Command Palette
Search for a command to run...
ELF: 내장형 언어 흐름(Embedded Language Flows)
ELF: 내장형 언어 흐름(Embedded Language Flows)
Keya Hu Linlu Qiu Yiyang Lu Hanhong Zhao Tianhong Li Yoon Kim Jacob Andreas Kaiming He
초록
디퓨전(Diffusion) 및 흐름 기반(Flow-based) 모델은 이미지 및 비디오와 같은 도메인에서 연속 데이터 생성을 위한 사실상의(de facto) 접근 방식으로 자리 잡았습니다. 이러한 성공은 언어 모델링에 이러한 모델을 적용하려는 관심이 점차 증가하는 계기가 되었습니다. 이미지 도메인의 대응 모델과 달리, 현재 가장 선도적인 디퓨전 언어 모델(DLM, Diffusion Language Models)은 주로 이산 토큰(Discrete tokens) 상에서 동작합니다. 본 논문에서는 최소한의 이산 도메인 적응으로도 연속 DLM이 효과적으로 동작할 수 있음을 입증합니다. 우리는 연속 시간 Flow Matching을 기반으로 하며 연속 임베딩 공간(continuous embedding space)에서 동작하는 디퓨전 모델 계열인 Embedded Language Flows(ELF)를 제안합니다. 기존 DLM과 달리 ELF는 최종 시간 단계까지 연속 임베딩 공간 내에 주로 머무르며, 이 단계에서 공유 가중치 네트워크(shared-weight network)를 통해 이산 토큰으로 매핑됩니다. 이러한 공식화(formulation)는 분류기 없는 가이드런스(classifier-free guidance, CFG)와 같은 이미지 도메인 디퓨전 모델의 확립된 기법을 적용하는 것을 용이하게 만듭니다. 실험 결과는 ELF가 주요 이산 및 연속 DLM을 크게 능가하며, fewer sampling steps로도 더 우수한 생성 품질을 달성함을 보여줍니다. 이러한 결과는 ELF가 효과적인 연속 DLM 구현을 위한 유망한 경로임을 시사합니다.
One-sentence Summary
The authors propose Embedded Language Flows (ELF), a class of diffusion models operating in continuous embedding space based on continuous-time Flow Matching, which maps to discrete tokens only at the final time step, facilitating image-domain techniques like classifier-free guidance and substantially outperforming leading discrete and continuous DLMs with better generation quality and fewer sampling steps.
Key Contributions
- The work introduces Embedded Language Flows (ELF), a class of diffusion models operating in continuous embedding space based on continuous-time Flow Matching.
- This architecture predominantly stays within the continuous embedding space until the final time step, mapping to discrete tokens via a shared-weight network to support techniques like classifier-free guidance.
- Experiments demonstrate that ELF substantially outperforms leading discrete and continuous diffusion language models by achieving better generation quality with fewer sampling steps.
Introduction
Diffusion and flow-based models dominate continuous data generation in domains like images and videos, but language modeling has largely shifted toward discrete approaches due to performance concerns. Prior continuous diffusion language models often struggle with per-step discretization losses or require separate decoders to map latent representations back to tokens. The authors introduce Embedded Language Flows (ELF), which utilizes continuous-time Flow Matching to operate primarily within the continuous embedding space. This design delays discretization until the final time step, removing the need for an explicit decoder and allowing the adoption of image-domain techniques such as classifier-free guidance. Empirical results show that ELF outperforms leading discrete and continuous models while requiring fewer sampling steps and significantly less training data.
Dataset
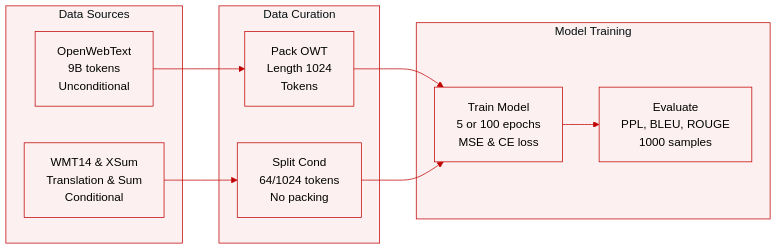
- Dataset Composition and Sources: The authors utilize OpenWebText for unconditional generation tasks and rely on WMT14 German-to-English and XSum for conditional machine translation and summarization.
- Key Subset Details: OpenWebText consists of approximately 9B tokens. The WMT14 dataset includes 144M total target tokens with a maximum sequence length of 128. XSum contains 6M total target tokens with a sequence length of 1088.
- Training and Usage: Unconditional sequences are packed to length 1024 and trained for 5 epochs. Conditional data is processed as sequence-to-sequence tasks without packing over 100 epochs. The training objective combines MSE loss for 80% of steps and CE loss for the remaining 20%.
- Processing Strategies: Conditional tasks enforce specific length splits. Machine translation allocates 64 tokens for both condition and target. Summarization uses 1024 tokens for the condition and 64 for the target. Evaluation for unconditional generation involves creating 1,000 samples to assess perplexity and entropy.
Method
The authors introduce Embedded Language Flows (ELF), a continuous diffusion language model that performs denoising primarily in continuous embedding space. This approach converts clean embeddings back to discrete tokens only at the final step, allowing the model to leverage techniques from continuous diffusion while maintaining discrete output.
Refer to the framework diagram showing the trajectory from noise to discrete tokens:

The process begins by mapping discrete tokens s=[s1,…,sL] into a continuous embedding space x, typically using a pretrained encoder like T5. The model then learns a flow path from noise ϵ to data x using Flow Matching. The noisy latent variable is defined by linear interpolation: zt=tx+(1−t)ϵ, where t∈[0,1]. Instead of predicting the velocity field directly, ELF adopts an x-prediction parameterization, where the network outputs a prediction of the clean embedding xθ(zt,t).
Refer to the overview of the training and sampling pipeline:
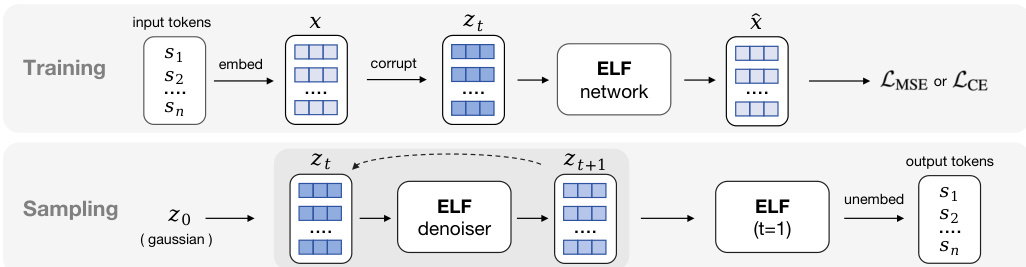
During training, the model minimizes the mean squared error (MSE) between the predicted and target velocity for the denoising branch. For the final decoding step (t=1), the network operates in a "decode" mode, projecting the predicted embeddings through an unembedding matrix to compute a cross-entropy loss against the ground-truth tokens. This allows a single network with shared weights to handle both intermediate denoising and final discretization.
Refer to the detailed training pipeline illustrating input preprocessing:
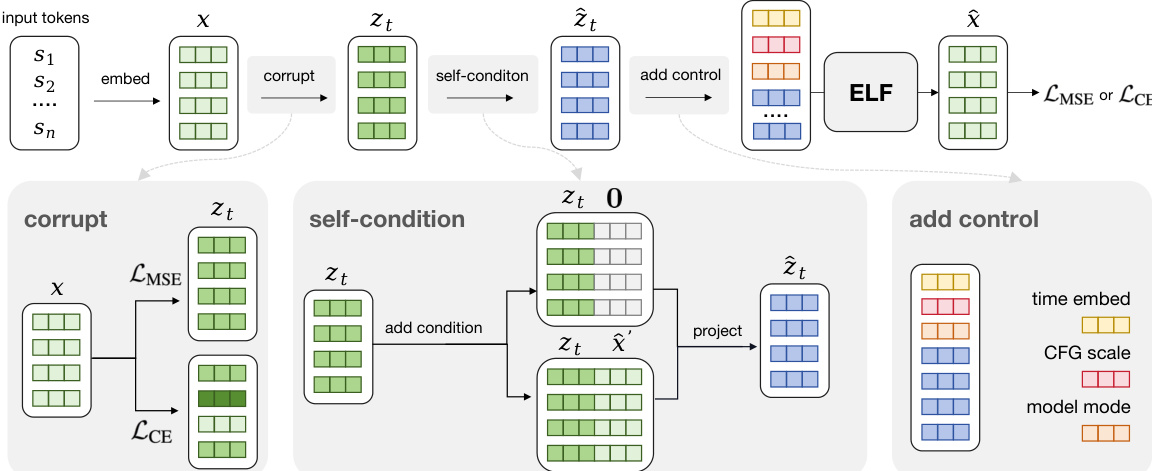
As shown in the detailed training diagram, the input embeddings undergo three key preprocessing steps before entering the ELF network. First, the "corrupt" module adds noise to the clean embeddings to create zt. Second, the "self-condition" module concatenates either a null vector or the previous prediction x^′ to the noisy embeddings, which is then projected back to the original dimension. Finally, the "add control" module prepends control tokens encoding the time step, CFG scale, and model mode (denoise or decode). This in-context conditioning strategy avoids the parameter overhead of separate conditioning modules like adaLN-Zero.
During inference, ELF iteratively transforms noisy samples into clean embeddings by solving the ordinary differential equation (ODE) defined by the flow velocity. Starting from Gaussian noise z0, the model updates the latent state over time steps t∈[0,1]. At the final step t=1, the model switches to the decode mode to unembed the continuous representation into discrete tokens via an argmax operation. The authors also support an SDE-inspired sampler that injects small noise at each step to emulate stochastic dynamics.
Experiment
Experiments evaluate ELF on unconditional generation and conditional tasks against discrete and continuous diffusion language models. Ablation studies demonstrate that pretrained contextual embeddings, shared-weight decoding, and stochastic sampling optimize the quality-diversity trade-off, while model scaling consistently improves performance. System-level comparisons show ELF achieves superior inference and data efficiency compared to baselines including distilled variants without additional training stages. Furthermore, ELF outperforms autoregressive and diffusion models on conditional tasks by generating fluent text that semantically aligns with input contexts.
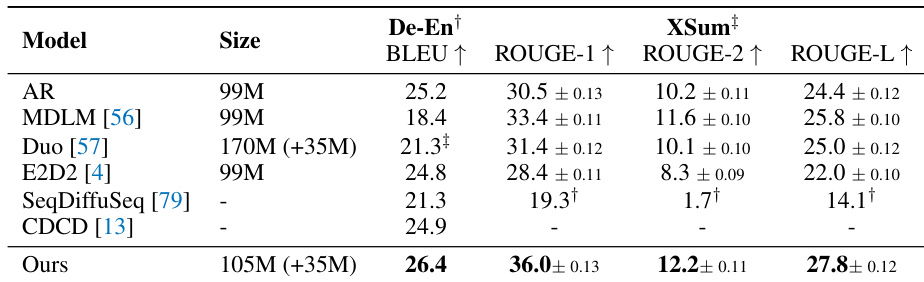
The authors compare their proposed model against several autoregressive and diffusion-based baselines on machine translation and summarization tasks. The results indicate that their model achieves superior performance across all evaluated metrics, outperforming competing methods in both translation quality and summarization fidelity. This high performance is maintained despite the model having a parameter count that is competitive with or smaller than several baselines. The proposed model achieves the best performance on WMT14 German-to-English translation compared to all listed baselines. It secures the highest scores across all ROUGE metrics for the XSum summarization task. The model delivers top-tier results with a parameter size that is comparable to or smaller than many competing architectures.
The the the table and text compare the training efficiency of ELF against various baseline discrete and continuous diffusion language models, highlighting a significant difference in data usage. While baseline methods typically require over 500 billion effective training tokens and often utilize additional distillation stages, ELF achieves its results with a drastically smaller training budget of approximately 45 billion tokens. This demonstrates that the proposed model is substantially more data-efficient than prior approaches. ELF utilizes approximately 45 billion effective training tokens, which is roughly an order of magnitude fewer than the over 500 billion tokens required by baseline models. Baseline methods often incorporate distillation training phases which increase their total token consumption, whereas ELF relies solely on base training. The efficiency ratio indicates that baseline training budgets are more than ten times larger than the budget used for the proposed model.
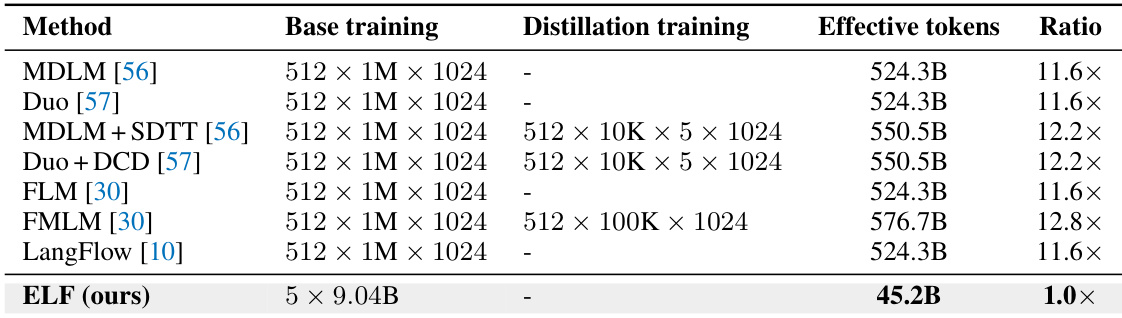
The authors analyze the impact of classifier-free guidance and sampling strategies on the generative perplexity and entropy trade-off across three model scales. Results indicate that SDE sampling consistently outperforms ODE sampling by achieving lower perplexity, while increasing the guidance scale generally reduces perplexity at the cost of diversity. Additionally, scaling up the model size improves the overall quality-diversity frontier. Increasing the classifier-free guidance scale reduces generative perplexity but lowers entropy. SDE sampling consistently achieves lower generative perplexity compared to ODE sampling. Larger model sizes improve the generative perplexity-entropy frontier.
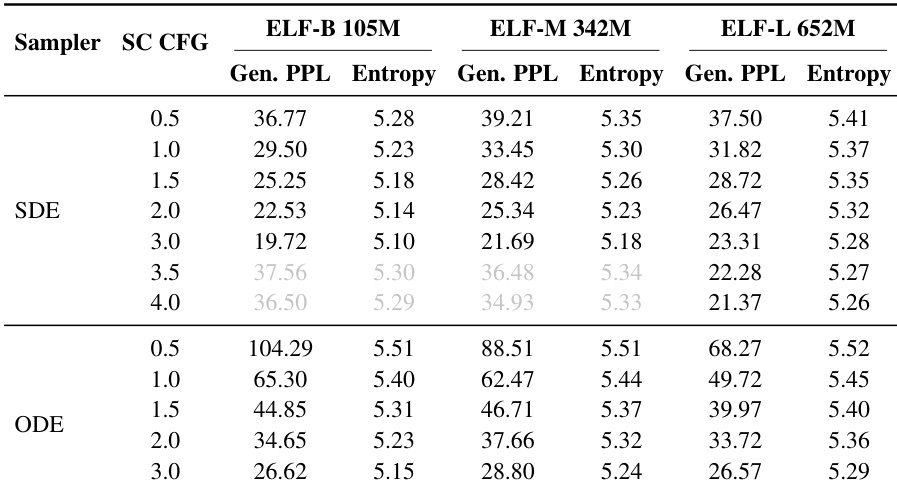
The authors evaluate three model scales, ELF-B, ELF-M, and ELF-L, to analyze scaling behavior across different parameter counts. Results indicate that increasing model size consistently improves the generative perplexity-entropy frontier, with larger models achieving better quality at similar diversity levels. The largest model variant is configured with 652M parameters, while the smallest uses 105M. Model depth and hidden size increase progressively across the three variants. Training epochs decrease slightly as model size increases, with the largest model requiring fewer epochs.

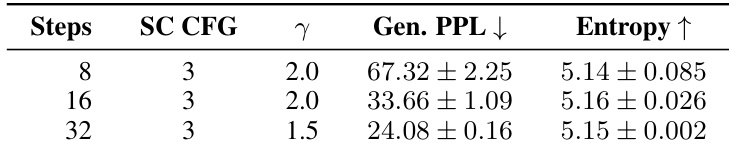
The authors evaluate the impact of sampling steps on unconditional generation quality using SDE sampling with a self-conditioning CFG scale of 3. Results indicate that increasing the number of steps from 8 to 32 significantly lowers generative perplexity, demonstrating improved sample quality. Throughout this progression, entropy remains stable, suggesting that the model maintains consistent diversity despite the changes in sampling budget. Increasing sampling steps substantially reduces generative perplexity. Entropy remains stable across different step budgets. The experiment compares 8, 16, and 32 steps with adjusted noise injection scales.
The authors evaluate their proposed model against autoregressive and diffusion baselines on machine translation and summarization tasks, demonstrating superior performance with competitive parameter counts. Efficiency analysis reveals the model requires significantly fewer training tokens than prior approaches that often rely on distillation. Further investigations into sampling strategies and model scaling indicate that stochastic differential equation sampling and larger architectures consistently enhance generation quality without compromising diversity.