Command Palette
Search for a command to run...
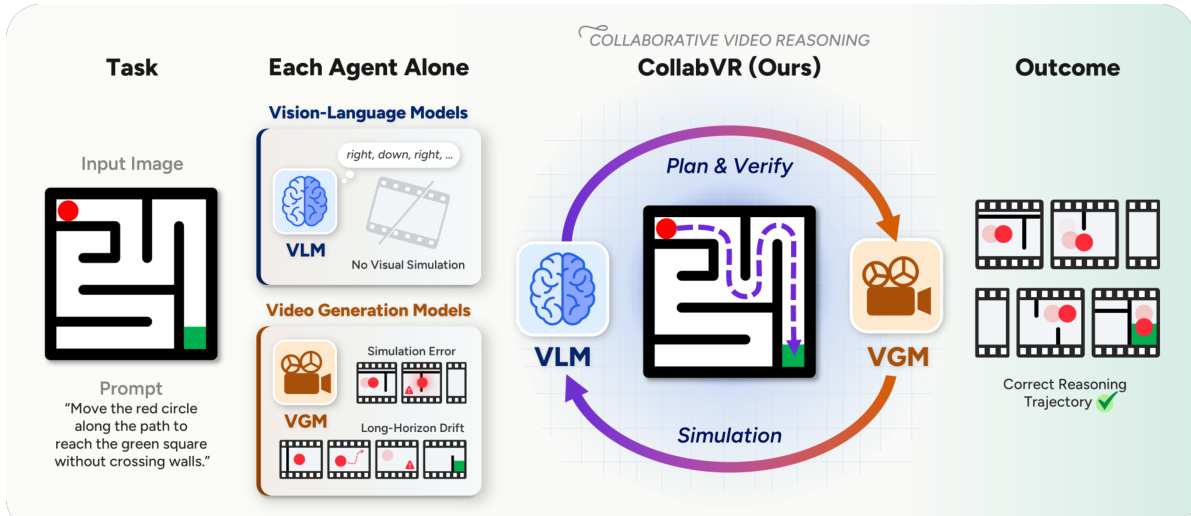
CollabVR: Vision-Language 및 Video Generation Models을 활용한 협력적 비디오 추론
CollabVR: Vision-Language 및 Video Generation Models을 활용한 협력적 비디오 추론
Joowon Kim Seungho Shin Joonhyung Park Eunho Yang
초록
최근 '비디오를 활용한 사고(Thinking with Video)' 접근법들은 시각적 추론을 위해 시간적으로 일관된 프레임 체인(Chain-of-Frames)을 추론 산출물로서 생성하는 비디오 생성 모델(VGM, Video Generation Models)을 활용하고 있습니다. 그러나 강력한 VGM들조차도 목표 지향적 과제에서 두 가지 반복적인 실패 모드를 보입니다: 다단계 과제에서 장기적 drift(편차)와 누적되는 중간 영상 클립 시뮬레이션 오류입니다. 이 둘 모두 VGM의 단기적 시각prior(prior)를 기반으로 한 명시적 추론의 부재에서 기인하며, 이는 일반적으로 비전-언어 모델(VLM, Vision-Language Models)이 수행하는 역할입니다. 하지만 VLM을 어디에 배치할지는 쉽지 않은 문제입니다: 초기 계획은 첫 번째 프레임이 생성되기 전에 고정되어 있고, 비디오 전체에 대한 사후 비판(post-hoc critiques)은 지나치게 늦게 개입하기 때문입니다.저희는 VLM과 VGM을 단계별(step-level) 세분성으로 결합하는 폐쇄 루프(closed-loop) 프레임워크인 VLM-VGM 협력 비디오 추론(CollabVR, Collaborative Video Reasoning)을 제안합니다. CollabVR에서 VLM은 즉시 다음 행동을 계획하고, VGM이 생성한 클립을 검사하며, 검증기의 진단을 다음 행동 프롬프트에 직접 반영하여 감지된 오류를 수리합니다. Gen-ViRe 및 VBVR-Bench 벤치마크에서 CollabVR은 동일한 연산량(matched compute) 하에서 단일 추론(single-inference), Pass@k, 그리고 기존 테스트 타임 확장(test-time scaling) 베이스라인 대비 오픈소스와 클로즈드소스 VGM 모두에서 성능을 향상시키며, 가장 어려운 과제에서 가장 큰 개선을 보였습니다. 또한 이 방법은 추론용 미세 조정(reasoning-fine-tuned) VGM之上에서도 추가적인 성능 향상을 이루어냈는데, 이는 단계별 VLM 감독이 추론 목적의 미세 조정과 직교(orthogonal)하며 중첩 가능하다는 것을 나타냅니다. 프로젝트 페이지(https://joow0n-kim.github.io/collabvr-project-page)에서 비디오 샘플 및 추가 정성적 결과를 확인할 수 있습니다.
One-sentence Summary
CollabVR couples vision-language and video generation models at step-level granularity within a closed-loop framework that plans immediate actions, inspects generated clips, and integrates diagnostic feedback to repair failures, thereby outperforming single-inference, Pass@k, and test-time scaling baselines on the Gen-ViRe and VBVR-Bench benchmarks while remaining fully stackable with reasoning-fine-tuned video generation models.
Key Contributions
- An adaptive planning module dynamically determines task step counts and generates only the immediate next action conditioned on previously generated frames, effectively mitigating long-horizon drift in multi-step video reasoning.
- A closed-loop collaborative mechanism employs a vision-language model to verify each generated clip and inject diagnostic feedback directly into the subsequent action prompt, isolating execution errors to individual segments for targeted repair.
- Evaluations on Gen-ViRe and VBVR-Bench demonstrate consistent improvements over single-inference, Pass@k, and VideoTPO baselines across open- and closed-source video generation models at matched compute, with orthogonal performance gains on reasoning-fine-tuned variants.
Introduction
The shift from static image-based reasoning to video generation has unlocked dynamic, temporally grounded AI applications like scientific visualization, educational demonstrations, and embodied navigation. Despite this progress, current Video Generation Models excel only at short-horizon visual simulation and lack the logical planning required for complex, multi-step tasks. This gap produces two recurring failure modes: overloaded prompts that collapse long sequences into inaccurate short rollouts, and localized mid-clip errors that propagate and corrupt entire trajectories. Existing test-time scaling methods struggle to fix these issues because valid reasoning paths are tightly constrained and often fall outside the generator's native distribution. The authors address these challenges by introducing CollabVR, a closed-loop framework that couples Vision-Language and Video Generation Models at a step-level granularity. The authors leverage a VLM as a progressive planner and verifier that inspects each generated clip, diagnoses failures in real time, and dynamically adjusts subsequent prompts to correct errors before they compound. This stepwise collaboration yields higher reasoning fidelity and interpretability across multiple benchmarks without requiring additional model training.
Method
The authors present CollabVR, a closed-loop framework for video reasoning that integrates a Vision-Language Model (VLM) with a Video Generation Model (VGM) at step-level granularity to address systematic failures in goal-directed video generation tasks. The overall architecture operates as a construction process, where the correct trajectory is assembled incrementally through alternating planning and generation steps, rather than being sampled from the VGM’s output distribution. The framework is composed of two core modules: VLM-Driven Progressive Planning and VLM-VGM Collaborative Reasoning, which collectively address long-horizon drift and mid-clip simulation errors, respectively.
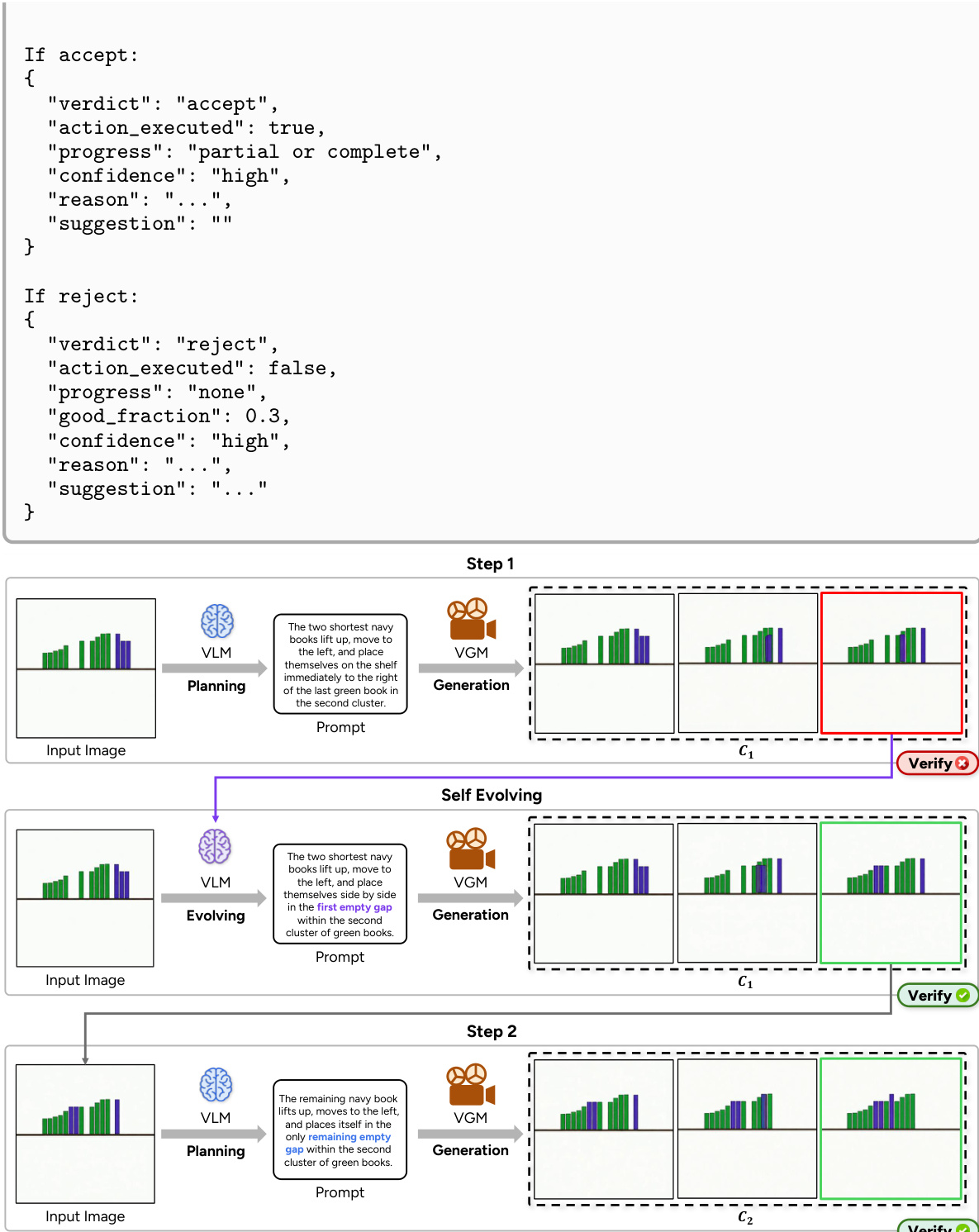
The process begins with an input image and a task prompt, which are used to initialize the reasoning loop. At each step, the VLM acts as a supervisor, first planning the immediate next action based on the current state and the task objective. This planning is performed incrementally, with the VLM determining only the next sub-action rather than committing to a full sequence upfront. The VGM then generates a short clip conditioned on the current frame and the planned action. The generated clip is subsequently verified by the VLM, which produces a structured judgment consisting of an accept/reject verdict and a diagnostic report detailing the failure mode and a repair suggestion. If the clip is accepted, it is appended to the history, and the process continues with the last frame as the new conditioning input. If rejected, the action prompt is evolved using the diagnostic suggestion, and the VGM is re-invoked to generate a new clip, up to a maximum number of retries per step.
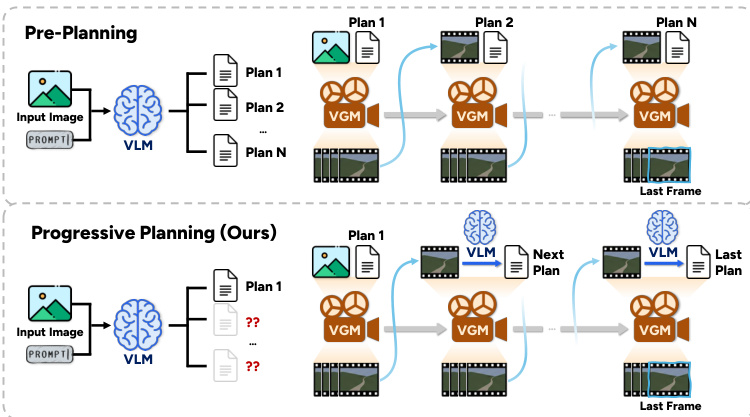
The VLM-Driven Progressive Planning module mitigates the issue of overloaded prompts and long-horizon drift by decoupling the planning phase from the generation phase. Instead of pre-decomposing the entire task into a sequence of actions at the outset, the VLM plans one action at a time, adapting its plan based on the actual output of the VGM. This adaptive planning allows the system to dynamically adjust the number of steps and subsequent actions in response to the realized generation, leading to a more efficient performance-cost trade-off compared to pre-planning approaches. The maximum number of planning steps is capped by a hyperparameter, ensuring termination.
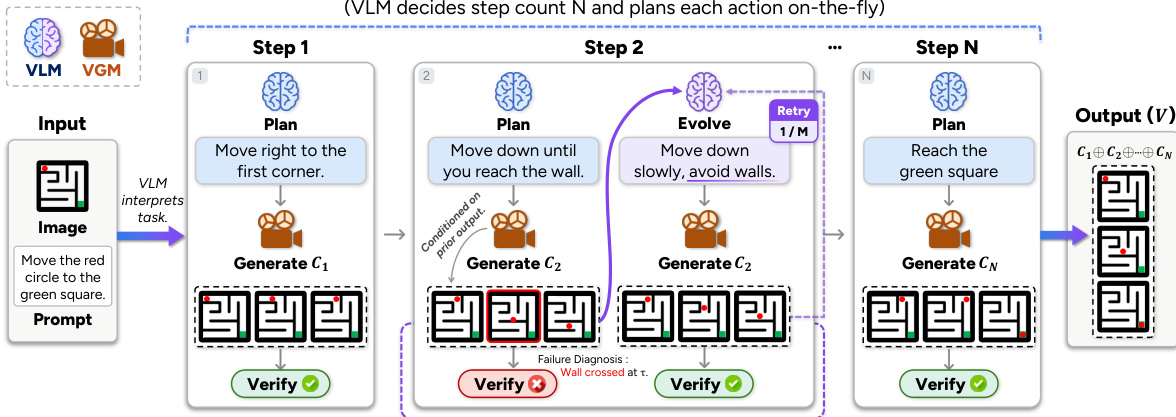
The VLM-VGM Collaborative Reasoning module addresses execution failures by introducing a verification step after each clip generation. The VLM verifier analyzes the generated clip against the planned action, detecting specific failure modes such as incorrect direction, wrong target, or scene collapse. The diagnostic output, which includes a textual reason and an actionable suggestion, is then used to evolve the action prompt for the next generation attempt. This closed-loop feedback mechanism enables the system to repair detected failures directly, rather than relying on post-hoc critique or sampling multiple trajectories. The evolution of the prompt is designed to be efficient, reusing the verifier's output without requiring an additional VLM call.
The framework is designed to be agnostic to the specific VGM used, operating as a test-time scaling method that can be applied to any off-the-shelf generator. The overall process is formalized in Algorithm 1, which outlines the iterative loop of planning, generating, verifying, and evolving, with the final output being the concatenation of all accepted clips. The system can also incorporate auxiliary recovery strategies, such as partial re-generation in navigation tasks, where the VGM is re-invoked from the first failing frame to preserve previously correct progress, thereby making test-time compute more effective by focusing on the failed suffix rather than the entire trajectory.
Experiment
Evaluated across complementary video reasoning benchmarks and multiple generation models, the experiments demonstrate that CollabVR consistently improves task accuracy and human preference ratings while maintaining lower computational costs than standard sampling baselines. Ablation studies validate that progressive task decomposition and failure-aware verification operate as complementary mechanisms, with their relative contributions dynamically adapting to the complexity and structure of each reasoning category. Additional analyses confirm that the framework reliably aligns with human judgment in planning and verification, generalizes effectively across different model architectures, and ultimately highlights that test-time orchestration complements rather than replaces the need for stronger underlying video generation capabilities.
The authors analyze the verifier's performance across different steps in the CollabVR pipeline, showing that the final reject rate increases with each subsequent step, indicating a rise in failure detection as the task progresses. This trend suggests that cumulative errors or visual drift across steps make later stages more challenging for the verifier to accept outputs. The final reject rate rises significantly from Step 1 to Step 3, indicating increasing difficulty in accepting outputs as the task progresses. The verifier is exercised aggressively, with a notable proportion of steps triggering re-generation attempts. The increasing reject rate at deeper steps suggests that errors compound over time, making later stages more prone to failure.

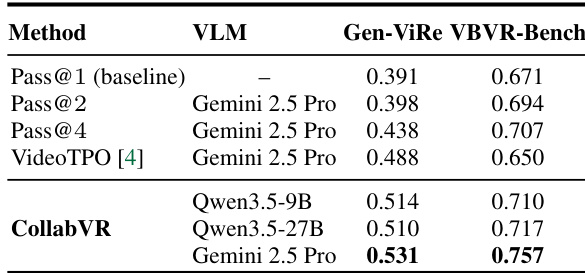
The authors evaluate CollabVR on two video reasoning benchmarks, showing that the framework consistently improves over baselines by combining progressive planning and failure-aware recovery. Results demonstrate that the effectiveness of each module varies by benchmark, with planning more impactful on multi-step tasks and verification more effective on single-step tasks, while the full pipeline achieves gains across all categories. The framework is shown to be robust across different video generation models and verifier choices, with performance scaling with the quality of the verifier. CollabVR improves over baselines by combining progressive planning and failure-aware recovery, with gains across all categories on both benchmarks. The dominant module shifts between planning and verification depending on the benchmark's task complexity, indicating adaptive behavior. The framework's effectiveness is sensitive to verifier quality, with better verifiers leading to more accurate outputs and recovery.
The authors analyze the computational cost of VLM calls in their framework, showing that both planner and step verifier calls have similar latency and input token usage, with the verifier requiring significantly more input tokens due to video content. The output tokens are minimal for both types of calls. This supports the claim that VLM compute is negligible compared to VGM compute. Planner and step verifier calls have comparable latency and output token usage. The step verifier requires substantially more input tokens than the planner due to video content. VLM compute is negligible relative to VGM compute, supporting the use of VGM generation time as a cost proxy.

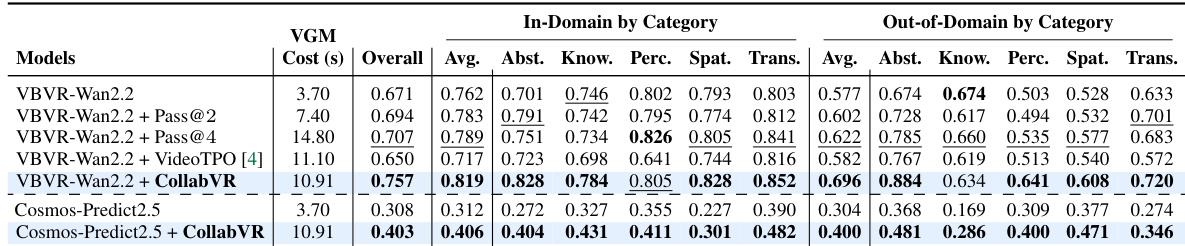
The authors evaluate CollabVR on two video reasoning benchmarks, demonstrating consistent improvements over baseline methods across different video generation models. Results show that CollabVR achieves higher accuracy with lower generation cost compared to resampling-based approaches, and its effectiveness varies depending on the task complexity and the video generation model used. CollabVR outperforms baseline methods on both benchmarks, with gains most pronounced on tasks requiring multi-step reasoning. The framework achieves higher accuracy at lower per-sample generation cost compared to full-video resampling methods. Performance improvements are sensitive to the video generation model, with larger gains observed on models that benefit from progressive planning and verification.
The authors evaluate CollabVR on two video reasoning benchmarks, demonstrating consistent improvements over baseline methods across both open-source and closed-source video generation models. Results show that CollabVR achieves higher accuracy with lower generation costs, particularly on tasks requiring multi-step reasoning, and that the framework's effectiveness varies by task type and video generation model. The performance gains are attributed to adaptive planning and failure-aware recovery mechanisms, with the dominant module depending on the benchmark's task complexity profile. CollabVR achieves higher accuracy than baselines on both open-source and closed-source video models, with improvements most pronounced on complex reasoning tasks. The framework's effectiveness varies by task category, with different modules contributing more on different types of reasoning problems. CollabVR reduces generation cost while improving performance, indicating that adaptive planning and recovery are more efficient than full-video resampling.
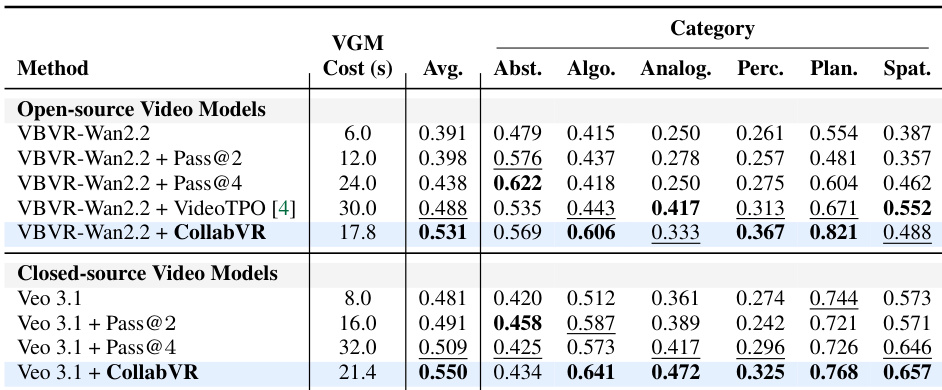
Evaluated across two video reasoning benchmarks and diverse generation models, the experiments validate how progressive planning and failure-aware recovery collaboratively enhance video reasoning quality. Step-wise analysis demonstrates that rejection rates naturally accumulate as tasks progress due to compounding errors, while module comparisons reveal that planning drives performance on complex multi-step tasks and verification excels in simpler scenarios. Computational assessments further confirm that the vision-language model overhead remains negligible, ultimately proving that the adaptive framework achieves superior accuracy and efficiency compared to traditional resampling baselines.