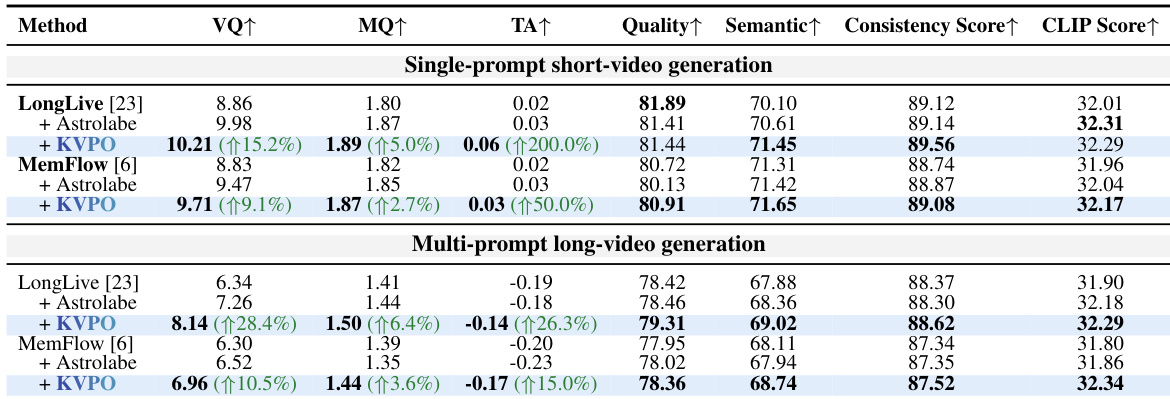
The authors evaluate KVPO on autoregressive video generation models across single-prompt short-video and multi-prompt long-video settings, with the primary experiments validating its overall ability to enhance semantic coherence, motion continuity, and prompt grounding compared to standard baselines. A dedicated ablation study then validates the method's core architectural choices, confirming that targeted causal history routing and a velocity-field surrogate policy are essential for balancing generation quality with memory efficiency. Collectively, these results demonstrate that KVPO reliably improves video synthesis, with its performance advantages becoming increasingly significant in complex, multi-prompt long-video scenarios.