Command Palette
Search for a command to run...
Fast Byte Latent Transformer
Fast Byte Latent Transformer
Julie Kallini Artidoro Pagnoni Tomasz Limisiewicz Gargi Ghosh Luke Zettlemoyer Christopher Potts Xiaochuang Han Srinivasan Iyer
초록
최근 바이트 단위 언어 모델(LMs)은 서브워드 어휘 사전에 의존하지 않고도 토큰 단위 모델과 동등한 성능을 달성하고 있으나, 바이트별 자동 회귀적 생성의 느린 속도로 인해 활용도가 제한되고 있습니다. 본 연구는 바이트 latent 트랜스포머(BLT)에서 새로운 학습 및 생성 기법을 통해 이러한 병목 현상을 해결합니다.첫째, 표준 다음 바이트 예측 손실과 함께 보조 블록 단위의 확산(d Diffusion) 목적을 통해 학습된 새로운 모델이자 가장 빠른 BLT 변형인 BLT Diffusion(BLT-D)을 도입합니다. 이를 통해 매 디코딩 단계에서 여러 바이트를 병렬로 생성할 수 있는 추론 절차를 가능하게 하여, 시퀀스 생성에 필요한 순전파(forward pass) 횟수를 크게 줄입니다.둘째, 추정 디코딩(speculative decoding)에서 영감을 얻은 두 가지 확장을 제안하여, 속도 일부를 희생하더라도 더 높은 생성 품질을 확보합니다. 그중 하나인 BLT Self-speculation(BLT-S)는 BLT의 로컬 디코더가 일반적인 패치 경계를 넘어 추가 바이트를 초안으로 작성하도록 하며, 이는 단일 전체 모델 순전파를 통해 검증됩니다. 또 다른 하나인 BLT Diffusion+Verification(BLT-DV)은 BLT-D에 확산 기반 생성 이후 자동 회귀적 검증 단계를 추가합니다.제안된 모든 방법은 생성 작업에서 BLT 대비 메모리 대역폭 비용을 50% 이상 절감할 것으로 추정됩니다. 각 접근 방식은 고유한 장점을 지니며, 이를 통해 바이트 단위 LLM의 실용적 활용에 존재하던 주요 장벽들을 함께 해소합니다.
One-sentence Summary
Addressing the slow byte-by-byte autoregressive generation limiting byte-level language models, this work enhances the Byte Latent Transformer (BLT) with BLT Diffusion (BLT-D), BLT Self-speculation (BLT-S), and BLT Diffusion+Verification (BLT-DV), which utilize parallel generation and verification and may achieve an estimated memory-bandwidth cost over 50% lower than BLT while removing key barriers to the practical use of subword-free models.
Key Contributions
- The paper introduces BLT Diffusion (BLT-D), a variant trained with an auxiliary block-wise diffusion objective alongside standard next-byte prediction to enable parallel byte generation. This design substantially reduces the number of forward passes required to generate a sequence compared to traditional autoregressive approaches.
- BLT Self-speculation (BLT-S) leverages the existing local decoder to draft bytes past normal patch boundaries without requiring a separate draft model for verification. This extension reduces the number of expensive encoder calls while preserving the output quality of standard autoregressive decoding.
- BLT Diffusion+Verification (BLT-DV) combines fast diffusion drafting with an autoregressive verification step to occupy a middle point in the speed and performance trade-off. Collectively, the methods may achieve an estimated memory-bandwidth cost over 50% lower than the standard BLT on generation tasks.
Introduction
Byte-level language models operate directly on raw bytes to avoid subword tokenization issues like noise sensitivity and multilingual disparities. Despite these benefits, prior work suffers from inefficient inference where sequential byte-by-byte generation creates a memory bandwidth bottleneck. The authors address this by introducing BLT Diffusion, which enables parallel byte generation through block-wise diffusion objectives. They further develop BLT Self-speculation and BLT Diffusion+Verification to balance speed with quality without relying on external draft models. These methods collectively reduce memory-bandwidth costs by over 50% and remove key barriers to practical deployment.
Dataset
- Dataset Composition and Structure
- The authors use raw training samples formatted as byte sequences segmented into variable-length patches.
- The data structure consists of fixed-length blocks constructed from these patches to enable block-wise masked prediction.
- Preprocessing and Construction Details
- An entropy patcher dynamically segments the input to define patch boundaries.
- Blocks are created by taking consecutive bytes starting at patch indices and often extend beyond the original patch size.
- Special padding tokens are applied when blocks exceed the sequence length.
- Original byte positional indices are recorded to ensure correct RoPE positional encodings in the decoder.
- Training Usage and Masking Strategy
- The model employs a diffusion process where a continuous timestep is sampled during training.
- Bytes are independently replaced with [MASK] tokens based on the sampled probability to create a corrupted input.
- This setup allows the model to reconstruct the clean sequence from the corrupted input during inference.
Method
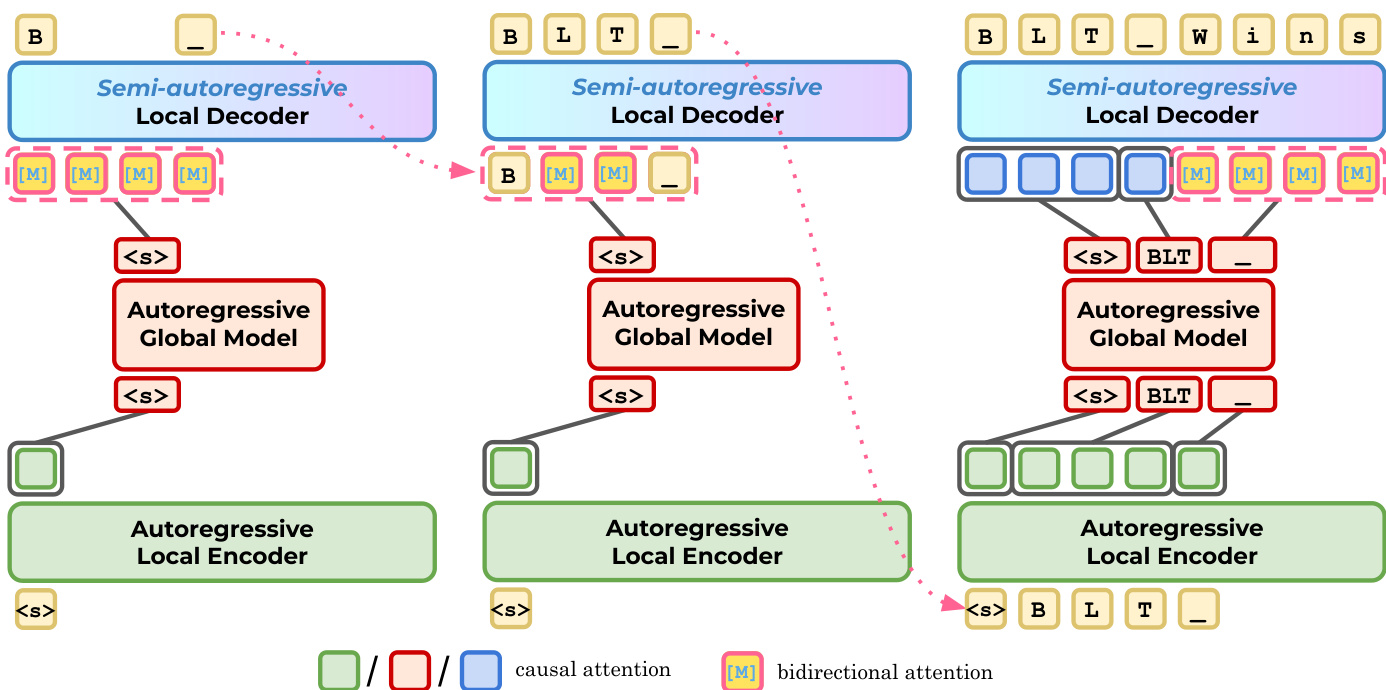
The Byte-Level Transformer (BLT) operates directly on raw byte sequences, utilizing a hierarchical architecture to balance efficiency and performance. The model consists of three primary components: a local encoder E, a global transformer G, and a local decoder D. The local encoder embeds the input byte sequence into initial representations, which are then processed into latent token representations by the global model. These latent tokens are subsequently decoded back into bytes by the local decoder. Refer to the framework diagram below for a visualization of this interaction between the local and global components.
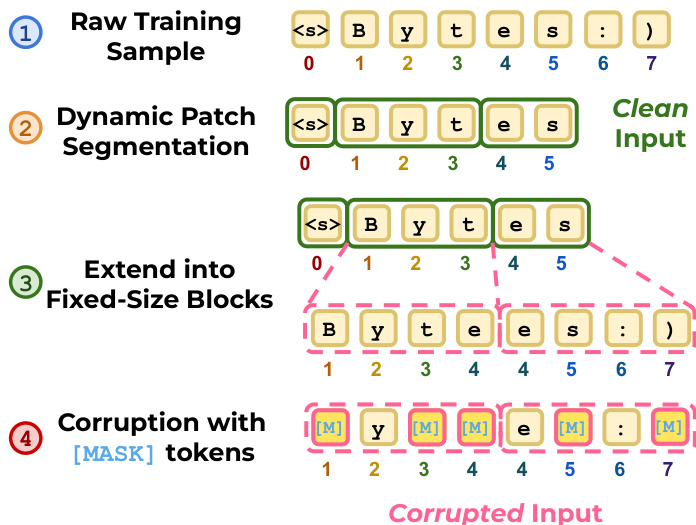
To enable efficient block diffusion decoding, BLT-D introduces a specialized training pipeline. The process begins with dynamic patch segmentation, where raw training samples are split into variable-length patches based on entropy. These patches are then extended into fixed-size blocks and corrupted with [MASK] tokens to create the training input. Refer to the figure below for the step-by-step data preprocessing workflow.
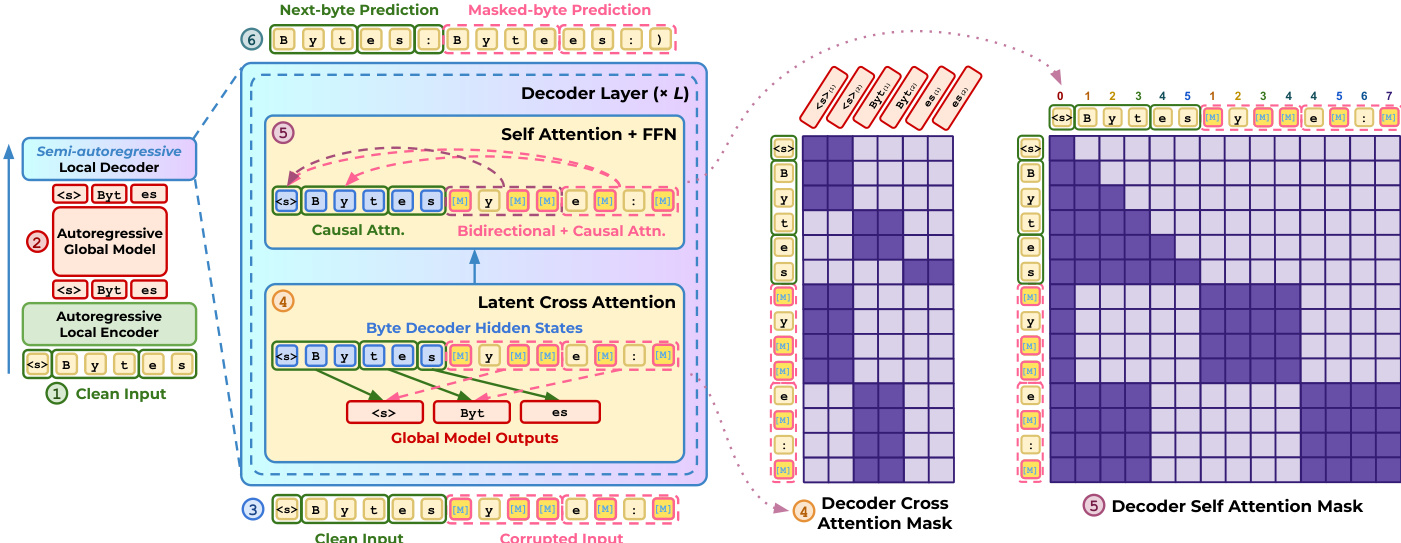
During the training forward pass, the model processes both clean and corrupted inputs. The encoder and global model handle the clean input to produce latent representations, which are then used by the decoder. The decoder applies cross-attention to these latent tokens while employing specific attention masks: causal attention for the clean sequence and bidirectional attention within the corrupted blocks. The total training objective combines a next-byte prediction loss for the clean sequence with a masked diffusion loss for the corrupted blocks. The complete training architecture is illustrated below.
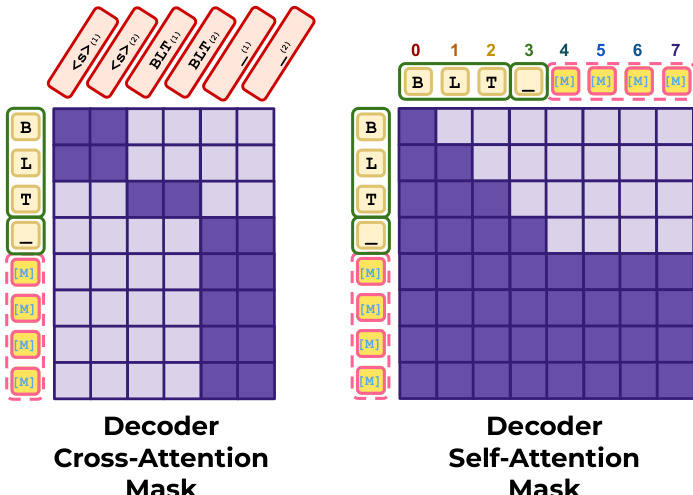
Inference for BLT-D relies on carefully constructed attention masks to support block diffusion. For the decoder's cross-attention, clean positions attend to their corresponding latent tokens, while masked block positions attend to the last available latent token. For self-attention, the clean prefix uses a causal mask, whereas the corrupted block utilizes a fully bidirectional mask. These patterns are visualized in the mask diagrams below.
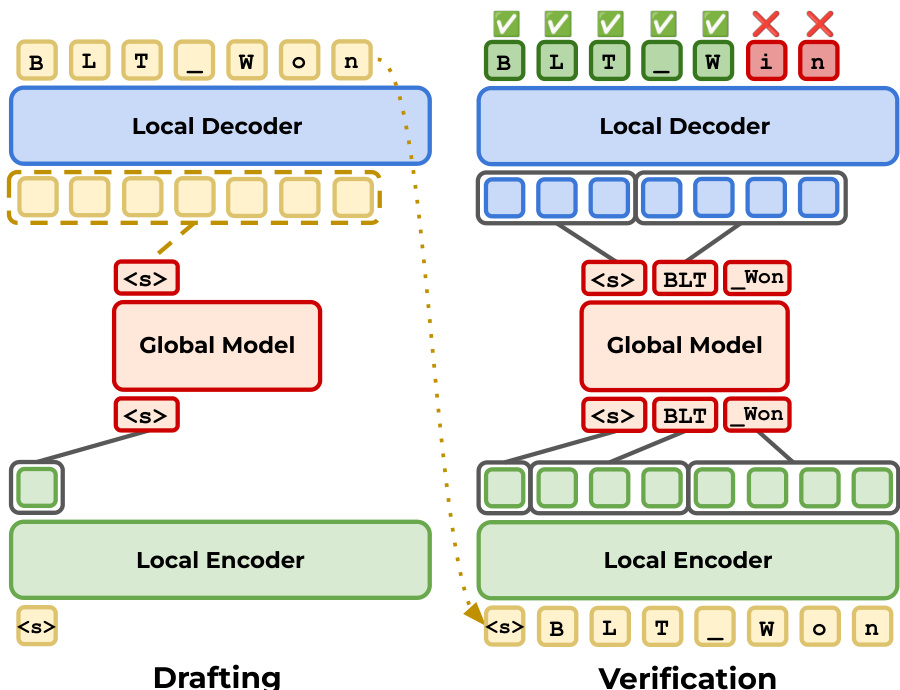
Finally, the authors propose extensions like BLT-S and BLT-DV to further enhance efficiency through speculative decoding. In this paradigm, the model drafts a sequence of tokens using a fast mechanism, such as diffusion or extended autoregressive decoding, and then verifies these drafts using a slower, more accurate pass. The drafting stage proposes candidate bytes, and the verification stage accepts or rejects them based on the model's predictions. This iterative process is depicted in the figure below.
Experiment
The experiments evaluate byte-level language models across translation and code generation tasks using 1B and 3B parameter scales to assess the trade-offs between inference speed and generation quality. Results indicate that the BLT-D framework significantly improves efficiency by reducing memory bandwidth and network function evaluations compared to standard autoregressive baselines, though larger block sizes may slightly degrade coding performance while maintaining translation accuracy. Additional evaluations confirm that these diffusion-based methods preserve autoregressive capabilities on reasoning benchmarks and allow for adjustable control over the balance between output diversity and computational cost.
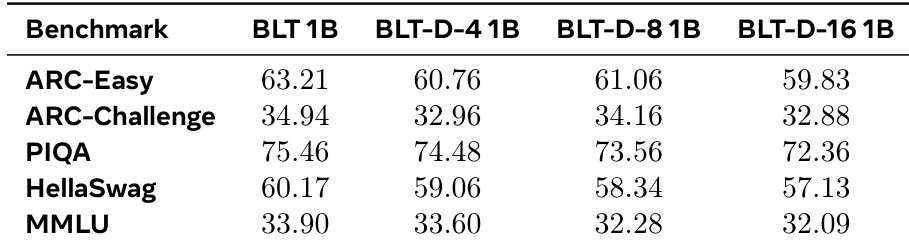
The the the table presents likelihood-based evaluation results for 1B parameter models across five standard language understanding and reasoning benchmarks. The baseline model consistently outperforms the diffusion-based variants, though the variants maintain competitive scores that approach the baseline performance. This indicates that the diffusion mechanism preserves strong autoregressive capabilities despite a minor trade-off in accuracy. The baseline model achieves the highest scores across all five evaluated benchmarks compared to the diffusion variants. Increasing the diffusion block size generally leads to a slight reduction in performance scores across the datasets. Diffusion variants demonstrate robust performance on reasoning tasks, remaining close to the baseline despite the architectural changes.
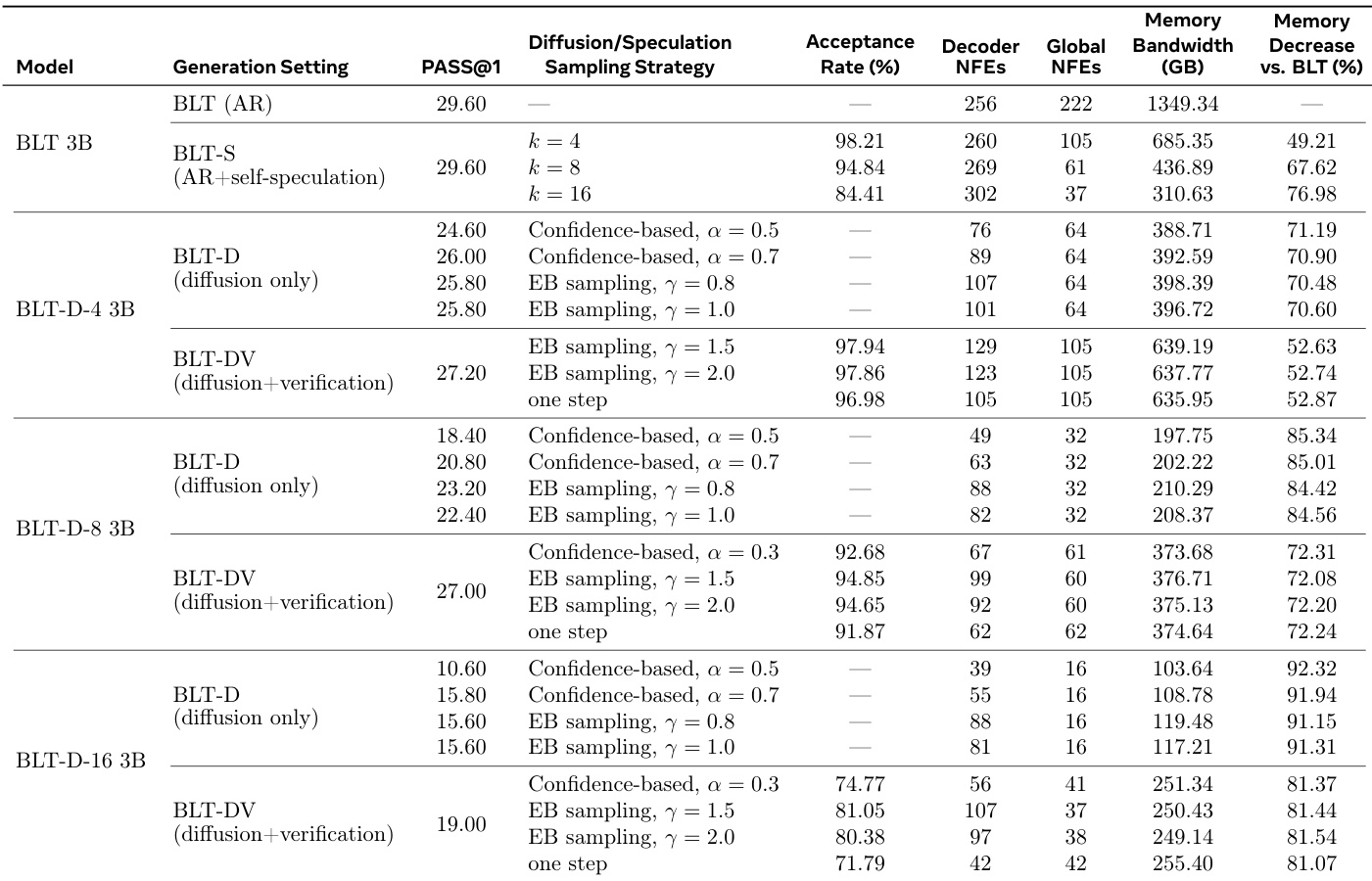
The authors compare the efficiency and quality of standard autoregressive generation against diffusion-based and speculative inference methods. The data shows that diffusion models significantly reduce memory bandwidth and network function evaluations compared to the baseline, with efficiency increasing as the diffusion block size grows. However, this speed improvement correlates with a drop in task performance, which can be partially recovered by adding a verification step. Speculative inference achieves significant memory savings without compromising task performance relative to the baseline. Larger diffusion block sizes yield greater reductions in computational cost but result in lower generation quality. Verification mechanisms improve the accuracy of diffusion models but require additional computational resources compared to diffusion-only settings.
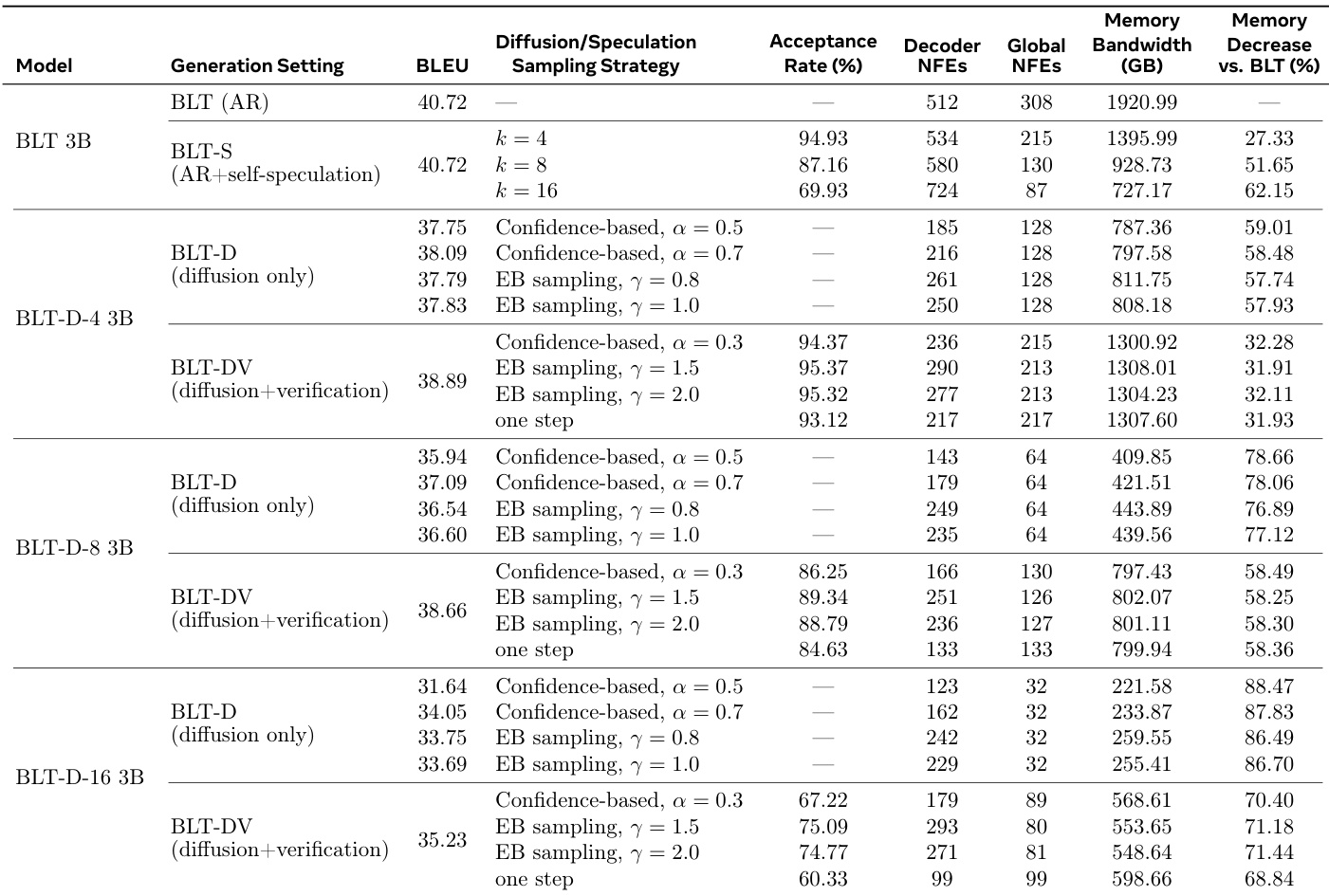
The the the table compares the baseline BLT 3B model with diffusion-based variants and speculation extensions, highlighting the trade-offs between inference efficiency and generation quality. While diffusion-only models significantly reduce memory bandwidth and network function evaluations, they generally exhibit lower BLEU scores than the autoregressive baseline. The verification-based extension recovers much of this performance loss while maintaining substantial efficiency gains, and the self-speculation method matches baseline performance with improved efficiency. Increasing the diffusion block size improves efficiency metrics like memory bandwidth and NFEs but leads to a decline in task performance scores. The verification-based BLT-DV variant achieves higher generation quality than the diffusion-only BLT-D models while still offering significant reductions in memory usage compared to the baseline. The self-speculation BLT-S method maintains the baseline model's task performance while substantially reducing memory bandwidth and global network function evaluations.
The authors evaluate inference extensions including BLT-S, BLT-D, and BLT-DV against a baseline autoregressive model to characterize speed-quality trade-offs. Results indicate that diffusion-based methods substantially reduce memory bandwidth and network function evaluations, though often at the cost of task performance metrics. Verification-based approaches help recover some of this performance loss while retaining significant efficiency improvements over the standard baseline. Diffusion-only models achieve the highest efficiency gains, particularly as block sizes increase, leading to the lowest memory bandwidth usage. Adding verification to diffusion models improves generation quality scores compared to diffusion-only variants, though it increases global network function evaluations. The self-speculation method maintains task performance levels similar to the baseline while still delivering notable reductions in memory bandwidth requirements.
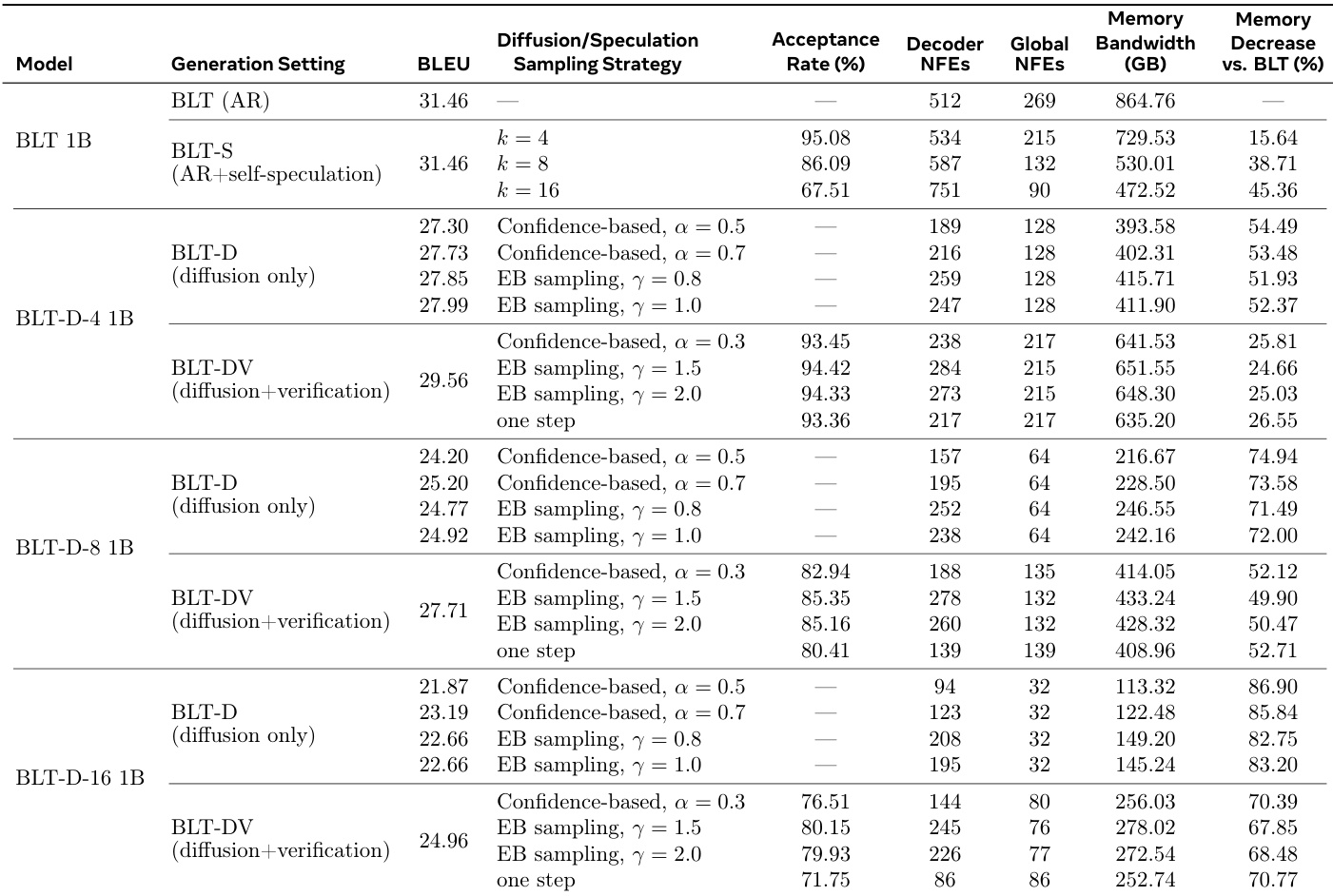
The authors evaluate various inference strategies for language models, comparing diffusion-based and speculative methods against a standard autoregressive baseline. Results show that diffusion-based approaches significantly reduce memory bandwidth and computational steps, with efficiency gains increasing as block sizes grow. Verification-based extensions help recover task performance lost in pure diffusion settings while preserving most of the efficiency benefits. Diffusion-based models consistently achieve lower memory bandwidth usage and fewer network function evaluations than the autoregressive baseline. Adding verification to diffusion generation improves task quality but requires more computational resources than diffusion-only methods. Speculative generation maintains performance comparable to the baseline while offering substantial reductions in memory bandwidth requirements.
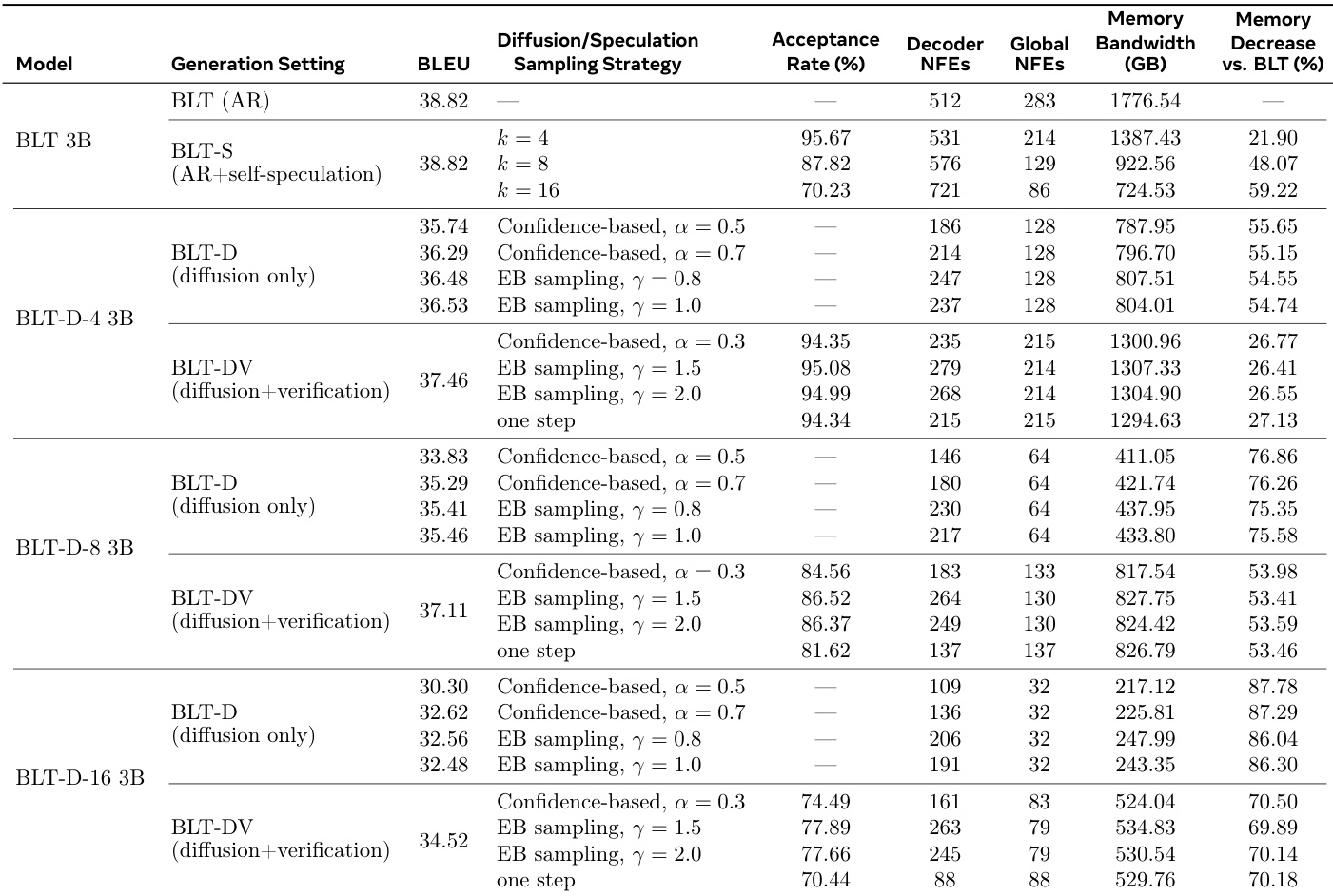
The experiments evaluate standard autoregressive baselines against diffusion-based and speculative inference methods across language understanding and generation tasks. Although the baseline consistently achieves the highest accuracy, diffusion variants significantly reduce memory bandwidth and computational evaluations, with larger block sizes yielding greater efficiency but lower quality. Verification mechanisms help recover performance losses in diffusion models, whereas speculative methods maintain baseline performance levels while offering substantial efficiency gains, ultimately highlighting a trade-off between inference speed and generation quality that can be balanced through architectural extensions.