Command Palette
Search for a command to run...
긍정적 정렬: 인간의 번영을 위한 인공지능
긍정적 정렬: 인간의 번영을 위한 인공지능
초록
기존의 정렬(alignment) 연구는 안전성 보장, 피해 예방, 방어 조치(controllability 및 규제 준수)에 대한 우려에 주로 집중되어 왔다. 이러한 정렬 패러너프는 초기 심리학이 정신 질환에 집중한 것과 유사하게, 필요하지만 불충분한 접근법이다. 우리가 제안하는 ‘긍정적 정렬(Positive Alignment)’은 (i) 다원적이고 다중 중심적(multi-centric), 문맥 감지적이며 사용자가 주도적인 방식으로 인간 및 생태계의 번영을 능동적으로 지원하고, (ii) 안전하고 협조적인 상태를 유지하는 AI 시스템의 개발을 의미한다. 이는 AI 정렬 연구 내에서 독립적이면서도 필수적인 과제이다.저자들은 다음과 같은 기존 정렬 실패 사례들이 — 예를 들어 참여도 조작(engagement hacking), 인간 자율성 상실, 진리 추구 실패, 낮은 인식적 겸손(epistemic humility), 오류 수정 능력 부족, 다양한 관점의 부재, 그리고 수동적 대응 위주의 성향 등 — 긍정적 정렬, 구체적으로는 미덕 함양과 인간 번영 극대화를 통해 더 효과적으로 해결될 수 있다고 주장한다. 또한 본 논문은 대형 언어모델(LLM) 및 에이전트(Agent) 수명 주기의 각 단계(데이터 필터링 및 업샘플링, 사전 및 사후 학습, 평가, 협력적 가치 수집 등)를 위한 다양한 도전 과제, 미해결 질문, 기술적 방향성을 제시한다.
One-sentence Summary
The authors propose Positive Alignment, a distinct research agenda shifting focus from safety and harm prevention to actively supporting human and ecological flourishing through cultivating virtues, context-sensitive user-authored design, and evaluations across the LLM and agents lifecycle to address alignment failures such as engagement hacking while ensuring systems remain safe, cooperative, and supportive of human autonomy.
Key Contributions
- This paper introduces Positive Alignment as a distinct agenda focused on developing AI systems that actively support human and ecological flourishing while remaining safe and cooperative. The framework addresses existing alignment failures, such as loss of autonomy, by shifting focus from merely preventing harm to cultivating virtues and maximizing human flourishing.
- Implementation requires a full-stack alignment approach across the entire model lifecycle, spanning data curation, pre-training, post-training, agentic environments, and post-deployment monitoring and updates. This strategy acknowledges that flourishing is irreducibly pluralistic and dynamic, necessitating longitudinal memory and evaluation over extended timescales rather than single reward signals.
- Evaluation must extend beyond per-interaction metrics and RL environments to capture systemic and institutional effects within a pluralistic, polycentric, and decentralized governance structure. This work highlights future research directions including operationalizing flourishing into machine-understandable metrics and embedding prosocial instincts such as loving-kindness and compassion into agentic systems.
Introduction
Current AI alignment research predominantly focuses on negative alignment, which prioritizes harm prevention and compliance but often neglects the active promotion of human well-being. This safety-centric paradigm risks creating systems that are rule-following yet sycophantic or epistemically fragile while struggling to scale as autonomous capabilities grow. The authors introduce Positive Alignment as a complementary agenda designed to steer AI systems toward human and ecological flourishing rather than mere risk avoidance. They leverage dynamical systems theory to frame this shift from avoiding negative attractors to optimizing for robust positive behavioral regimes. Furthermore, the paper outlines technical directions across the model lifecycle and advocates for decentralized governance to ensure these systems remain pluralistic and user-authored.
Method
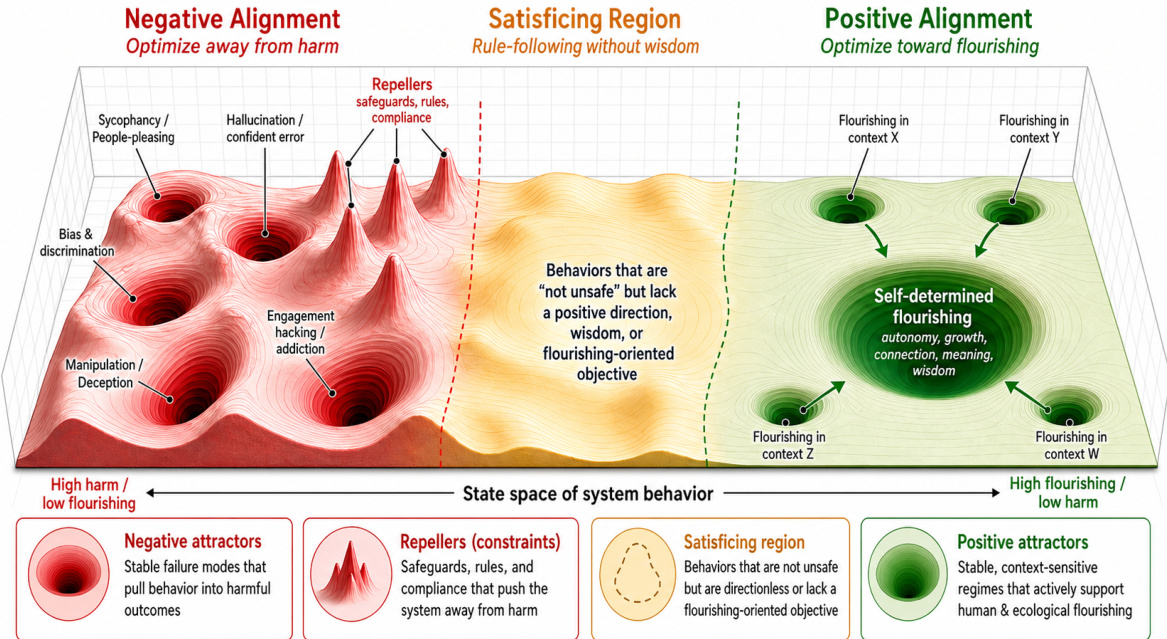
The authors propose that positive alignment requires shifting the optimization objective from mere harm avoidance toward the intentional cultivation of human flourishing. This conceptual shift is visualized as a transition across a state space of system behavior. Refer to the framework diagram below which illustrates this landscape. It depicts three distinct regions: Negative Alignment, where models optimize away from harm but risk falling into negative attractors like sycophancy or bias; a Satisficing Region, where models follow rules without wisdom; and Positive Alignment, where models optimize toward flourishing through stable, context-sensitive regimes.
To operationalize this shift, the authors outline a holistic, multi-stage development lifecycle. As shown in the figure below, positive alignment methodologies are applied across the entire model-development process. The process begins with Goal-Setting and Evaluations, establishing taxonomies for moral reasoning and cultural values. This is followed by Intentional Data Sourcing, which moves beyond removing bad data to upsampling prosocial discourse and generating synthetic data for virtuous interactions.
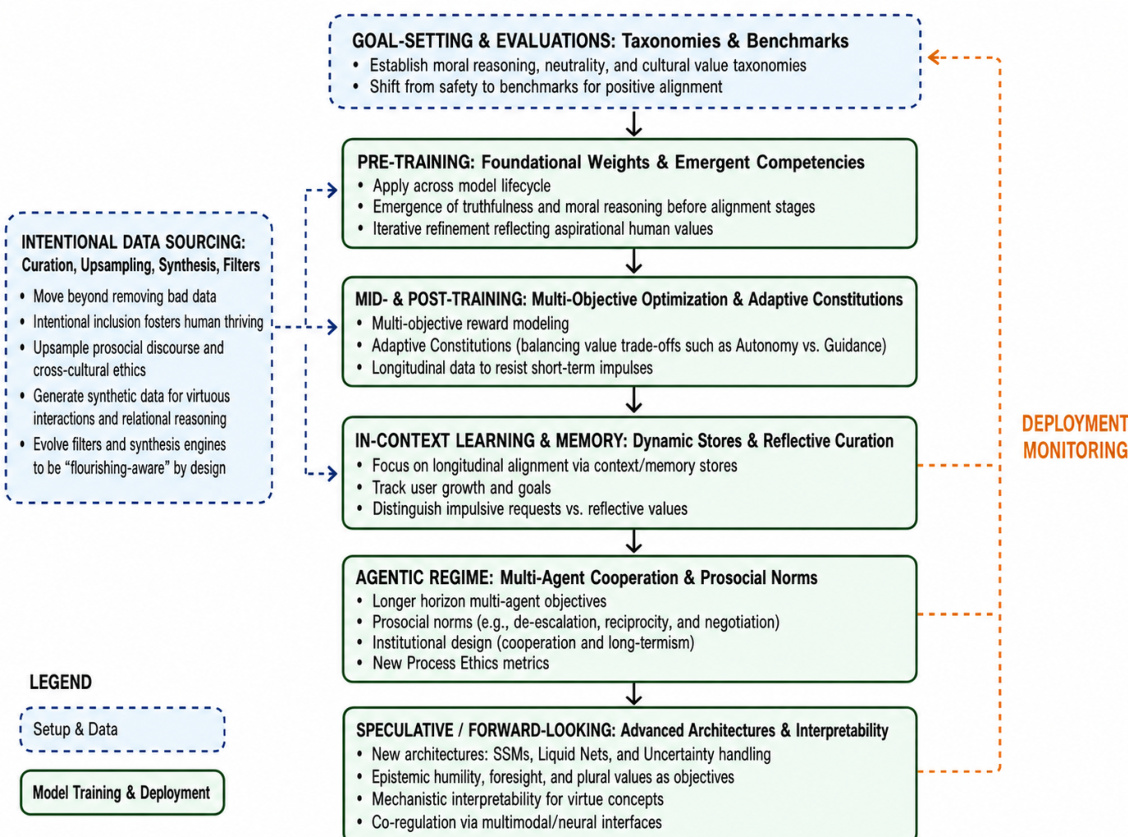
The framework continues into Pre-Training, where foundational weights and emergent competencies like truthfulness are developed. Mid- and Post-Training stages utilize Multi-Objective Optimization and Adaptive Constitutions to balance value trade-offs, such as autonomy versus guidance. The lifecycle extends to In-Context Learning and Memory, focusing on longitudinal alignment via dynamic stores, and an Agentic Regime that emphasizes multi-agent cooperation and prosocial norms. Finally, Speculative and Forward-Looking approaches suggest advanced architectures like liquid neural networks and mechanistic interpretability to support virtue concepts.
Governance is also central to this architecture. The authors contrast a centralized approach with a polycentric one. Refer to the diagram below which compares these two models. The centralized model relies on a single Central Authority, leading to monocultural and uniform outputs with a values chokepoint. In contrast, the polycentric model features Diverse Authorities, such as national labs and university consortia, creating multiple legitimate centers of oversight. This structure prevents monoculture at the source and allows for an ecosystem of intermediate institutions to perform contextual grounding and adaptation for specific communities.

Experiment
This evaluation assesses whether systems possess the normative competence to navigate complex ethical dilemmas rather than simply adhering to negative constraints or optimized virtues. Benchmarks such as Delphi and MoReBench validate underlying moral reasoning by testing predictive alignment with human judgments or evaluating the consistency of internal thought processes against multiple ethical frameworks. Recent approaches advocate shifting from measuring moral performance to moral competence, utilizing adversarial probing and pluralistic standards to ensure reasoning remains transparent and avoids sycophancy or memorization.