Command Palette
Search for a command to run...
MulTaBench: 텍스트와 이미지를 활용한 다중 모달 표형 학습 벤치마킹
MulTaBench: 텍스트와 이미지를 활용한 다중 모달 표형 학습 벤치마킹
초록
표 기반 파운데이션 모델은 수치형 및 범주형 구조화된 데이터의 일반화 가능한 표현을 학습하기 위해 사전 학습을 활용함으로써 최근 지도형 표 학습 분야에서 최첨단 성능을 달성했습니다. 그러나 이러한 모델은 텍스트 및 이미지와 같은 비정형 모달리티에 대한 네이티브 지원을 결여하고 있으며, 이를 처리하기 위해 고정된 사전 학습 임베딩에 의존합니다. 기존 다중 모달 표 학습 벤치마크에서, 임베딩을 작업에 맞게 튜닝하면 성능이 향상됨을 보여줍니다. 그러나 기존 벤치마크는 종종 모달리티의 단순 공존에 초점을 맞추기 때문에, 데이터셋 간 높은 분산을 초래하고 작업 특화 튜닝의 이점을 가립니다. 이러한 격차를 해소하기 위해, 우리는 이미지-표 및 텍스트-표 작업을 균등하게 분할한 40개의 데이터셋으로 구성된 벤치마크인 MulTaBench를 소개합니다. 우리는 모달리티가 상호 보완적인 예측 신호를 제공하고, 일반적 임베딩이 중요한 정보를 손실하여 작업과 정렬된 목표 인식 표현(Target-Aware Representations)이 필요한 예측 작업에 초점을 맞춥니다. 우리의 실험 결과는 목표 인식 표현 튜닝으로 인한 이득이 텍스트 및 이미지 모달리티, 여러 표 학습기, 인코더 규모 및 임베딩 차원 전반에 걸쳐 일반화됨을 보여줍니다. MulTaBench는 의료 및 전자상거래와 같은 고영향 도메인을 아우르는 지금까지의 가장 대규모 이미지-표 벤치마킹 노력입니다. 이는 결합 모델링과 목표 인식 표현을 통합하는 새로운 아키텍처에 대한 연구를 가능하게 하여, 새로운 다중 모달 표 파운데이션 모델 개발의 길을 열도록 설계되었습니다.
One-sentence Summary
MulTaBench is a benchmark of forty datasets split equally between image-tabular and text-tabular tasks that demonstrates how target-aware representation tuning outperforms frozen pretrained embeddings by aligning embeddings with complementary predictive signals, with performance gains generalizing across multiple tabular learners, encoder scales, and embedding dimensions while spanning healthcare and e-commerce domains.
Key Contributions
- MulTaBench, a benchmark comprising 40 datasets equally divided between image-tabular and text-tabular tasks. This benchmark addresses the high variance of prior evaluations by focusing on predictive tasks where modalities provide complementary signals, enabling rigorous assessment of target-aware tuning.
- Target-Aware Representations, a tuning approach that adapts frozen pretrained embeddings to downstream objectives instead of relying on static features. This process dynamically shifts model attention to task-relevant regions, recovering critical predictive information discarded by generic embeddings.
- Experimental results demonstrate that target-aware tuning consistently improves performance across various tabular learners, encoder scales, and embedding dimensions. These findings confirm that the adaptation strategy generalizes effectively across text and image modalities in high-impact domains such as healthcare and e-commerce.
Introduction
Modern tabular foundation models have established new performance standards for structured data but remain fundamentally unimodal, relying on frozen embeddings to process unstructured inputs like text and images. This static approach creates a significant bottleneck in high-stakes domains such as healthcare and e-commerce, where generic representations often discard the fine-grained, task-specific signals required for accurate prediction. Existing benchmarks further complicate progress by prioritizing dataset diversity over predictive necessity, which obscures the true value of joint modeling and target-aware tuning. To address these gaps, the authors introduce MulTaBench, a curated benchmark of 40 datasets that strictly filters for tasks where modalities provide complementary information and require target-aware representation tuning. Their experimental validation demonstrates that adapting embeddings to specific prediction objectives consistently outperforms frozen baselines across diverse architectures, establishing a rigorous standard for developing the next generation of multimodal tabular foundation models.
Dataset
- Dataset Composition and Sources: The authors introduce MulTaBench, a benchmark comprising 40 multimodal tabular datasets divided equally between image-tabular and text-tabular pairs. The text-tabular subset aggregates 56 unique datasets from four established public benchmarks following deduplication. The image-tabular subset merges 16 candidates sourced from academic literature with manually curated additions collected from Kaggle and public repositories.
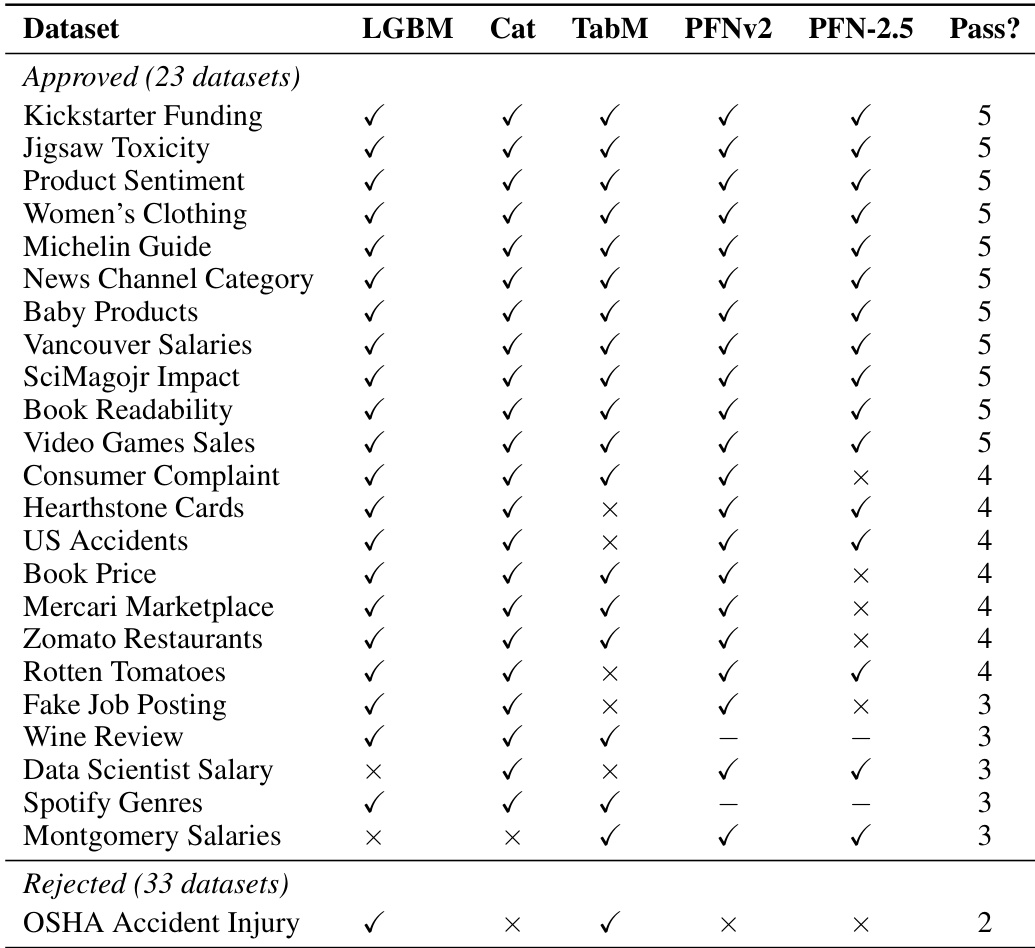
- Subset Details and Filtering Rules: Datasets span 400 to 114,000 rows and contain 1 to 245 structured features, maintaining a balanced mix of classification and regression objectives. The authors enforce a two-part curation pipeline requiring Joint Signal, meaning each modality must contribute independent predictive value, and Task-awareness, meaning fine-grained target cues must require representation tuning rather than generic encoders. Approximately 41 percent of text-tabular candidates satisfy both criteria, and the authors subsample 20 to equal the image subset size. Only 5 of 16 image-tabular literature candidates pass the filters, leading the authors to manually curate additional Kaggle datasets to complete the final 20.
- Data Usage and Processing: The authors distribute the benchmark through Kaggle, utilizing a unified loading API that standardizes data ingestion across all sources. They employ the data to benchmark Target-Aware Representations against frozen embeddings, normalizing AUC and R² metrics to a zero to one scale for cross-task evaluation and reporting ninety-five percent confidence intervals. Rows containing missing or corrupt images are dropped without imputation, and datasets offering multiple image columns per entry are simplified to a single image.
- Cropping Strategy and Metadata Construction: Several datasets rely on targeted cropping, including mammography mass regions and lesion crops, to direct visual encoders toward diagnostically relevant zones. The authors apply log transformations to price-based regression targets and use quantile binning to discretize continuous values into multiclass labels. Structured columns that leak the target variable or dominate visual signals are removed to maintain genuine multimodal learning conditions. Text features are either retained as raw strings or pre-embedded into continuous vectors, while a flat image directory structure paired with relative paths ensures consistent metadata alignment during training.
Method
The authors leverage a multi-stage framework for integrating structured and unstructured features in tabular learning tasks, with a focus on ensuring robust and target-aware representations. The overall architecture begins with a preprocessing step that adapts a pre-trained encoder to generate target-aware representations (TAR). This adaptation is performed by fine-tuning the top three layers of the encoder using Low-Rank Adaptation (LoRA), with a single linear head mapping the encoder output (384-dimensional) to the number of output classes. The fine-tuning is conducted exclusively on the training split, using a stratified 90/10 train/validation split to select the best checkpoint, ensuring no data leakage from the test set. For both DINO-v3-small and e5-small-v2, the LoRA configuration is fixed: r=16, α=32, and dropout of 0.1. Training employs AdamW with a learning rate of 10−4 for e5 and 0.001 for DINO, a batch size of 256, and weight decay of 0.01. Training for DINO proceeds up to 100 epochs, while e5 is limited to 50 epochs due to the prevalence of multiple text features across datasets. Early stopping is applied after three epochs of no improvement on validation loss, with all hyperparameters held constant across datasets to avoid per-dataset tuning.
For regression tasks, the continuous label is discretized into 20 equal-frequency bins, and the adaptation objective is cross-entropy over these bins. This approach enhances stability compared to direct regression fine-tuning by reducing sensitivity to outliers. In text-tabular datasets, which often contain multiple text fields, the authors define string features with at least 100 distinct values as text columns. To maintain efficiency, a single e5 model is fine-tuned jointly across all such text columns. Each row-column pair is treated as a training example in the format "col_name : col_val", paired with the row's target label, enabling the model to learn a shared representation across all text features simultaneously. While this approach may affect representation quality as feature size increases, fine-tuning a dedicated embedding model for each feature would be computationally prohibitive.
Experiment
The evaluation employs a four-condition protocol to curate datasets by isolating unimodal and joint representations, validating that selected benchmarks exhibit strong multimodal signal and task-awareness. Robustness analyses then confirm these properties generalize across diverse tabular learners, larger embedding scales, and varying dimensionality reductions, demonstrating that target-aware representations consistently improve upon frozen baselines. Qualitative attention maps further reveal that this tuning mechanism effectively redirects model focus toward semantically relevant features. Collectively, the experiments establish that representation adaptation serves as a reliable and necessary preprocessing step for multimodal tabular learning, independent of specific architecture or embedding capacity.
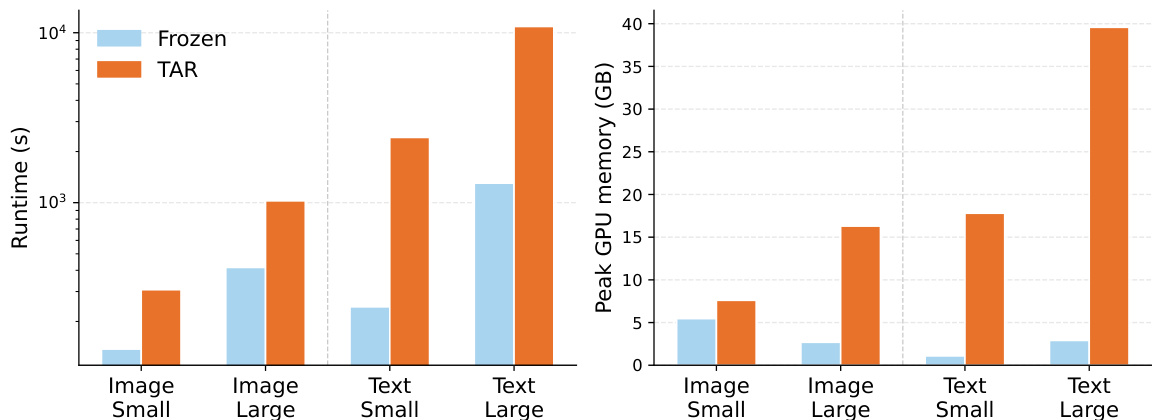
The authors analyze the computational costs of target-aware representation tuning (TAR) compared to frozen embeddings across different modalities and encoder sizes. Results show that TAR significantly increases runtime and GPU memory usage, with text-based tasks and larger encoders leading to substantially higher computational demands. The increase in costs is primarily attributed to the fine-tuning step of the encoders. Target-aware representation tuning increases runtime and GPU memory usage compared to frozen embeddings. Text-based tasks require significantly more computational resources than image-based tasks for both frozen and TAR conditions. Larger encoder models lead to substantially higher computational costs for both runtime and peak GPU memory, especially under the TAR condition.
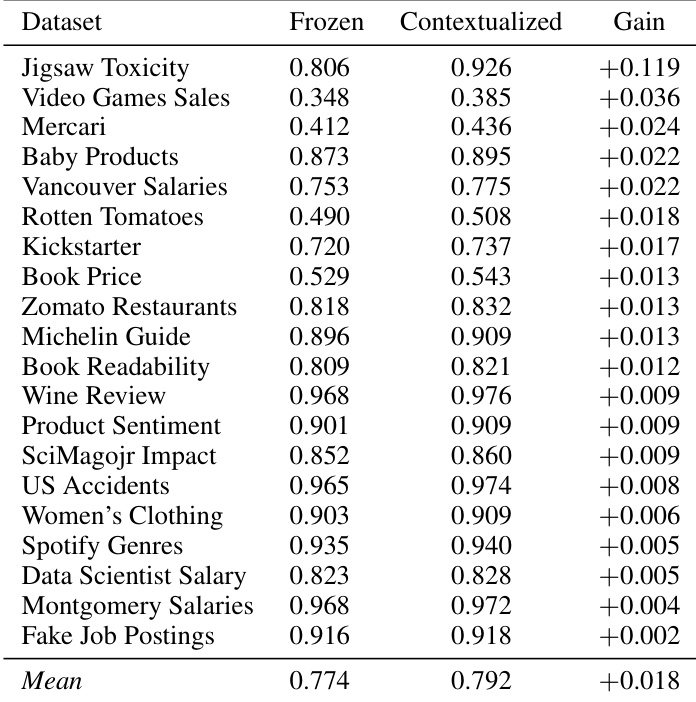
The authors evaluate the performance of tabular models with frozen versus target-aware contextualized representations across multiple datasets. Results show that contextualized representations consistently improve performance over frozen representations, with gains observed across different models and datasets. The average improvement across all datasets is small but positive, indicating a general benefit from target-aware tuning. Contextualized representations consistently outperform frozen representations across all datasets. The improvement from target-aware tuning is observed across various models and datasets. The average gain from contextualization is small but positive, indicating a general benefit.
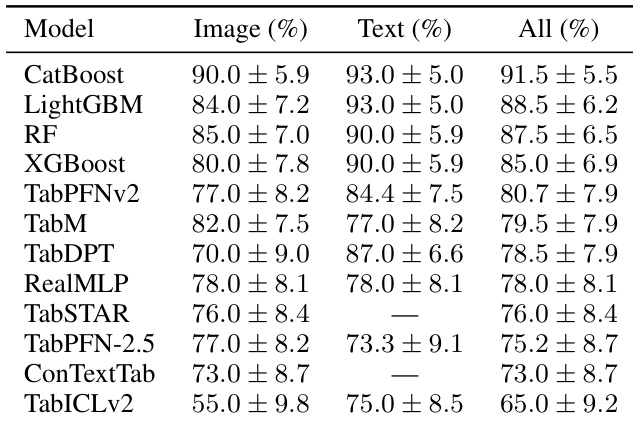
The authors evaluate multiple tabular models across image and text modalities to assess the effectiveness of target-aware representation tuning. Results show that models consistently achieve higher performance when using target-aware representations compared to frozen representations, with gains observed across different model types and modalities. The performance improvement is robust and not dependent on specific model architectures or embedding dimensions. Target-aware representations consistently outperform frozen representations across all evaluated models and modalities. The performance gains from target-aware tuning are observed across different model architectures, including both traditional and neural network-based learners. The benefits of target-aware tuning are robust to variations in embedding dimensions and model scales, indicating generalizability.
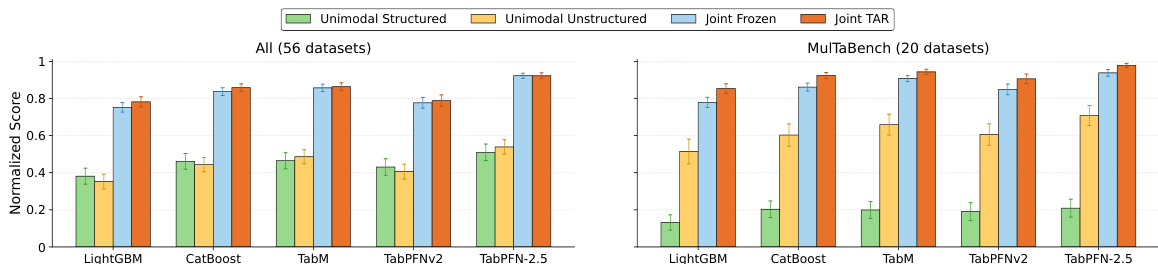
The authors evaluate a benchmark across multiple tabular learners and experimental conditions, comparing performance between unimodal and joint modeling approaches with and without target-aware representation tuning. Results show that joint modeling with target-aware representations consistently outperforms other configurations, particularly in the curated subset of datasets, and this improvement is robust across different model types and modalities. Joint modeling with target-aware representations consistently outperforms other configurations across all evaluated models and datasets. The curated subset of datasets shows a stronger and more consistent performance ordering compared to the full pool of candidates. Target-aware representations lead to significant improvements over frozen embeddings, with gains observed across both text and image modalities and multiple model types.
The authors evaluate a set of datasets using multiple tabular learners under different experimental conditions to assess their suitability for multimodal tasks. The evaluation focuses on two criteria: Joint Signal and Task-awareness, with datasets passing if they meet both criteria across at least three out of five models. The results show that a subset of datasets consistently satisfies these criteria, while others fail due to insufficient multimodal interaction or lack of benefit from target-aware representation tuning. The analysis confirms that the proposed curation method effectively identifies datasets where unstructured modalities contribute meaningfully to tabular prediction. The curation process identifies a subset of datasets that satisfy both Joint Signal and Task-awareness criteria, indicating meaningful multimodal interaction and benefit from target-aware representation tuning. Most datasets that pass the curation criteria are consistently validated across multiple tabular learners, while rejected datasets fail on at least one criterion. The evaluation reveals that models with native multimodal support may not always outperform models using target-aware representation tuning, highlighting the importance of the curation framework.
The experiments evaluate target-aware representation tuning against frozen embeddings across various tabular learners, modalities, and modeling configurations to assess computational efficiency, predictive performance, and dataset suitability. Qualitative results indicate that while target-aware tuning significantly increases computational overhead, particularly for text-based tasks and larger models, it consistently yields robust performance improvements across diverse architectures and modalities. Joint modeling approaches leveraging these contextualized representations demonstrate superior predictive capabilities, especially when applied to curated datasets that exhibit strong multimodal interaction. Overall, the findings underscore that combining careful dataset curation with target-aware tuning effectively harnesses unstructured data for tabular prediction, often surpassing the benefits of models with native multimodal architectures.