Command Palette
Search for a command to run...
Relit-LiVE: 환경 비디오를 함께 학습하여 비디오 재조명하기
Relit-LiVE: 환경 비디오를 함께 학습하여 비디오 재조명하기
Weiqing Xiao Hong Li Xiuyu Yang Houyuan Chen Wenyi Li Tianqi Liu Shaocong Xu Chongjie Ye Hao Zhao Beibei Wang
초록
최근 연구들은 대규모 비디오 확산 모델을 비디오를 내재적 장면 표현으로 분해한 후 새로운 조명 하에서 순방향 렌더링을 수행함으로써 신경 렌더러로 재사용할 수 있음을 보여주었습니다. 비록 유망하지만, 이 패러다임은 근본적으로 정확한 내재적 분해에 의존하며, 이는 실제 세계의 비디오에서 여전히 매우 신뢰성이 낮으며, 조명 재구성 과정에서 왜곡된 외관, 손상된 재질, 그리고 누적된 시간적 아티팩트를 초래하는 경우가 많습니다. 본 연구에서는 카메라 위치의 사전 지식 없이도 물리적으로 일관되고 시간적으로 안정적인 결과를 생성하는 새로운 비디오 조명 재구성 프레임워크인 Relit-LiVE를 제시합니다. 우리의 핵심 통찰은 렌더링 과정에 원본 참조 이미지를 명시적으로 도입하여, 내재적 표현에서 필연적으로 손실되거나 손상되는 중요한 장면 단서를 모델이 복원할 수 있도록 하는 것입니다. 또한, 우리는 단일 확산 프로세스 내에서 조명 재구성된 비디오와 각 카메라 시점에 정렬된 프레임별 환경 맵을 동시에 생성하는 새로운 환경 비디오 예측 공식을 제안합니다. 이러한 결합된 예측은 강력한 기하학적-조명 정합성을 강제하며, 동적 조명과 카메라 움직임을 자연스럽게 지원하여 비디오 조명 재구성에서의 물리적 일관성을 크게 향상시키고, 프레임별 카메라 위치의 사전 지식에 대한 요구를 완화합니다. 광범위한 실험을 통해 Relit-LiVE가 합성 및 실제 세계 벤치마크에서 최신 비디오 조명 재구성 및 신경 렌더링 방법들을 일관되게 능가함을 입증했습니다. 조명 재구성을 넘어, 우리의 프레임워크는 장면 수준 렌더링, 재질 편집, 객체 삽입, 그리고 스트리밍 비디오 조명 재구성을 포함한 다양한 하위 응용 분야를 자연스럽게 지원합니다. 프로젝트는 https://github.com/zhuxing0/Relit-LiVE에서 확인하실 수 있습니다.
One-sentence Summary
RELIT-LIVE is a diffusion-based video relighting framework that jointly generates relit videos and per-frame environment maps in a single process while leveraging raw reference images to bypass unreliable intrinsic decomposition and eliminate the need for known camera poses, thereby producing physically consistent and temporally stable results that support dynamic lighting and camera motion, with extensive experiments demonstrating consistent superiority over state-of-the-art video relighting and neural rendering methods across synthetic and real-world benchmarks.
Key Contributions
- This work introduces RELiT-LiVE, a video relighting framework that produces physically consistent and temporally stable results without requiring prior camera pose estimation.
- The framework explicitly incorporates raw reference images into the diffusion rendering pipeline to recover scene cues lost during intrinsic decomposition. A novel environment video prediction formulation simultaneously generates relit videos and per-frame environment maps aligned with camera viewpoints in a single diffusion process, enforcing strong geometric-illumination alignment.
- Complementary training strategies utilizing latent-space interpolation and cycle-consistent self-supervised illumination learning enhance generalization and temporal lighting coherence. Extensive experiments on synthetic and real-world benchmarks demonstrate that the framework consistently outperforms state-of-the-art methods while supporting downstream applications such as material editing and streaming video relighting.
Introduction
Video relighting enables creators and vision systems to modify illumination while preserving scene geometry and materials, but achieving physically accurate and temporally stable results remains a persistent challenge. Prior approaches either rely on direct diffusion generation, which struggles with precise lighting control and retains original illumination artifacts, or depend on intrinsic decomposition pipelines that frequently fail on real-world footage, producing distorted materials, temporal errors, and a strict requirement for camera pose data. The authors address these limitations with RELIT-LIVE, a framework that eliminates camera pose dependencies by jointly generating relit videos and per-frame environment maps within a single diffusion process. They further leverage an RGB-intrinsic fusion renderer that uses raw reference frames to inject real-world lighting cues alongside physical constraints, ensuring tight geometry-illumination alignment. Paired with novel latent-space interpolation and self-supervised temporal coherence training, the method delivers physically plausible relighting across diverse scenes while supporting downstream tasks like material editing and neural rendering.
Method
The authors leverage a novel framework for video relighting that combines a RGB-Intrinsic fusion renderer with joint generation of the relit video and environment video, enabling physically consistent and temporally stable results without requiring explicit camera pose estimation. The overall architecture is designed to bypass the limitations of traditional intrinsic decomposition by directly utilizing observable RGB information while maintaining physical plausibility through intrinsic constraints.
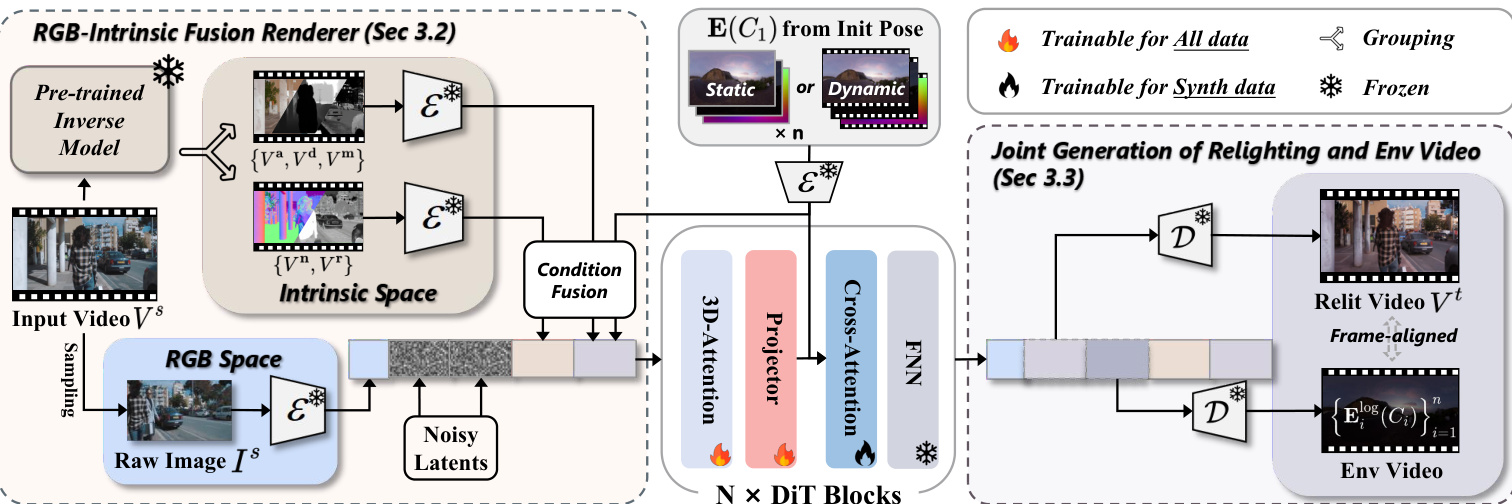
The framework begins by decomposing the input video Vs into intrinsic properties using a pre-trained inverse rendering model. This produces a set of G-buffers including base color Va, surface normal Vn, relative depth Vd, roughness Vr, and metallic Vm. These G-buffers are then encoded into latent space using a pre-trained VAE encoder E, resulting in corresponding latents {za,zn,zd,zr,zm}. To improve efficiency and convergence, the authors propose a partial grouping fusion strategy, summing latents for correlated intrinsic properties: z{a,d,m}=za+zd+zm and z{n,r}=zn+zr. This creates two intrinsic condition latents.
As shown in the figure below, the framework also incorporates a raw image from the input video, randomly sampled and encoded into a latent zI. This latent is concatenated with the intrinsic condition latents along the frame dimension to guide the generation process, effectively suppressing the propagation of source lighting. The random sampling strategy breaks fixed correspondences and is applied at each denoising step to preserve detail.
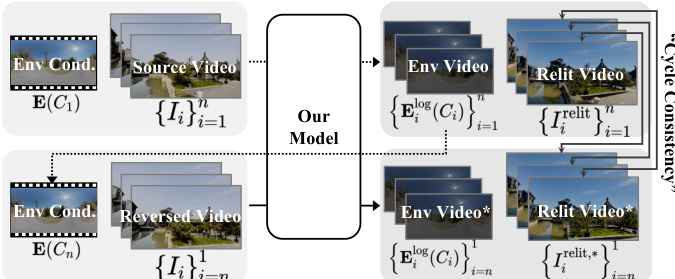
Lighting conditions are represented by HDR environment maps E(C1) under an initial viewpoint C1. These maps are transformed into three complementary representations: LDR images via Reinhard tonemapping, normalized log-intensity images, and directional encoding images. Each representation is encoded into latent space and concatenated to form hE, which is processed by a convolutional layer to obtain cE. This is concatenated with the other condition latents and fed into the DiT video model. The model simultaneously generates the relit video Vt and the corresponding environment video, specifically the normalized log intensity maps {Eilog(Ci)}i=1n, which can be inverse-transformed to HDR and LDR.

During training, the model learns a denoising function fθ that maps the concatenated noise-added latents (relit video, environment video, reference latent, intrinsic latents, and lighting conditions) to the denoised outputs. This joint generation approach allows the model to implicitly infer lighting transformations, eliminating the need for explicit camera pose estimation and enhancing spatio-temporal lighting accuracy. The training process is divided into three stages, with the final stage employing self-supervised learning based on illumination consistency to improve generalization across diverse scenes and lighting conditions.
Experiment
The evaluation compares RELiT-LiVE against state-of-the-art video relighting techniques across diverse synthetic and real-world domains, validating its capacity to maintain material consistency, temporal stability, and physically accurate lighting interactions. Qualitative assessments demonstrate that the model successfully decouples original illumination and handles complex materials without the distortions observed in competing methods, while environment map generation experiments confirm its ability to produce temporally stable lighting across changing camera viewpoints. Additional tests verify the method's versatility in downstream tasks like scene editing and specular highlight removal, and ablation studies highlight how raw reference images, joint environment-video generation, and specialized training strategies collectively drive robust, physically plausible relighting.
The authors compare their method with existing video relighting approaches across synthetic and video datasets, evaluating performance using metrics such as PSNR, SSIM, and LPIPS. Results show that their approach achieves superior performance in both image and video relighting tasks, particularly in handling complex materials and maintaining temporal consistency. The method demonstrates significant improvements over baselines in visual fidelity and material consistency, with notable gains in both synthetic and real-world scenarios. The proposed method outperforms existing approaches in visual fidelity and material consistency across synthetic and video datasets. The method achieves superior results in handling complex materials and maintaining temporal consistency compared to baselines. Quantitative improvements are observed in metrics such as PSNR, SSIM, and LPIPS, indicating enhanced relighting quality and physical accuracy.

The authors compare their method with several advanced video relighting approaches across different datasets, evaluating performance on metrics related to temporal consistency, material consistency, and user study results. The proposed method achieves superior performance in all evaluated aspects, particularly in material consistency and user preference, while demonstrating robustness across various lighting conditions and video types. The proposed method outperforms existing approaches in material consistency and user study metrics across different lighting conditions. The method demonstrates strong temporal consistency, especially in handling dynamic lighting and long video sequences. It achieves superior results compared to text-based and environment map-based methods in maintaining physically accurate material properties and lighting effects.

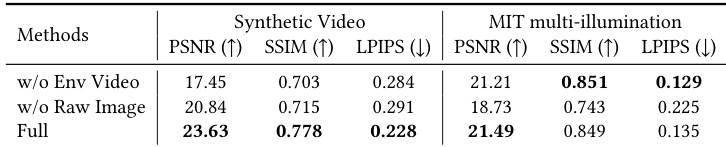
The authors compare their method with variants that omit key components, evaluating performance on synthetic and MIT multi-illumination datasets. Results show that including both environment video generation and raw reference images significantly improves relighting quality across all metrics. The full model consistently outperforms ablated versions, particularly in visual fidelity and material consistency. Including raw reference images significantly improves relighting quality, especially on complex materials. Joint generation of environment video and relighting leads to better performance, particularly under dynamic lighting and camera motion. The full model outperforms ablated versions across all metrics on both synthetic and MIT multi-illumination datasets.
The authors compare their method with a baseline approach across multiple video relighting tasks, evaluating performance on synthetic and real-world datasets. Results show that their method achieves better visual quality and material consistency, with improvements in both training and inference efficiency compared to the baseline. The proposed method outperforms the baseline in visual quality and material consistency across synthetic and real-world datasets. The method achieves significant improvements in training and inference efficiency, reducing GPU memory usage. The baseline approach shows lower performance in handling complex materials and maintaining temporal consistency.

The authors compare their method with existing video relighting approaches across multiple datasets, including synthetic and real-world scenarios. Results show that their method outperforms baselines in terms of visual and material fidelity, particularly in handling complex materials and maintaining temporal consistency. The approach also demonstrates superior performance in generating accurate environment maps for dynamic lighting conditions. the method achieves superior performance across all metrics compared to existing approaches on both synthetic and real-world datasets. The method demonstrates strong material consistency and accurate handling of complex lighting effects such as reflections and refractions. It effectively generates temporally consistent environment maps, enabling accurate lighting estimation across video frames.

The proposed method is evaluated against existing baselines and ablated variants across synthetic and real-world video datasets, using standard fidelity measures, consistency assessments, and user studies to validate overall relighting performance and component contributions. Main comparisons confirm that the approach consistently delivers superior visual and material fidelity, effectively preserving temporal consistency under dynamic lighting and camera motion while accurately rendering complex surfaces. Ablation experiments validate the necessity of jointly generating environment videos alongside raw reference inputs for high-quality material handling, while efficiency tests verify reduced computational overhead and stronger user preference, establishing the method as a robust solution for physically accurate video relighting.