Command Palette
Search for a command to run...
리스트 와이즈 정책 최적화: LLM 응답 심플렉스에서의 목표 투영으로서 그룹 기반 RLVR
리스트 와이즈 정책 최적화: LLM 응답 심플렉스에서의 목표 투영으로서 그룹 기반 RLVR
초록
검증 가능한 보상 강화 학습(Reinforcement Learning with Verifiable Rewards, RLVR)은 대규모 언어 모델(LLMs)의 사후 학습(Post-training) 단계에서 추론 능력을 고취하기 위한 표준적인 접근 방식으로 자리 잡았습니다. 기존 기법들 중에서는 그룹 기반 정책 경사(Group-based Policy Gradient)가 널리 사용되며, 이는 각 프롬프트당 응답 그룹을 샘플링하고, 그룹 내 상대적 이익 신호(Relative Advantage Signals)를 통해 정책을 업데이트합니다. 본 연구는 이러한 최적화 전략들이 공통적인 기하학적 구조를 공유함을 드러냅니다. 즉, 각 방법은 응답 심플렉스(Response Simplex) 상의 목표 분포를 암묵적으로 정의하고, 1차 근사(First-order Approximation)를 통해 이를 향해 투영(Projection)합니다.이러한 통찰을 바탕으로, 본 논문에서는 Listwise Policy Optimization(LPO)을 제안합니다. LPO는 목표 분포에 대한 명시적 투영을 수행하며, 이를 위해 근접 강화 학습 목표 함수(Proximal RL Objective)를 응답 심플렉스에 제한하여 암묵적 목표의 정체를 규명하고, 정확한 발산 최소화(Divergence Minimization)를 통해 정책을 투영합니다. 이 프레임워크는 (i) 유계(Bounded), 영합(Zero-sum), 자가 수정(Self-correcting) 특성을 가진 투영 기울기(Projection Gradients)를 통해 리스트순(Listwise) 목표 함수의 단조 증가(Monotonic Improvement)를 제공하고, (ii) 분리된 투영 단계를 통해 서로 다른 구조적 특성을 지닌 다양한 발산 함수 선택의 유연성을 보장합니다. 다양한 추론 작업 및 LLM 백본에서 LPO는 동일한 목표 함수 하에서 일반적인 정책 경사 베이스라인 대비 학습 성능을 지속적으로 향상시키며, 최적화의 안정성과 응답 다양성을 본질적으로 유지합니다.
One-sentence Summary
The authors propose Listwise Policy Optimization (LPO), a reinforcement learning framework that explicitly executes target-projection on the LLM response simplex via exact divergence minimization to address the implicit first-order approximations of prior group-based methods, consistently improving training performance over policy gradient baselines on diverse reasoning tasks while preserving optimization stability and response diversity.
Key Contributions
- This work establishes a unifying geometric perspective by demonstrating that group-based policy gradient methods for reinforcement learning with verifiable rewards implicitly perform approximate target-projections on the response simplex.
- Listwise Policy Optimization (LPO) explicitly decouples target construction from policy projection by restricting the proximal reinforcement learning objective to sampled responses and performing exact divergence minimization on the response simplex.
- Evaluations across logic, mathematics, programming, and multi-modal reasoning tasks demonstrate that LPO consistently improves training performance over standard policy gradient baselines while preserving optimization stability and response diversity.
Introduction
Reinforcement learning with verifiable rewards has emerged as a critical post-training strategy for boosting the reasoning capabilities of large language models on complex problem-solving tasks. Group-based paradigms like GRPO dominate this space by sampling multiple responses per prompt and updating policies through relative advantage scoring. However, these approaches rely on empirical normalization techniques that obscure the underlying optimization dynamics, often leading to training instability and high gradient variance due to their reliance on implicit approximations. The authors leverage a unified geometric perspective to reveal that group-based policy gradients implicitly construct reward-weighted target distributions over a finite response simplex. Building on this insight, they introduce Listwise Policy Optimization, an explicit target-projection framework that decouples target construction from divergence minimization. By directly optimizing on the simplex, the method generates bounded, self-correcting gradients that ensure stable training, reduce variance, and guarantee monotonic reward improvement across diverse reasoning benchmarks.
Dataset
-
Dataset Composition and Sources The authors assemble a domain-specific reasoning corpus drawn from four established open-source benchmarks hosted on Hugging Face. The collection spans logical arithmetic, mathematics, code generation, and spatial geometry, providing a structured foundation for model training and evaluation.
-
Subset Details and Filtering Rules
- Logical Reasoning: 2,000 problems sampled from Countdown 34, filtered to include questions with either three or four source integers.
- Mathematics: 7,500 competition-level problems from MATH, supplemented by approximately 53,000 high-quality reasoning tasks from Polaris for extended training runs.
- Programming: 25,300 code generation tasks sourced primarily from programming competitions in the PRIME dataset.
- Geometry: 2,100 spatial reasoning problems from Geometry3k, each paired with a diagram and a natural language query.
-
Training Usage and Evaluation Processing The models are trained on these curated domain splits rather than a fixed mixture, with performance tracked across dedicated evaluation sets. The authors generate multiple independent responses per prompt to compute Pass@1 and domain-specific Pass@k metrics. Sampling rates are calibrated to benchmark difficulty: 64 responses for Countdown, 32 for AIME and AMC, 16 for Geometry3k, 8 for PRIME code, 4 for Minerva Math, and 1 for MATH500 and OlympiadBench. Training curves reflect the averaged performance across these evaluation suites.
-
Formatting Constraints and Reward Processing Instead of cropping, the authors enforce strict structural formatting to standardize model outputs. All prompts require an internal reasoning monologue enclosed in
<think>tags, followed by a final answer wrapped in domain-specific markers such as<answer>or\boxed{}. Reward functions are customized per domain: mathematics and programming rely on binary accuracy or test-case pass rates, while logical reasoning and geometry use a hybrid reward that awards a partial score (0.1) for correct structural formatting even when the final answer is incorrect.
Method
The authors propose Listwise Policy Optimization (LPO), a framework that reformulates reinforcement learning with verifiable rewards (RLVR) for large language models (LLMs) by explicitly conducting target-projection on the response simplex. This approach contrasts with existing group-based policy gradient methods, which implicitly approximate this projection. The core architecture of LPO is structured around two decoupled steps: target construction and policy projection. As shown in the figure below, the process begins with a prompt x, from which a behavior policy πb generates a group of K responses {y1,…,yK}. These responses are evaluated by a verifier to produce a reward vector R=[R1,…,RK]⊤. 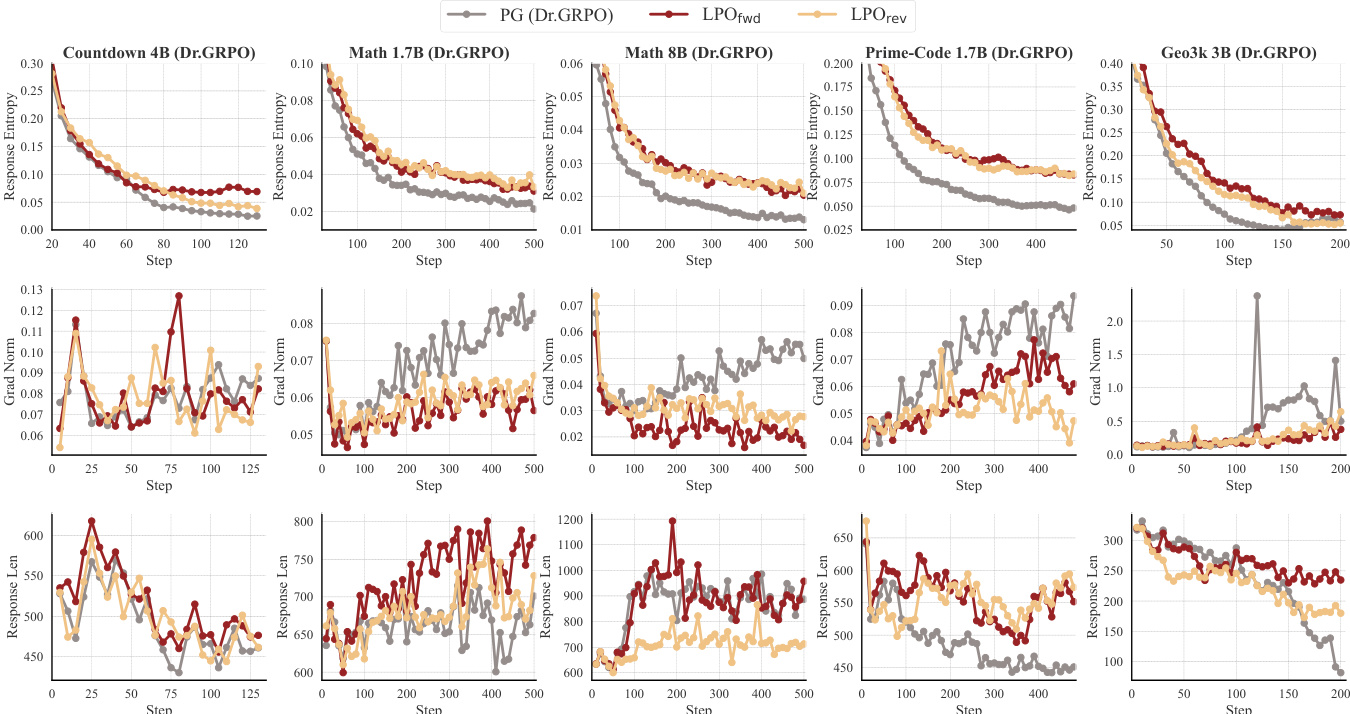
The first step, target construction, involves defining a target distribution w∗ on the K-dimensional response simplex ΔK−1. This target is derived from a local proximal objective that maximizes the expected reward while maintaining a trust region around the pre-update policy. Theorem 1 establishes that the optimal target distribution is given by wk∗=softmax(ϕ)k, where the logit ϕk=Rk/τ+st,k, with st,k being the logit offset from the pre-update policy πt and τ a temperature parameter. This formulation explicitly re-weights the baseline policy's listwise distribution Pt toward high-reward responses, with τ controlling the sharpness of the target.
The second step, policy projection, involves updating the policy model πθ to minimize a chosen divergence between the current listwise distribution Pθ and the constructed target w∗. The framework is flexible, allowing the selection of different divergences. For instance, minimizing the forward KL divergence DKL(w∗∥Pθ) yields a gradient update where the coefficient for response yk is ckfwd=Pθ,k−wk∗. Similarly, minimizing the reverse KL divergence DKL(Pθ∥w∗) results in a coefficient ckrev=Pθ,k(dk−dˉ), where dk is the logit gap and dˉ is its expectation under Pθ. This decoupling of target construction and projection enables a rich design space for divergence selection, which is not accessible in traditional policy gradient methods. 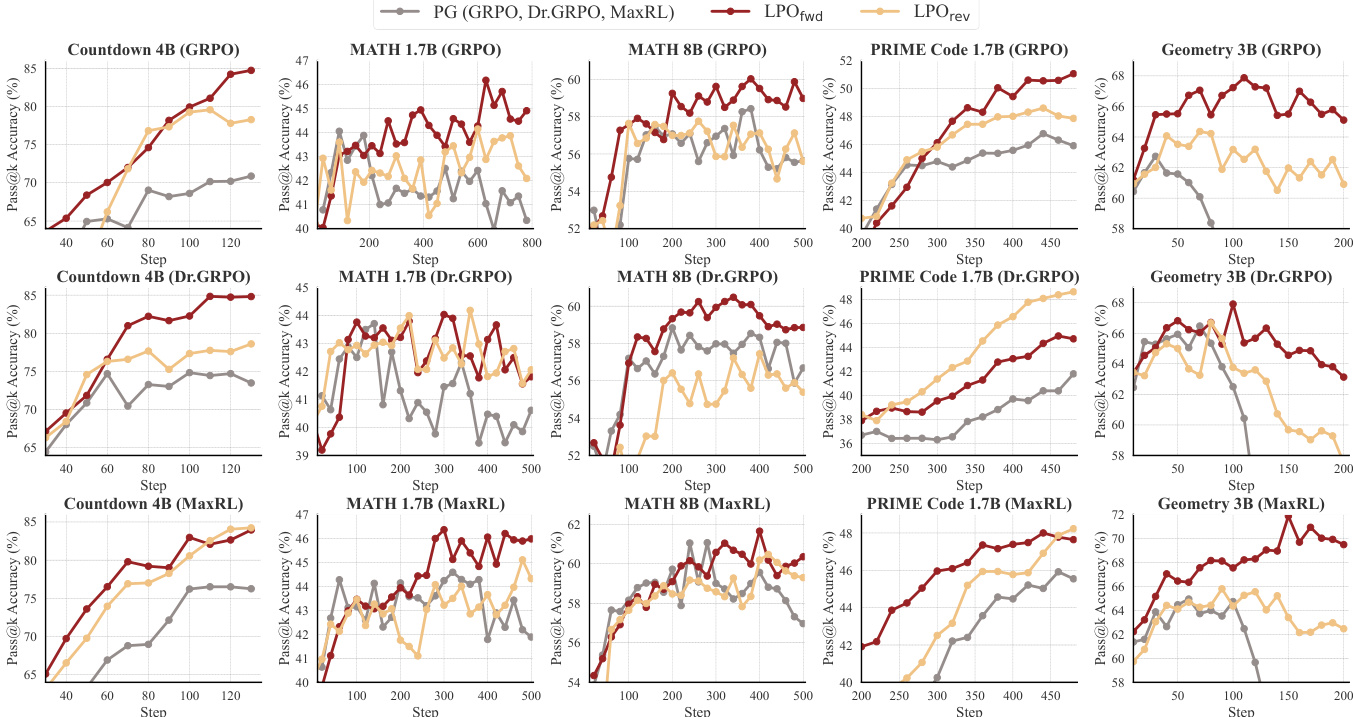
The LPO framework provides several key theoretical and practical benefits. Theorem 2 establishes a performance improvement bound, showing that the expected reward strictly improves with perfect projection, as the target gain is the Jeffreys divergence. The gradient coefficients for forward KL, as detailed in Corollary 1, are bounded, zero-sum, and self-correcting, which enhances optimization stability and acts as a built-in control variate. The zero-sum property, a direct consequence of operating on the probability simplex, is a fundamental structural difference from pointwise projection methods, which lack this balancing mechanism. The framework is also practically implementable with no additional computational cost compared to standard group-based RL algorithms, as summarized in Algorithm 1. 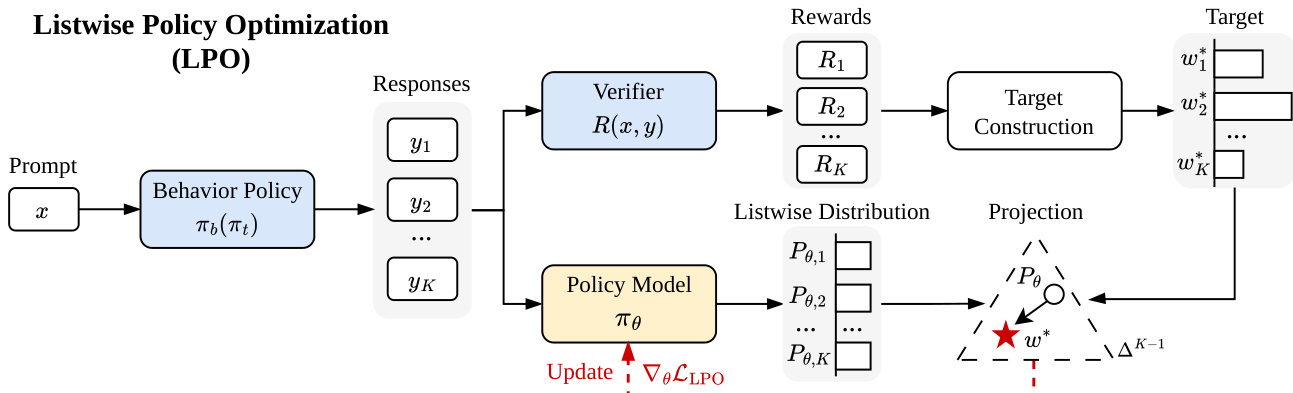
Experiment
The study evaluates LPO across logic, mathematics, programming, and multi-modal geometry tasks using diverse LLM families and sizes, comparing it against group-based policy gradient baselines under controlled temperature settings. Experimental results demonstrate that LPO consistently improves training efficiency and reasoning performance while maintaining higher response entropy, stable gradient norms, and extended reasoning chains. Ablation studies confirm that the explicit listwise projection mechanism is essential for variance reduction and optimization stability, with forward and reverse variants offering distinct advantages in diversity preservation and sample efficiency. Overall, the findings establish LPO as a robust, model-agnostic framework that enhances reinforcement learning for reasoning by decoupling exact target fitting from heuristic temperature tuning.
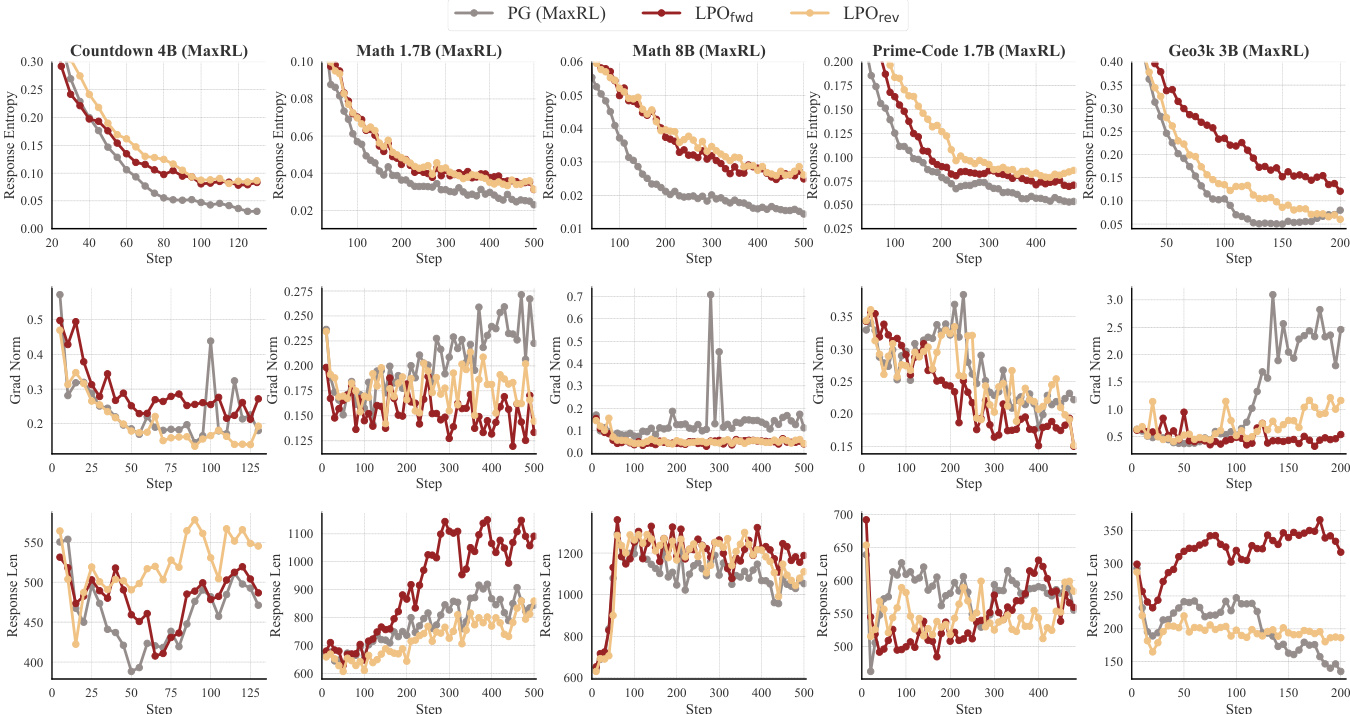
The authors evaluate LPO variants against group-based policy gradient baselines across multiple reasoning tasks and model architectures. Results show that LPO consistently outperforms baselines in training efficiency and performance, with both variants demonstrating more stable optimization dynamics, higher response entropy, and longer response lengths compared to PG methods. The improvements are consistent across different model families and task domains, indicating the robustness of the listwise projection framework. LPO variants consistently outperform group-based policy gradient baselines across all tested tasks and model sizes. LPO maintains higher response entropy and more stable gradient norms, indicating improved exploration and optimization stability. LPO generates longer responses and shows superior performance in Pass@k evaluations, particularly at smaller group sizes.
The authors evaluate LPO against group-based policy gradient baselines across multiple reasoning domains and model sizes, showing consistent improvements in training performance. LPO variants demonstrate more stable optimization dynamics, higher response diversity, and longer reasoning chains compared to baselines, with gains observed across different model families and task types. The results highlight the benefits of exact listwise projection for improving both efficiency and robustness in reinforcement learning for reasoning tasks. LPO consistently outperforms group-based policy gradient baselines across various reasoning tasks and model sizes. LPO variants maintain higher response entropy and exhibit more stable gradient norms, leading to improved exploration and optimization stability. LPO shows robust performance gains across different model families and training setups, indicating its generalizability and effectiveness as a model-agnostic approach.
The authors compare LPO variants against group-based policy gradient methods across multiple reasoning tasks and model families, demonstrating consistent performance improvements. Results show that LPO maintains higher response entropy, more stable gradient norms, and generates longer responses compared to baselines, indicating enhanced exploration and optimization stability. The framework exhibits robustness across different model architectures and scales effectively with larger models and datasets. LPO variants consistently outperform group-based policy gradient baselines across diverse reasoning tasks and model families. LPO maintains higher response entropy and more stable gradient norms, leading to improved exploration and optimization stability. The framework scales effectively with larger models and shows robust performance gains across different model architectures.

The authors evaluate LPO variants against group-based policy gradient baselines across multiple reasoning tasks and model sizes, observing consistent performance improvements for LPO in terms of training efficiency and accuracy. The results show that LPO maintains higher response entropy, more stable gradient norms, and generates longer responses, indicating better exploration and optimization stability. These benefits are robust across different model families and task domains, with LPO variants outperforming baselines in most settings. LPO consistently outperforms group-based policy gradient baselines across various reasoning tasks and model sizes. LPO variants maintain higher response entropy and more stable gradient norms, indicating improved exploration and optimization stability. LPO demonstrates robust performance gains across different model families and task domains, showing generalizability and scalability.
The authors evaluate LPO variants against group-based policy gradient baselines across multiple LLMs and reasoning tasks, observing consistent performance improvements in both Pass@1 and Pass@k metrics. LPO demonstrates superior training efficiency and stability, with higher response entropy and more stable gradient norms, indicating better exploration and optimization dynamics. The results show that LPO maintains its advantages across different model families and task domains, highlighting its generalizability and robustness. LPO variants consistently outperform group-based PG baselines across all evaluated tasks and model sizes. LPO maintains higher response entropy and more stable gradient norms, indicating better exploration and optimization stability. LPO shows robust performance gains across diverse LLM families and task domains, demonstrating strong generalizability.
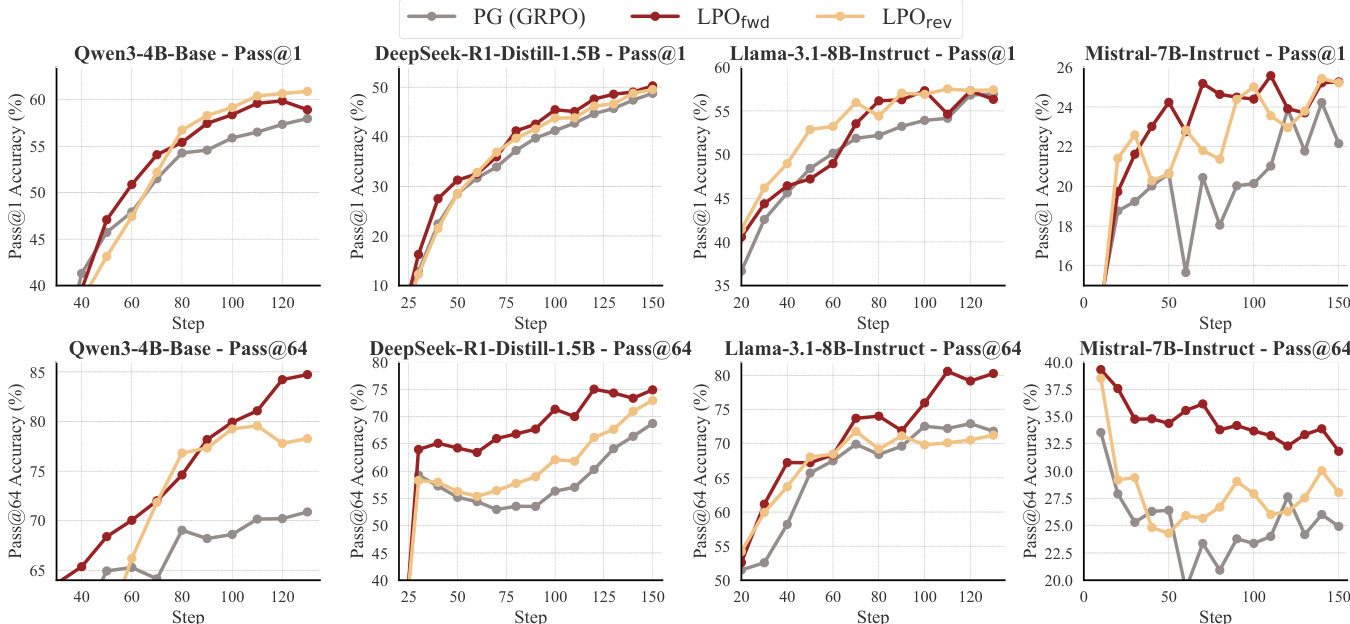
The experiments evaluate listwise projection optimization variants against group-based policy gradient baselines across diverse reasoning tasks and model architectures to validate the framework's effectiveness in reinforcement learning for complex reasoning. Results consistently demonstrate that the proposed method yields superior training efficiency and accuracy while maintaining higher response diversity and more stable optimization dynamics. These qualitative improvements indicate enhanced exploration capabilities and robust gradient behavior across varying model scales and task domains. Ultimately, the findings confirm the approach as a highly generalizable and model-agnostic solution for reasoning tasks.