Command Palette
Search for a command to run...
Qwen-Image-2.0 기술 보고서
Qwen-Image-2.0 기술 보고서
초록
우리는 Qwen-Image-2.0을 소개합니다. 이는 고품질 생성과 정밀한 이미지 편집을 단일 프레임워크 내에 통합한 올인원 이미지 생성 파운데이션 모델입니다. 최근 진전이 있었음에도 불구하고, 기존 모델들은 여전히 초장문 텍스트 렌더링, 다국어 타이포그래피, 고해상도의 사진 같은 사실감(photorealism), 견고한 지시 사항 준수, 그리고 효율적인 배포 측면에서 어려움을 겪고 있습니다. 특히 텍스트가 풍부하고 구성이 복잡한 시나리오에서 이러한 한계가 두드러집니다.Qwen-Image-2.0은 조건 인코더로 Qwen3-VL과 다중 모드 디퓨전 트랜스포머(Multimodal Diffusion Transformer)를 결합하여 조건-대상 조건부 모델링을 수행하고, 대규모 데이터 큐레이션과 사용자 정의 다단계 학습 파이프라인으로 이를 지원합니다. 이를 통해 강력한 다중 모드 이해 능력을 유지하면서도 유연한 생성 및 편집 기능을 유지할 수 있습니다. 본 모델은 슬라이드, 포스터, 인포그래픽, 만화 등 텍스트가 풍부한 콘텐츠를 생성하기 위해 최대 1K tokens에 달하는 지시 사항을 지원하며, 다국어 텍스트의 정확도와 타이포그래피 품질을 현저히 향상시킵니다. 또한 더 풍부한 디테일, 사실적인 질감, 일관된 조명으로 사진 같은 사실감 있는 생성 성능을 강화하며, 다양한 스타일에서 복잡한 프롬프트를 더 신뢰성 있게 따릅니다. 광범위한 인간 평가 결과, Qwen-Image-2.0은 기존 Qwen-Image 모델 대비 생성 및 편집 성능 모두에서 압도적인 우위를 보였으며, 이는 더 일반화되고 신뢰할 수으며 실용적인 이미지 생성 파운데이션 모델로의 진전을 시사합니다.
One-sentence Summary
The Qwen team introduces Qwen-Image-2.0, a unified foundation model that couples Qwen3-VL as a condition encoder with a Multimodal Diffusion Transformer to simultaneously perform high-fidelity image generation and precise editing, enabling ultra-long multilingual text rendering up to 1K tokens, high-resolution photorealism, and robust prompt adherence, with extensive human evaluations demonstrating substantial improvements over prior Qwen-Image models in visual quality, editing capability, and practical usability.
Key Contributions
- Qwen-Image-2.0 is introduced as a unified foundation model that integrates high-fidelity image generation and instruction-based editing within a single framework. The architecture couples a Qwen3-VL condition encoder with a Multimodal Diffusion Transformer backbone for joint condition-target modeling, supported by comprehensive data curation and a customized multi-stage training pipeline.
- The model enables direct rendering of ultra-long text instructions up to 1K tokens and substantially improves multilingual typography alongside high-resolution photorealism. This capability produces richer local details, realistic textures, and coherent lighting while significantly reducing concept omission and hallucinated content.
- Extensive human evaluations demonstrate substantial improvements over previous Qwen-Image series models in both generation and editing tasks. Benchmark results on LMArena further validate significant advances in photorealism and portrait generation capabilities.
Introduction
Modern image generation and editing tools are critical for professional creative workflows, yet real-world applications demand seamless handling of complex text, photorealistic detail, and precise instruction following. Prior foundation models typically excel at aesthetic synthesis but struggle with ultra-long text rendering, multilingual typography, and high-resolution fidelity, while also requiring separate pipelines for generation and editing. The authors introduce Qwen-Image-2.0, a unified foundation model that integrates both capabilities into a single framework. By coupling a Qwen3-VL condition encoder with a Multimodal Diffusion Transformer, the model processes prompts up to 1K tokens, delivers robust multilingual typography, and maintains consistent photorealism and stylistic coherence across diverse creative tasks.
Dataset
-
Dataset Composition and Sources
- The authors build a large-scale pipeline for unified text-to-image generation and instruction-based image editing, guided by broad domain coverage, high instruction quality, and reliable source-target consistency.
- The generation subset combines image-text pairs spanning realistic photography, graphic design, artistic content, and synthetic imagery, including portraits, landscapes, objects, long-tail concepts, and layout-sensitive materials like slides and posters.
- The editing subset features instruction-conditioned data split into single-image and multi-image categories, covering attribute modification, background replacement, style transfer, text editing, restoration, reference-based generation, subject consistency, and compositional merging.
-
Key Subset Details and Filtering Rules
- Exact dataset sizes are not disclosed, but the generation data undergoes eight sequential filters: broken file removal, 256 by 256 resolution validation, deduplication, NSFW screening, orientation correction, entropy-based quality checks, CLIP alignment scoring, and token length constraints.
- Editing data is curated and composited to align with the generation pipeline, with single-image tasks focusing on appearance and structure manipulation, while multi-image tasks emphasize reference consistency and cross-image transformations.
- Synthetic data is introduced in later stages to boost diversity at higher resolutions, and all subsets are continuously refined through progressive distribution filtering.
-
Training Usage and Data Mixing
- The authors employ a six-stage multi-resolution training strategy that progressively scales from 256p to 2048p while expanding the dataset composition.
- Stage two merges the filtered generation and editing datasets for unified low-resolution pre-training.
- Stage three introduces synthetic data at 512p resolution to enhance diversity before scaling to mixed 512p and 1024p training in stage four.
- Stage five incorporates 2048p samples with dedicated resolution filtering, and stage six applies stricter distribution filters for supervised fine-tuning to align with high-resolution human preferences.
-
Processing and Metadata Construction
- Resolution scaling drives the pipeline, with stage-specific filters validating spatial requirements, image fidelity, aesthetic quality, and compression artifacts before higher-resolution training.
- Text metadata is constrained by token length limits, and image-text alignment is enforced through CLIP similarity scoring.
- The authors apply rotation correction to properly oriented images and reuse filtering operators across stages with progressively stricter thresholds to maintain data quality throughout iterative development.
Method
The Qwen-Image-2.0 framework is built upon a unified architecture designed for high-fidelity text-to-image (T2I) and text-to-image editing (TI2I) generation, featuring a tightly integrated pipeline that combines multimodal understanding, latent diffusion, and targeted optimization. The overall system, illustrated in the framework diagram, consists of three core components: a Multimodal Large Language Model (MLLM), a Variational Autoencoder (VAE), and a Multi-modal Diffusion Transformer (MMDiT). The MLLM, instantiated as Qwen3-VL, serves as the condition encoder, processing both textual and visual inputs to extract modality-aware representations. For image inputs, the visual representation is replaced by a latent representation extracted by the VAE encoder, which compresses the input image into a lower-dimensional latent space. This multimodal sequence, formed by concatenating the latent representation and the text embedding, is then processed by the MMDiT, which performs the core denoising process in the latent space conditioned on the multimodal representations. 
The MMDiT architecture, as shown in the figure, employs a shared transformer backbone to jointly model textual and visual modalities. Positional information across both text and image tokens is encoded using the MSRoPE (Multi-Scale Rotational Positional Encoding) mechanism, ensuring a unified treatment of spatial and sequential data. For the modulation of the model's output, a purely multiplicative formulation is adopted, where the output representation h′ is calculated as h′=αh, with α being a scalar modulation parameter. To address the issue of large activation magnitudes during joint text-image training, which can lead to premature neuron saturation, the model incorporates a SwiGLU (Switched GLU) activation function in its MLP layers. This non-linear transformation is defined as h=Φ1(x)⊗σ(Φ2(x)), where Φ1(⋅) and Φ2(⋅) are linear projection functions, σ(⋅) is the SiLU activation, and ⊗ denotes element-wise multiplication, enhancing the model's expressivity and training stability. 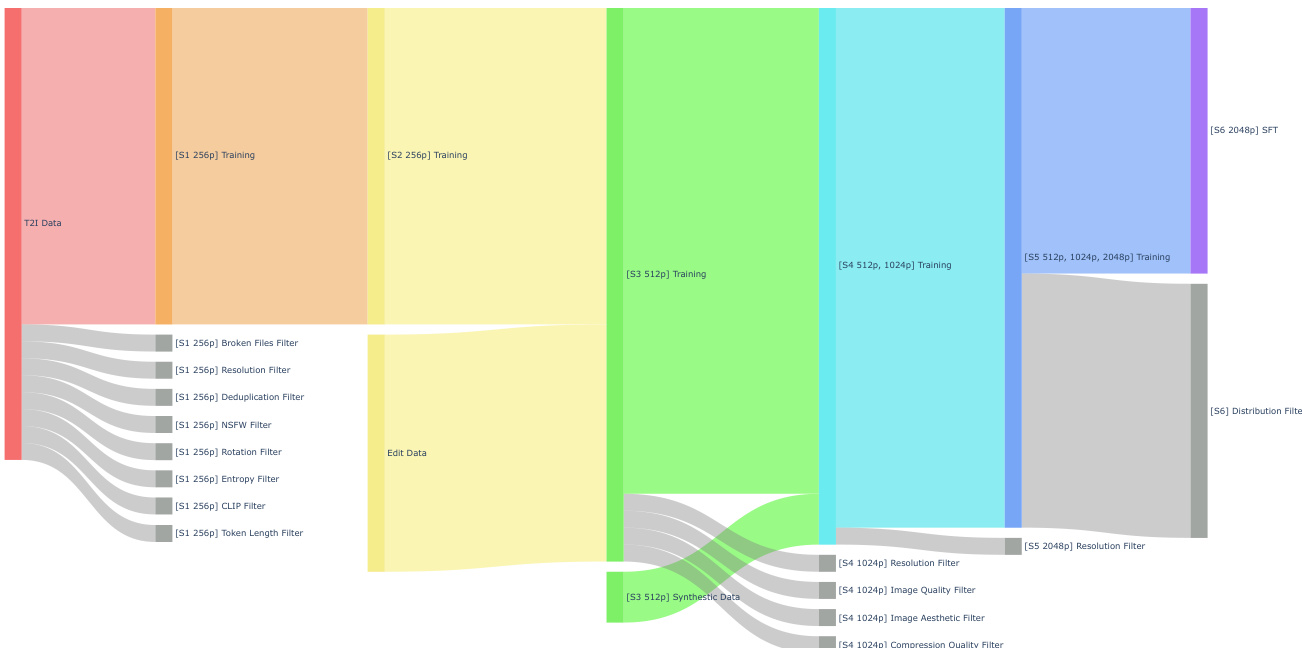
The VAE component is designed for high-compression image synthesis, utilizing a 16× compression ratio to accelerate diffusion training. To mitigate the inherent trade-off between compression, reconstruction fidelity, and diffusability, the model employs a residual autoencoder architecture with non-parametric shortcut connections to preserve fine-grained spatial details. The latent dimensionality is increased to 64 channels, forming an f16c64 configuration that maintains the same total channel bottleneck as the standard f8c16 baseline, enabling high-fidelity reconstruction under a higher compression ratio. To further improve reconstruction quality, particularly for text-dense scenarios, the VAE is trained on a large-scale internal corpus of text-rich images, including real-world documents and synthetic paragraphs in both alphabetic and logographic scripts. To enhance latent-space diffusability, the VAE is optimized with a combination of reconstruction, perceptual, and semantic alignment losses. The semantic alignment loss, inspired by VA-VAE, aligns the learned latent space with semantic representations across diverse domains, and its dynamic application during training—strong in early stages and relaxed later—helps establish a diffusable latent space while balancing reconstruction fidelity. 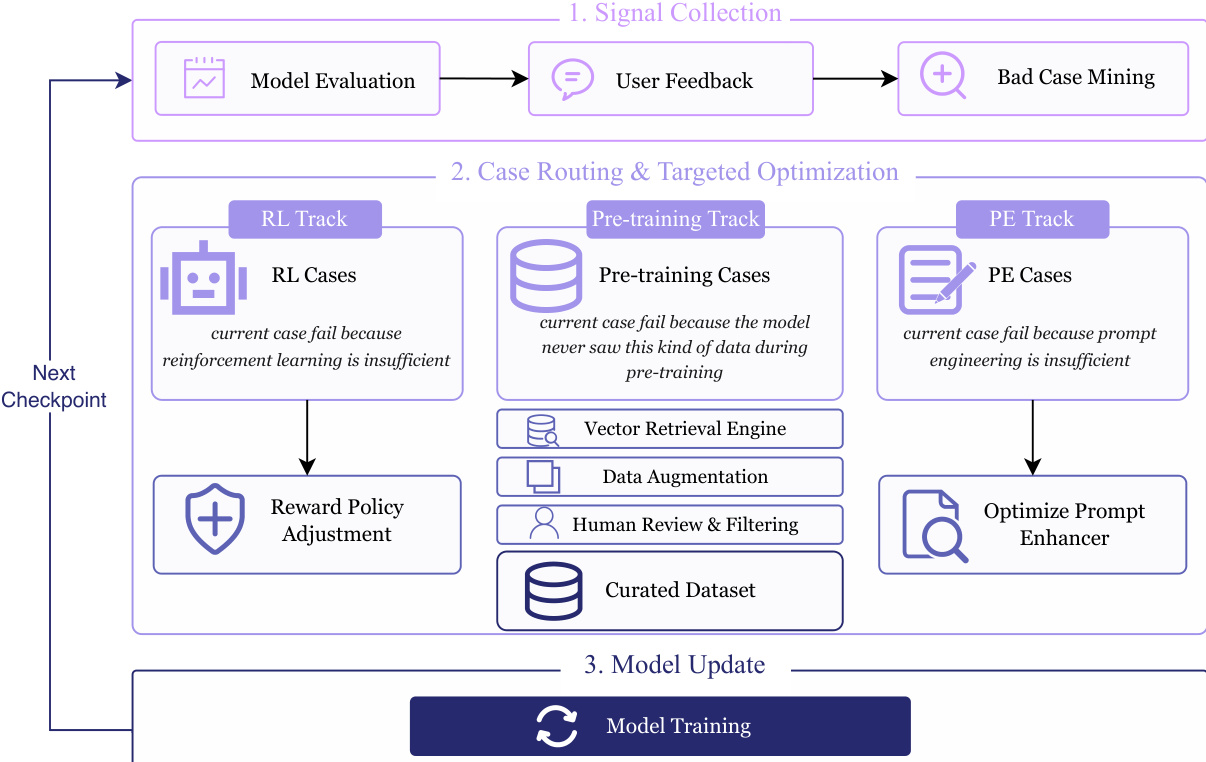
To improve the quality of complex image generation tasks, the model incorporates a Prompt Enhancer (PE) module. This rewriting module converts user queries of varying specificity into structured, detail-rich prompts, enabling the downstream generator to better capture the intended visual design. The PE is trained using a two-stage process: Supervised Fine-Tuning (SFT) followed by Reinforcement Learning (RL). During SFT, the model learns prompt enhancement capabilities from a dataset constructed via a reverse-engineering pipeline that degrades fine-grained annotations into diverse, colloquial prompts, with the inverse reasoning chain serving as training supervision. This ensures the model learns to infer missing visual details. The RL stage further aligns the rewritten prompts with downstream image generation quality using a GRPO-based framework, where the rewards are derived from MLLM-based visual consistency, aesthetic quality, and rule-based textual constraints. This end-to-end training grounds the PE module in both textual supervision and downstream visual feedback, resulting in enhanced prompts that are more faithful and expressive. 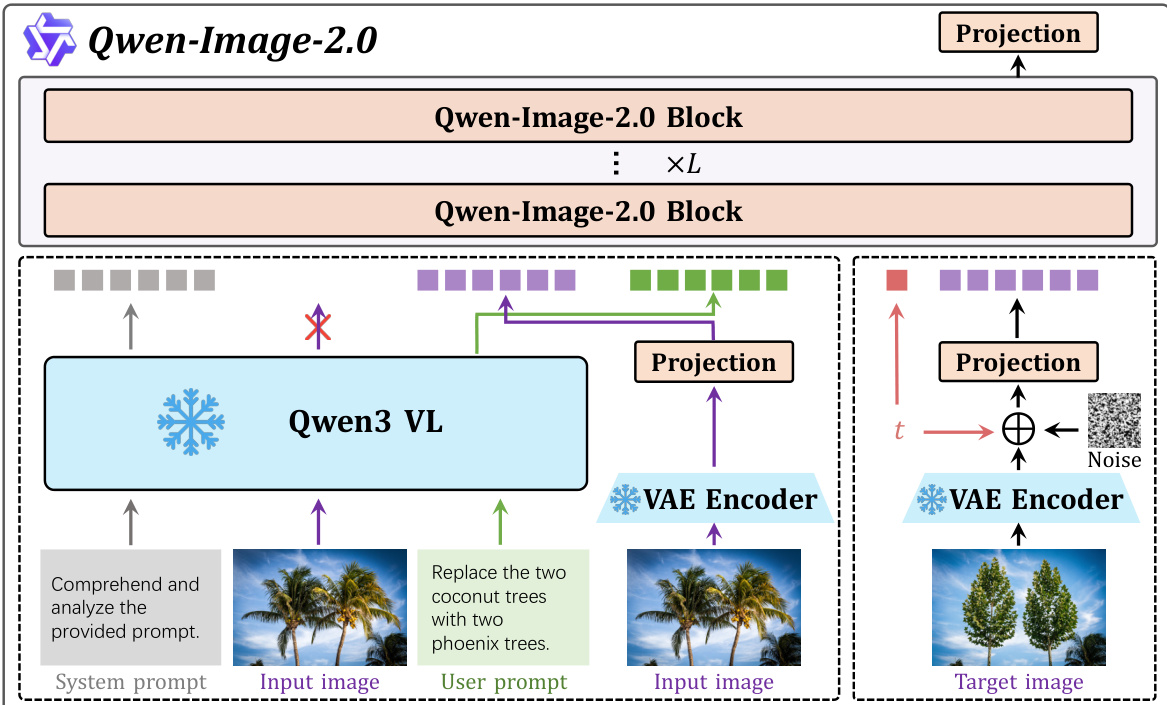
For model refinement, a closed-loop Data Flywheel System is employed to continuously optimize the image generation and editing models. This system, illustrated in the figure, operates in three stages: multi-source signal collection, case routing & targeted optimization, and model update. In the first stage, the system collects feedback signals through standardized model evaluation, targeted bad-case mining, and user feedback. In the second stage, failure cases are automatically routed to three distinct optimization tracks based on error attribution: the RL track for reinforcement learning issues, the pre-training track for missing knowledge, and the prompt engineering track for prompt formulation problems. The pre-training track uses a vector retrieval engine to diagnose data scarcity and retrieve diverse text prompts and instruction-image pairs for data augmentation. The prompt engineering track refines the input through an optimized prompt enhancer. In the final stage, the aggregated strategies and updated datasets are used to initiate the next training round, creating a self-reinforcing optimization loop.
Experiment
Evaluated through blind user preference rankings on LMArena and extensive qualitative comparisons against leading baselines, the experiments validate the model’s capabilities across text-to-image generation and instruction-based editing tasks. Qualitative assessments demonstrate that the architecture consistently outperforms existing systems by delivering accurate, spatially coherent text rendering, preserving fine-grained photorealistic details at high resolutions, and executing complex multi-element edits while strictly maintaining subject identity and scene consistency. These findings collectively confirm that the unified framework successfully bridges advanced multimodal understanding with professional-grade visual synthesis, effectively resolving prior bottlenecks in typography, multilingual support, and compositional logic.
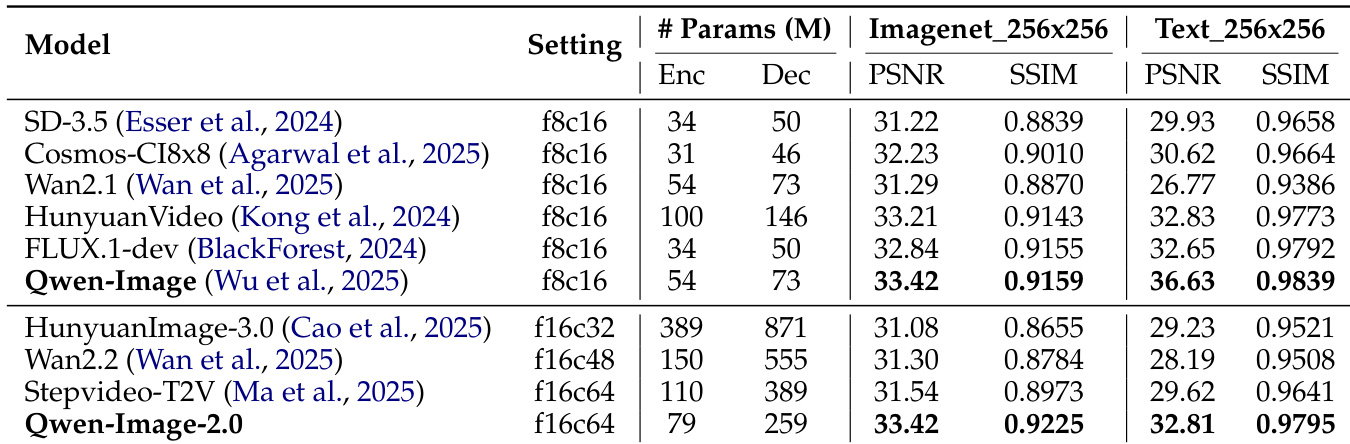
The the the table compares the performance of Qwen-Image-2.0 against several other models on two distinct tasks, Imagenet_256x256 and Text_256x256, using PSNR and SSIM metrics. Qwen-Image-2.0 achieves competitive results on both tasks, showing strong performance in image quality and text rendering, particularly on the text-focused evaluation. The model demonstrates a balance between encoder and decoder parameters, contributing to its effective performance. Qwen-Image-2.0 achieves high PSNR and SSIM scores on both image and text tasks, indicating strong performance in both areas. The model shows competitive results compared to other state-of-the-art models, especially on the text rendering task. Qwen-Image-2.0 maintains a balanced parameter distribution between encoder and decoder, which contributes to its overall performance.
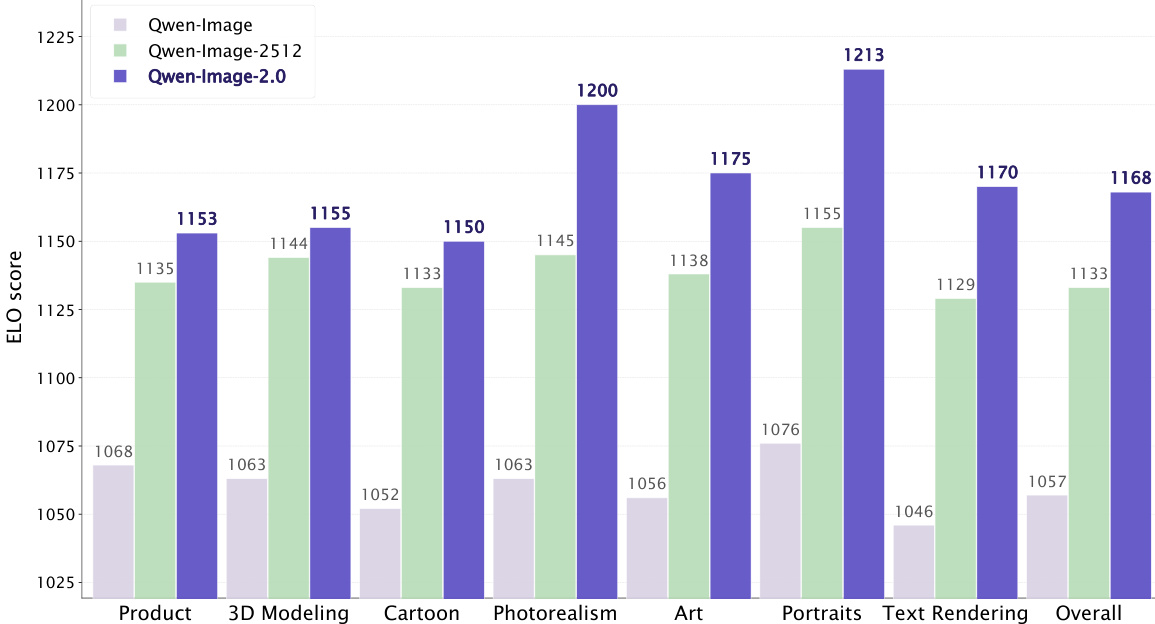
The authors evaluate Qwen-Image-2.0 against prior versions and other models on a benchmark measuring user preference, showing consistent performance improvements across multiple categories. The results demonstrate that Qwen-Image-2.0 achieves higher scores than its predecessors in all evaluated areas, with the most significant gains observed in text rendering and photorealism. Qwen-Image-2.0 outperforms previous versions of the model across all evaluated categories. The model shows the most significant improvement in text rendering and photorealism compared to other categories. Qwen-Image-2.0 achieves the highest overall score, indicating superior performance in user preference ranking.
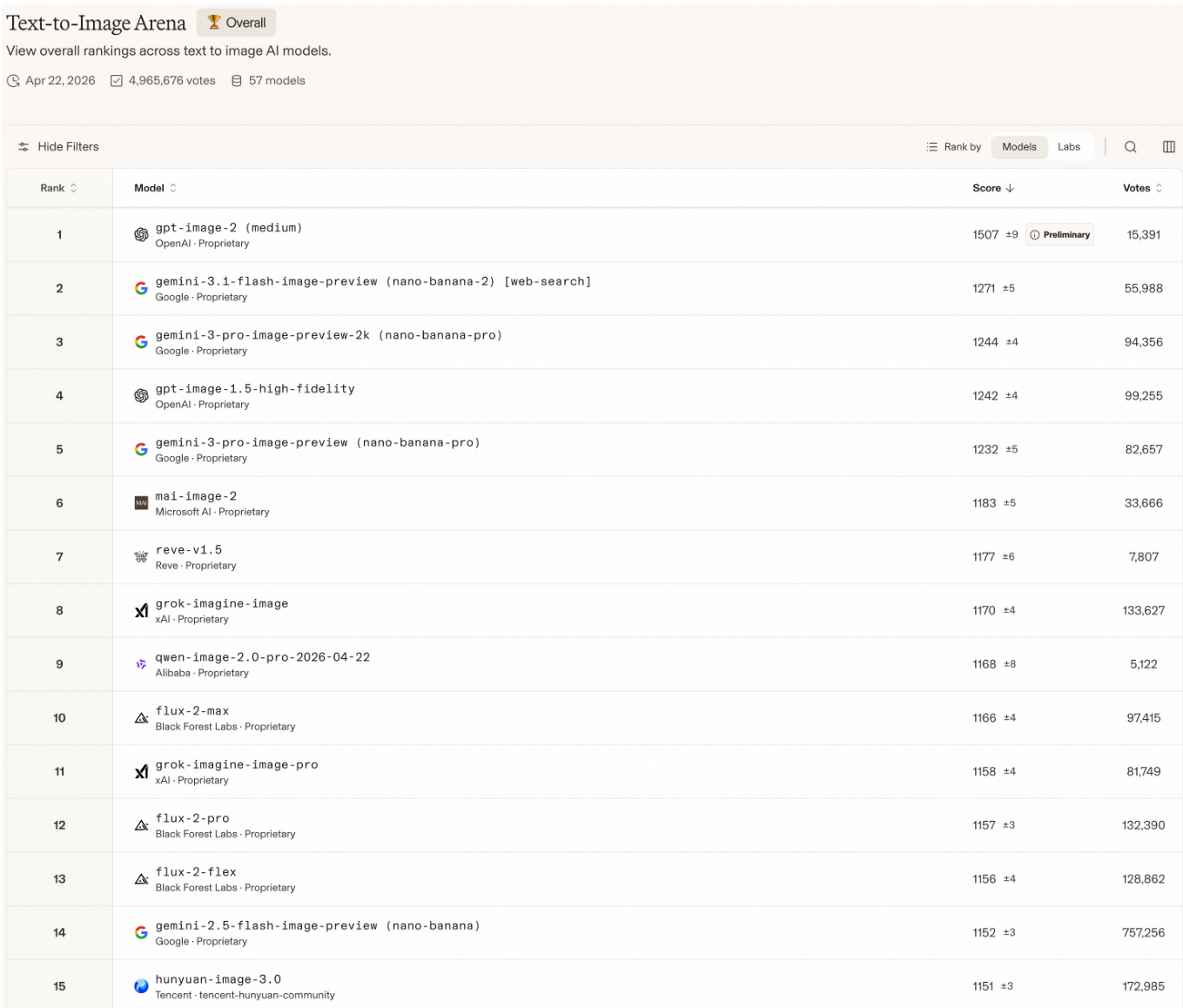
The authors evaluate Qwen-Image-2.0 on a benchmark that ranks text-to-image models based on user preferences, demonstrating its competitive performance against leading proprietary models. The model achieves a high rank, indicating strong user preference and overall quality in image generation tasks. Qwen-Image-2.0 ranks highly among leading text-to-image models on a user preference benchmark. The model achieves a top-tier position, outperforming several prominent proprietary models in the evaluation. Results indicate strong user preference for Qwen-Image-2.0 compared to other models in the leaderboard.
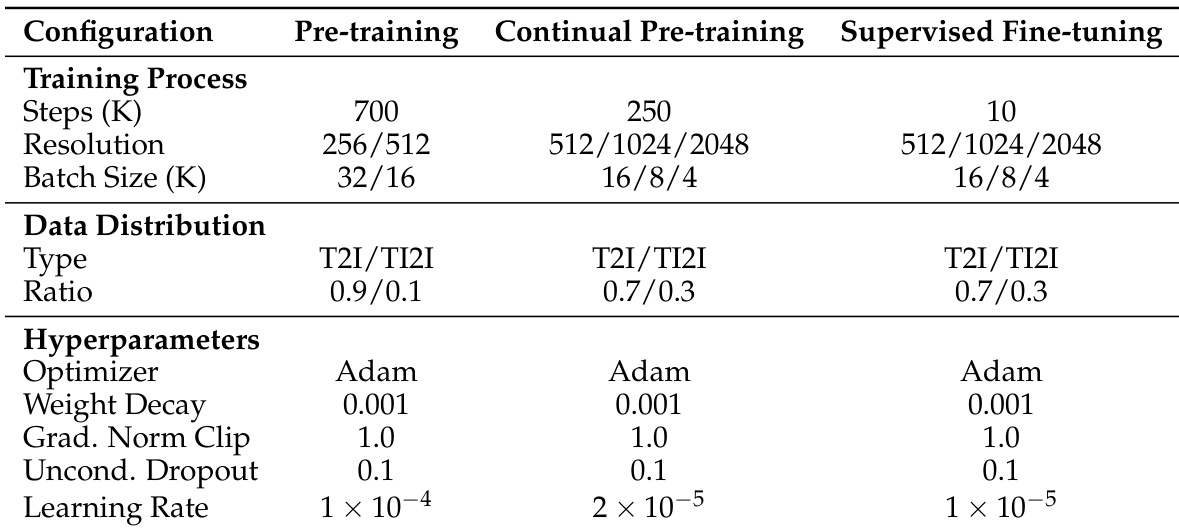
The experiment section describes a multistage training approach for an image generation model, involving pre-training, continual pre-training, and supervised fine-tuning. Each stage progressively adjusts resolution, data composition, and optimization parameters, with the model training at increasingly higher resolutions and using a consistent optimizer while reducing the learning rate. The training process advances through three stages with increasing resolution and decreasing learning rate. Data distribution shifts from a 9:1 to 7:3 ratio of T2I to TI2I data across training stages. A consistent optimizer and weight decay are used throughout all training stages, with learning rate decreasing progressively.
The experiments evaluate Qwen-Image-2.0 through image and text quality benchmarks, user preference rankings against prior iterations and proprietary competitors, and a structured multistage training protocol. These evaluations validate the model's generative capabilities, comparative performance against leading proprietary systems, and the effectiveness of its progressive training methodology. The qualitative results highlight consistent improvements in photorealism and text rendering, confirming that the structured training approach successfully balances resolution scaling and data composition to achieve top-tier user preference and overall competitive standing.