Command Palette
Search for a command to run...
Continuous 잠재 확산 언어 모델
Continuous 잠재 확산 언어 모델
초록
자회귀(autoregressive) 패러다임 하에서 대규모 언어 모델은 눈에 띄는 성과를 거두었으나, 고품질 텍스트 생성이 반드시 고정된 좌에서 우로의 순서에 묶일 필요는 없다. 기존 대안들은 여전히 생성 효율성, 확장 가능한 표현 학습, 효과적인 전역 의미 모델링을 함께 달성하는 데 어려움을 겪고 있다. 본 연구는 Cola DLM을 제안하는데, 이는 계층적 정보 분해를 통해 텍스트 생성을 재구성하는 계층적 잠재 확산 언어 모델(hierarchical latent diffusion language model)이다. Cola DLM은 먼저 Text VAE를 사용하여 안정적인 텍스트-잠재 매핑(text-to-latent mapping)을 학습하고, 이어 블록 인과적(block-causal) DiT를 사용하여 연속 잠재 공간(global semantic prior)에서 전역 의미 사전(prior)을 모델링하며, 마지막으로 조건부 디코딩(conditional decoding)을 통해 텍스트를 생성한다. 통합된 마르코프 경로(Markov-path) 관점에서 볼 때, 이 모델의 확산 과정은 토큰 수준 관측의 복원이 아닌 잠재 사전의 수송(latent prior transport)을 수행함으로써 전역 의미 조직화와 로컬 텍스트 구현을 분리한다. 이러한 설계는 더 유연한 비자회귀 유도 편향(non-autoregressive inductive bias)을 제공하며, 연속 공간에서 의미 압축과 사전 적합(prior fitting)을 지원하고 자연스럽게 다른 연속 모드(continuous modalities)로 확장된다. 4가지 연구 질문, 8개 벤치마크, 엄격히 매칭된 약 20억 파라미터 규모 자회귀 및 LLaDA 베이스라인, 그리고 약 2000 EFLOPs까지의 스케일링 곡선(scaling curves)을 아우르는 실험을 통해 Cola DLM의 효과적인 전체 구성을 도출하고, 텍스트 생성에 대한 강력한 스케일링 특성을 검증했다. 총체적으로 본 결과들은 계층적 연속 잠재 사전 모델링이 엄격한 토큰 수준 언어 모델링에 대한 원칙적인 대안임을 입증하며, 여기서 생성 품질과 스케일링 행동은 가능도(likelihood)보다 모델 능력을 더 잘 반영할 수 있음을 시사한다. 또한 이는 이산적 텍스트와 연속적 모드를 아우르는 통합 모델링을 향한 구체적 경로를 제시한다.
One-sentence Summary
The authors propose Cola DLM, a hierarchical latent diffusion language model that utilizes a Text VAE and block-causal DiT to execute continuous latent prior transport rather than token-level observation recovery, thereby decoupling global semantic organization from local textual realization while demonstrating strong scaling behavior up to approximately 2000 EFLOPs across eight benchmarks against strictly matched ~2B-parameter autoregressive and LLaDA baselines.
Key Contributions
- This work introduces Cola DLM, a hierarchical latent diffusion language model that decomposes text generation into a Text VAE for stable text-to-latent mapping, a block-causal DiT for continuous semantic prior learning, and conditional decoding for final output.
- The framework reframes the diffusion process as latent prior transport rather than token-level observation recovery, decoupling global semantic organization from local textual realization. This architecture establishes a flexible non-autoregressive inductive bias that enables semantic compression in continuous space and provides a unified interface for multimodal compatibility.
- Extensive evaluations across eight benchmarks, four research questions, and scaling curves up to approximately 2000 EFLOPs against strictly matched ~2B-parameter autoregressive and LLaDA baselines verify the model's strong scaling behavior. These results demonstrate that generation quality and scaling trajectories serve as more reliable capability indicators than traditional perplexity metrics.
Introduction
Large language models have long dominated text generation through autoregressive paradigms, yet high-quality output does not inherently require a fixed sequential order. This distinction matters because efficient, scalable, and semantically coherent generation is essential for advancing both standalone language systems and future multimodal architectures. Prior approaches struggle to balance these goals, as autoregressive models incur heavy sequential inference costs while diffusion methods either suffer from expensive multi-step sampling or fail to explicitly model global semantic priors. To bridge this gap, the authors introduce Cola DLM, a hierarchical continuous latent diffusion language model that decouples generation into global semantic organization and local textual realization. They leverage a Text VAE for stable text-to-latent mapping, a block-causal DiT for latent prior transport, and a conditional decoder for final output, establishing a flexible non-autoregressive paradigm with strong scaling behavior and a clear pathway toward unified multimodal modeling.
Dataset
-
Dataset Composition and Sources: The authors train the model using external open-source pretraining data. For evaluation, they draw from a curated collection of established open benchmarks spanning text continuation, reading comprehension, factual knowledge, and commonsense reasoning.
-
Subset Details:
- LAMBADA: Long-context word prediction benchmark used to test global semantic modeling and long-range contextual coherence.
- MMLU: Multitask multiple-choice benchmark covering humanities, STEM, and professional domains to assess broad factual knowledge.
- SIQA: Three-option multiple-choice benchmark focused on social commonsense reasoning and plausible situational reactions.
- SQuAD: Reading comprehension dataset applied in a generative setting to evaluate open-form answer generation.
- Story Cloze: Four-sentence story completion task measuring narrative coherence and causal reasoning.
- OBQA: Science and commonsense QA benchmark requiring multi-hop reasoning beyond direct fact recall.
- RACE: Large-scale exam-style reading comprehension test focusing on inference and passage understanding.
- HellaSwag: Adversarial multiple-choice benchmark for grounded commonsense reasoning and sentence continuation.
-
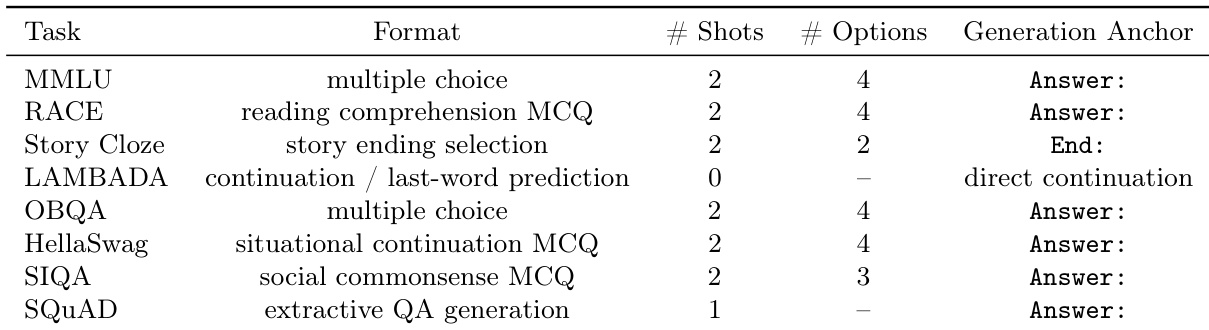
Data Usage and Processing: The team evaluates internal model components using randomly sampled subsets from the LAMBADA, MMLU, and SIQA test sets to maintain efficiency and controlled comparisons. Broader external comparisons utilize the full test sets of SQuAD, Story Cloze, OBQA, RACE, and HellaSwag. All evaluations follow a unified few-shot protocol, with accuracy measured via strict string matching against ground truth answers under predefined prompt templates.
-
Processing and Setup Details: The authors do not specify cropping strategies or metadata construction in the main text, deferring such data preparation details to the appendix. For training and evaluation, all models share the OLMo 2 tokenizer, a maximum sequence length of 512, identical random seeds, and matching optimization schedules. The authors evaluate all checkpoints at a fixed FLOPs budget without using exponential moving average weights to ensure consistent comparisons.
Method
The Cola DLM framework is designed as a hierarchical latent-variable language model that separates global semantic information from local text realization, enabling flexible and efficient text generation. The core architecture leverages a continuous latent space to model text, where a discrete text sequence x is mapped to a continuous latent variable z0. The generative process is defined by a conditional decoder pθ(x∣z0) and a latent prior pψ(z0), which together form the joint distribution p(x,z0)=pθ(x∣z0)pψ(z0). The prior pψ(z0) is modeled using a continuous-flow prior, defined by a base distribution p1(z1)=N(0,I) and a time-dependent vector field vψ(zt,t) that governs the ODE dtdzt=vψ(zt,t). This flow map induces the prior distribution pψ=(Φ0←1ψ)♯p1. The latent space is further decomposed into blocks, z0=(z0(1),…,z0(B)), with a factorization pψ(z0)=pψ(z0(1))∏b=2Bpψ(z0(b)∣z0(<b)), which corresponds to the block-causal prior learning and inference used in the model.

The model's training is structured in two distinct stages. In the first stage, a Text VAE is pre-trained to establish a stable text-latent correspondence. The encoder maps the text into the latent space, and the decoder reconstructs the original text conditioned on the latent. This objective, LVAE, includes a reconstruction loss, a KL divergence regularization, and a BERT-style masking loss to prevent the VAE from collapsing semantically. The VAE is not the final generative prior but serves to stabilize the interface between text and latent representations. In the second stage, the model jointly pre-trains the Text VAE and a Text DiT (Diffusion Transformer) to learn the conditional prior on the stabilized latent space. The Text DiT learns the block-level conditional prior using a Flow Matching objective, LFM, which regresses the vector field vψ to the conditional mean of the velocity field on a bridge path from the aggregated posterior qˉϕ to the base distribution p1. This stage also includes regularization terms to preserve the autoencoding structure and suppress latent drift, ensuring a controlled co-adaptation between the latent representation and the learned flow prior.
At inference time, the model first encodes the prefix into a clean latent condition. It then generates the response latent block by block, with each block obtained by transporting a noise seed under the historical condition. The decoder outputs the text response conditioned on the prefix and the generated latent blocks. The workflow of Cola DLM, as illustrated in the figure below, implements this hierarchical probabilistic model through two training stages and one inference stage, rather than a mechanical cascade of VAE, DiT, and decoder components.
Experiment
The experiments evaluate Cola DLM against strictly matched autoregressive and discrete diffusion baselines under a unified few-shot generative protocol, systematically validating the presence of global semantic structures in the continuous latent space. Ablation studies demonstrate that optimal generation relies on carefully calibrated noise schedules, moderate processing granularities, and balanced inference guidance to align denoising with semantic information regimes, while scaling comparisons reveal persistent performance gains on reasoning and global-semantic tasks. These findings collectively highlight a fundamental disconnect between likelihood-based metrics and actual generation quality, confirming that the semantic smoothness and continuous prior formulation of the latent space drive robust, scalable language modeling.
The experiment evaluates the impact of different VAE logSNR settings on model performance under two compute budgets. Results show that learnable VAE logSNR consistently outperforms fixed settings across both budgets, with the highest performance achieved at the higher compute budget. The performance trends across tasks are generally aligned, indicating a stable and effective calibration of the denoising process. Learnable VAE logSNR achieves the highest performance across all tasks and compute budgets compared to fixed settings. Performance improves with higher compute budgets, with the most significant gains observed under the learnable VAE logSNR setting. The relative ranking of tasks remains consistent across different logSNR settings and compute budgets, indicating stable and predictable trends.
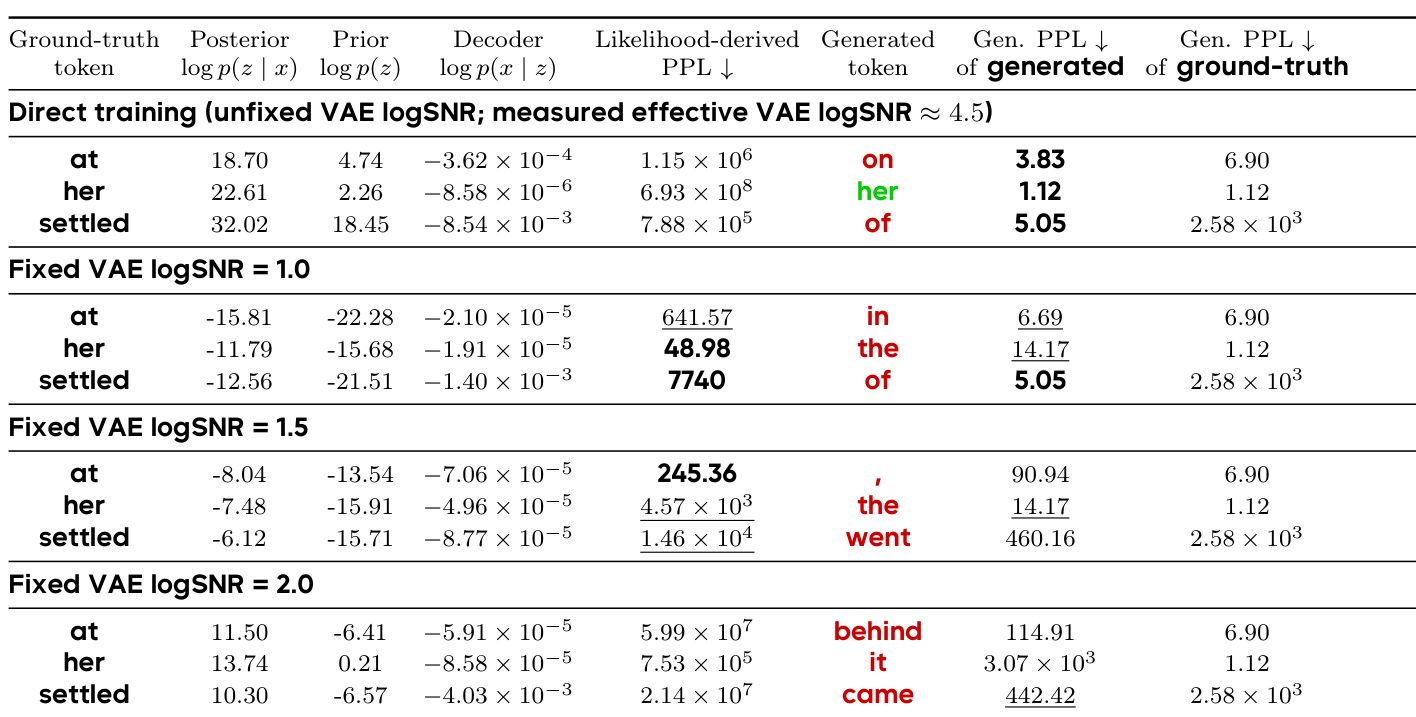
The the the table presents a comparison of token-level generation outcomes under different VAE logSNR settings, showing how changes in the latent space smoothness affect both likelihood-derived PPL and actual generated tokens. The results demonstrate a structural gap between likelihood estimation and generation quality, where lower PPL does not necessarily lead to better generation, indicating that generation success depends more on reaching semantically valid latent regions than on precise local probability calibration. Lower likelihood-derived PPL does not guarantee better generation quality, as seen in the mismatch between PPL values and generated tokens across different VAE logSNR settings. The generated tokens vary significantly under different VAE logSNR conditions, with some settings producing semantically plausible outputs while others generate incorrect or nonsensical continuations. The results support the idea that generation quality is more closely tied to the semantic smoothness of the latent space rather than the probability-space smoothness shaped by the VAE logSNR.
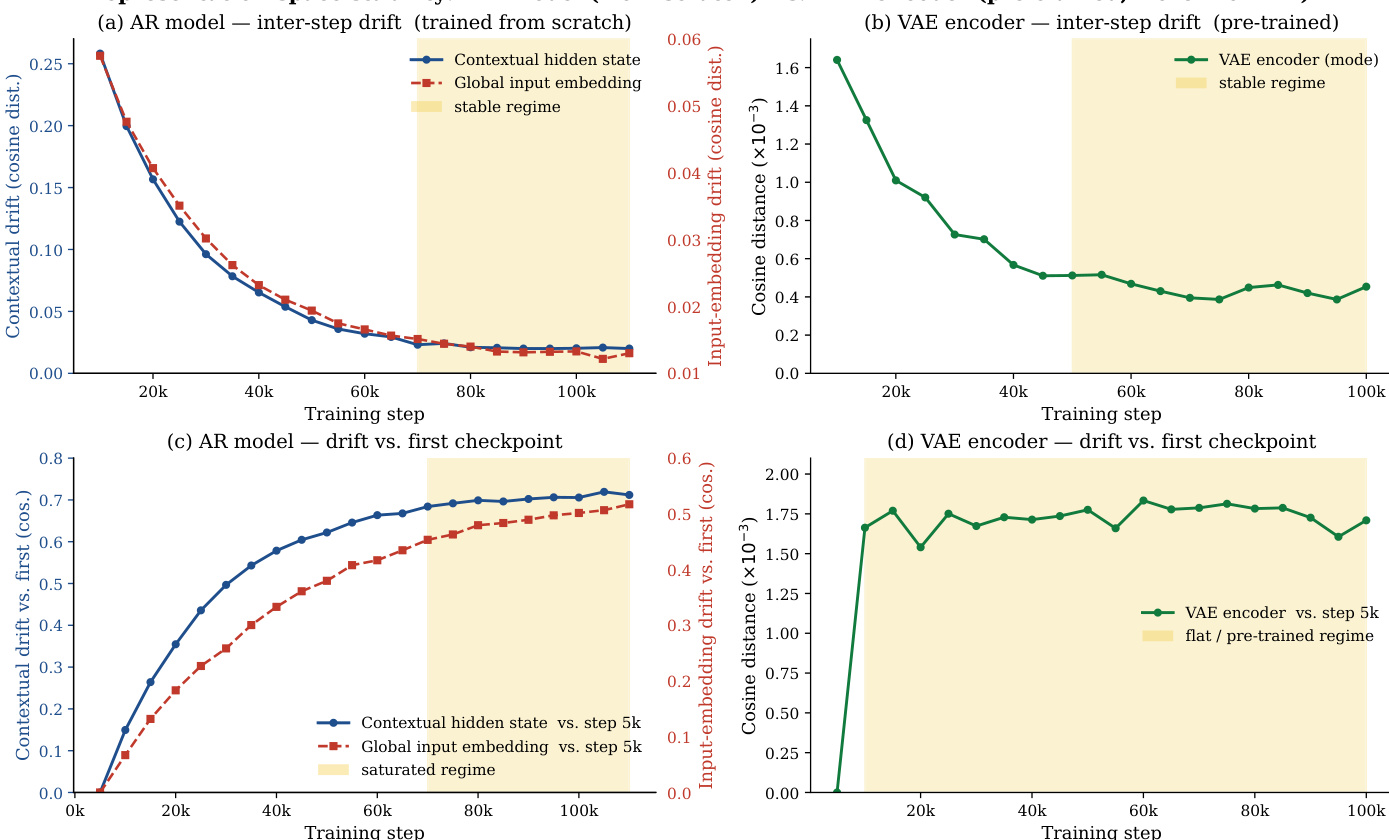
The authors analyze the drift of optimal timeshifts in the latent space of Cola DLM as the latent dimension changes, observing a systematic shift toward larger values with increasing dimensionality. This trend is consistent across multiple semantic metrics and aligns with theoretical predictions, suggesting the presence of shared global semantic structures. The results also show that the optimal timeshift stabilizes after a certain training point, with different regimes indicating the transition from initial learning to a stable phase. The optimal timeshift systematically drifts toward larger values as the latent dimension increases, supporting the existence of shared global semantic structures. The drift trend is consistent across multiple semantic metrics, indicating it is not an artifact of any single task. The optimal timeshift stabilizes after a certain training point, with distinct regimes reflecting different phases of model learning.
The the the table compares different conditioning and padding strategies for the first generation block in Cola DLM, evaluating their impact on performance across multiple tasks. Clean condition repaint consistently achieves the highest performance, indicating that strong and persistent conditioning is more effective than partial noisy correction or positional layout alone. The results show that clean conditioning leads to significant improvements over other methods, especially on semantic tasks like LAMBADA and SIQA. Clean condition repaint outperforms all other conditioning strategies across all tasks, indicating its effectiveness for maintaining prompt-conditioned regions during generation. Partial repaint strategies are substantially weaker, and reducing the fraction of the denoising trajectory that receives guidance further degrades performance. Left and right padding strategies are stronger than partial repaint but remain inferior to clean conditioning, suggesting that positional layout alone is insufficient for stable denoising.

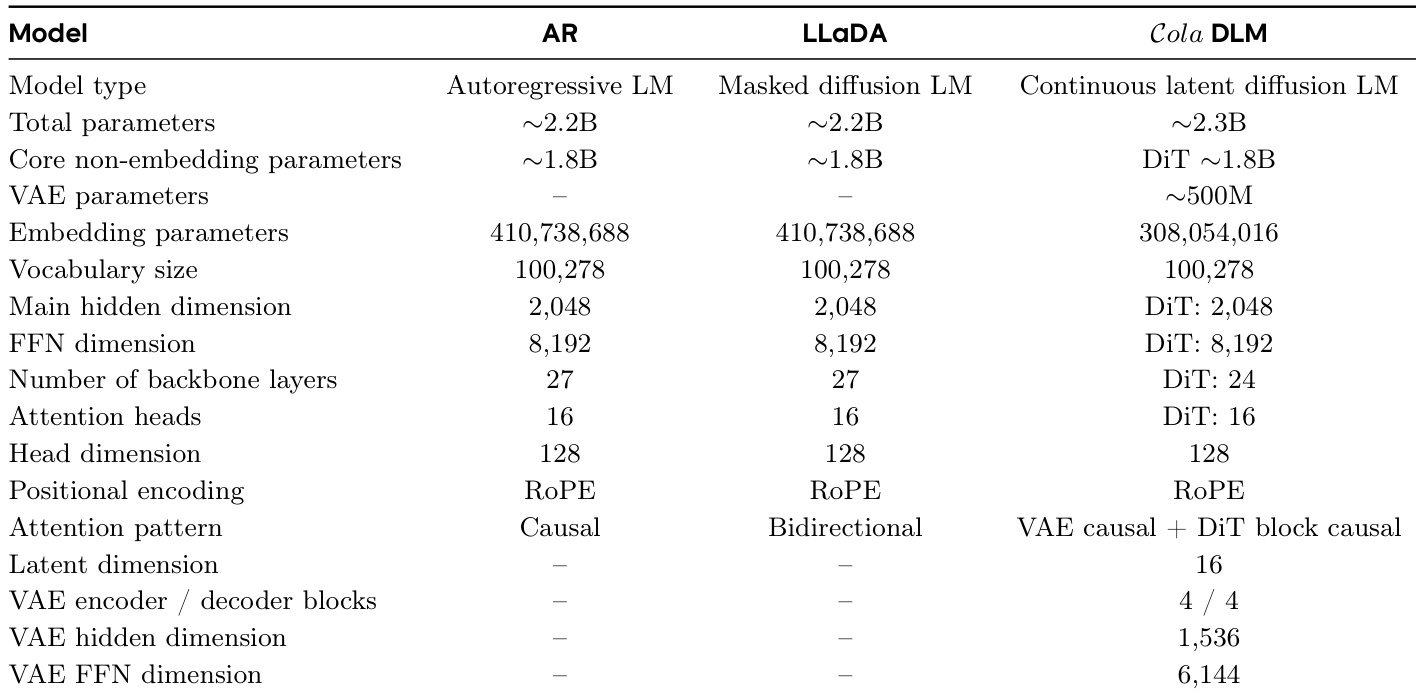
The the the table compares the architectural details of three language modeling approaches: autoregressive LM (AR), masked diffusion LM (LLaDA), and continuous latent diffusion LM (Cola DLM). Cola DLM features a distinct architecture with a VAE and DiT backbone, resulting in a larger total parameter count compared to the other models, while sharing core backbone parameters with them. The model uses a continuous latent space with a specific causal attention pattern and a defined latent dimension. Cola DLM has a larger total parameter count than AR and LLaDA due to the inclusion of a VAE component. Cola DLM uses a continuous latent space with a specific causal attention pattern and a defined latent dimension. AR and LLaDA share similar backbone architectures, while Cola DLM introduces a VAE and DiT backbone with different parameter configurations.
The experiments evaluate Cola DLM across varying VAE logSNR configurations, generation quality metrics, latent space dynamics, conditioning strategies, and architectural baselines to validate denoising calibration, generation fidelity, and structural coherence. Results demonstrate that learnable logSNR settings consistently outperform fixed alternatives and scale effectively with compute, while actual generation quality relies on semantic latent space smoothness rather than precise probability calibration. Additionally, optimal timeshifts systematically drift with latent dimensionality to reveal shared global semantic structures, and strong persistent conditioning proves essential for maintaining prompt fidelity during generation. Together, these qualitative outcomes confirm that the continuous latent diffusion architecture provides a stable and semantically robust framework for next-token prediction.