Command Palette
Search for a command to run...
VibeServe: AI 에이전트가 맞춤형 LLM 서빙 시스템을 구축할 수 있는가?
VibeServe: AI 에이전트가 맞춤형 LLM 서빙 시스템을 구축할 수 있는가?
Keisuke Kamahori Shihang Li Simon Peter Baris Kasikci
초록
수년 동안 우리는 LLM 서빙 시스템을 기타 주요 인프라와 동일하게 구축해 왔습니다. 즉, 모든 모델과 워크로드를 지원하기 위해 설계된 단일 범용 스택으로, 수년간의 엔지니어링 노력을 통해 세밀하게 튜닝되어 왔습니다. 본 논문에서는 이러한 기존 관념과 정반대의 접근을 취합니다. 즉, 다양한 사용 시나리오에 맞는 전용 서빙 시스템을 자동으로 생성하는 다중 에이전트 루프(multi-agent loop)를 제안합니다. 우리는 전체 LLM 서빙 스택을 종단간(end-to-end)으로 생성하는 첫 번째 에이전틱 루프(agentic loop)인 VibeServe를 제안합니다. VibeServe는 외부 루프(outer loop)를 통해 시스템 설계 탐색을 계획하고 추적하며, 내부 루프(inner loop)를 통해 후보안을 구현하고 정확성을 검증하며 대상 benchmark에서 성능을 측정합니다. 기존 스택이 극도로 최적화된 표준 배포 환경에서도 VibeServe는 vLLM과 경쟁력 있는 성능을 보여, 생성 시점의 전문화(generation-time specialization)가 성능 저하를 초래할 필요 없음을 입증합니다. 더욱 흥미로운 점은, VibeServe가 비표준 시나리오에서 기존 시스템을 능가한다는 것입니다. 이는 비표준 모델 아키텍처, 워크로드 지식, 하드웨어 특화 최적화와 관련된 여섯 가지 시나리오에서 범용 시스템이 놓치기 쉬운 기회를 VibeServe가 적극 활용했기 때문입니다. 이러한 결과들은 인프라 소프트웨어의 설계 공간에서 서로 다른 지점을 시사합니다. 즉, 실행 시간의 범용성(runtime generality)보다 생성 시점의 전문화(generation-time specialization)가 더 유의미할 수 있다는 점입니다.
One-sentence Summary
VibeServe is the first agentic loop that generates entire bespoke LLM serving stacks end-to-end by employing an outer loop for design planning and an inner loop for implementation and evaluation, prioritizing generation-time specialization over runtime generality to remain competitive with vLLM in standard deployments while outperforming existing systems in six scenarios involving non-standard model architectures, workload knowledge, and hardware-specific optimizations.
Key Contributions
- The paper introduces VibeServe, the first agentic loop that generates entire LLM serving stacks end-to-end for different usage scenarios. It uses an outer loop to plan system designs and an inner loop to implement candidates while checking correctness and measuring performance.
- The architecture employs role-based agents that collaborate on a shared workspace using a skills library of serving-systems knowledge and direct profiler access. These agents fold performance analysis into every implementation change to target performant code during the synthesis process.
- Experiments demonstrate that the method remains competitive with vLLM in standard deployment settings while outperforming existing systems in six non-standard scenarios. Two of these specific scenarios involving non-standard model architectures and hardware cannot run on any generic stack.
Introduction
Large language model serving infrastructure typically relies on general-purpose stacks that are manually optimized for mainstream workloads. This one-size-fits-all approach incurs a performance tax on emerging model architectures and specialized hardware where standard abstractions fail. Existing agentic systems address optimization at a granular level but struggle to coordinate end-to-end system synthesis due to context window limitations and state drift. The authors propose VibeServe, a multi-agent framework that automatically generates bespoke serving systems tailored to specific deployment targets. Their design employs an outer planning loop and an inner implementation loop to manage long-horizon tasks without losing context. This approach achieves parity with hand-tuned baselines on standard deployments while delivering significant speedups in non-standard scenarios involving complex models or unconventional hardware.
Method
The authors propose VibeServe, a framework that generates a bespoke serving system specialized to a user-specified model, hardware platform, and workload. Rather than relying on general-purpose runtimes to cover every case, the system iteratively produces an end-to-end serving system from a small set of user-provided artifacts.
As illustrated in the framework diagram, this approach contrasts with generic serving today, where a single runtime attempts to cover common cases across various workloads and hardware. VibeServe instead creates one bespoke serving system per target, optimizing for the specific intersection of workload, model, and hardware.
The detailed architecture, shown in the figure below, decomposes the generation process into an outer planning loop and an inner implementation loop. The system accepts user inputs including model weights, reference code, accuracy-checking scripts, and benchmark metrics. These inputs define the per-target contract that parameterizes the framework.
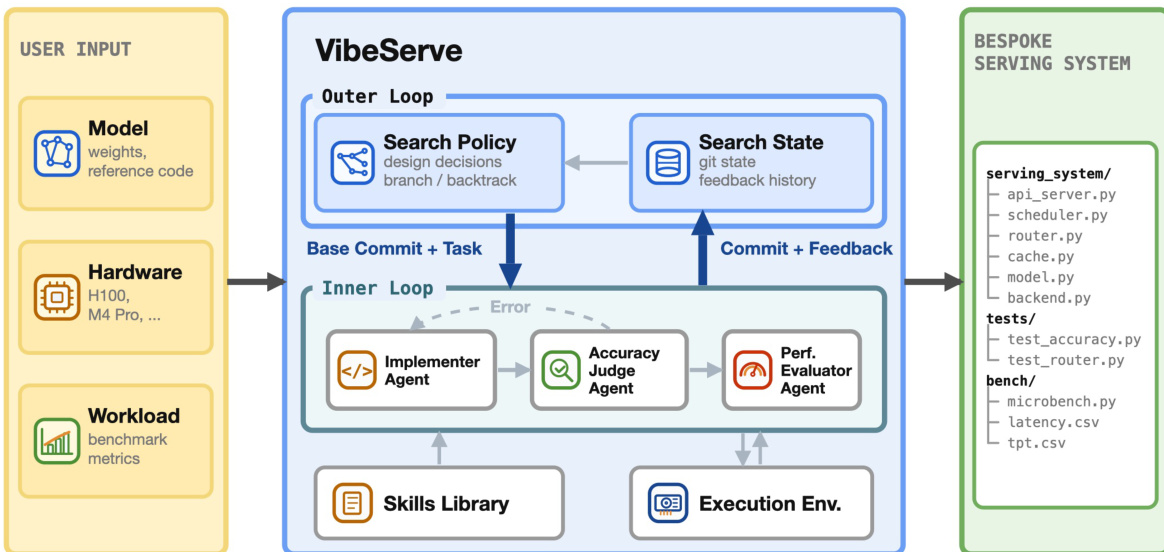
The outer loop manages the search policy and search state. It reads prior state from a git repository, dispatches a single task to the inner loop per round, and receives the resulting commit with performance metrics. This loop supports coordination mechanisms such as reverting to earlier checkpoints if a later round passes correctness but regresses on the headline metric. Policies implemented include evolutionary search and an issue-tracker approach that maintains a backlog of structured optimization tasks.
Within each round, the inner loop employs multiple agents to separate code edit proposals from validation. The Implementer agent produces and revises the candidate serving system in an isolated workspace. This workspace mounts user artifacts as read-only and exposes the target execution environment. Once the Implementer produces a build, the Accuracy Judge agent gates the overall correctness. It verifies end-to-end model accuracy against the reference implementation and checks for reward-hacking patterns, such as schema-only synthesis or bypassing model inference.
If the implementation passes correctness checks, the Performance Evaluator profiles the system. It starts with end-to-end performance on the user-provided benchmark and drills down with platform-specific profilers when finer measurements are needed. The Evaluator generates performance hints for subsequent rounds, which are fed back to the outer loop.
To support these agents, VibeServe provides an extensible skills library. This library contains operational knowledge organized by abstraction layers, such as model architectures, serving algorithms, and hardware platforms. Agents retrieve focused guidance from this library, allowing them to apply techniques like continuous batching or utilize specific libraries like FlashInfer without reimplementing kernels.
Experiment
The evaluation assesses VibeServe across six scenarios spanning diverse workload patterns, model architectures, and hardware configurations to determine if generated systems match the performance of human engineered systems or address niche limitations. In standard serving environments, the system achieves parity with established frameworks while autonomously optimizing throughput and latency. For specialized cases such as hybrid architectures and local constrained decoding, VibeServe delivers substantial performance gains by implementing optimizations that general purpose systems lack, validating that bespoke systems can effectively handle complex use cases where existing infrastructure falls short.
The the the table details the resource consumption of the VibeServe agent across six diverse serving scenarios, highlighting the distribution of work among the Orchestrator, Implementer, Judge, and Performance Evaluator roles. The Implementer role consistently consumes the largest portion of the total duration, while the Orchestrator requires the least time. Total agent execution time varies significantly by scenario, with the standard Llama-3.1 serving task demanding the most resources and JSON constrained decoding being the most efficient. The Implementer role dominates the execution time, typically accounting for the largest share of duration across all scenarios. Scenario A requires the highest number of calls and total duration, reflecting the difficulty of optimizing a mature setting. The Orchestrator role consistently maintains the lowest share of time and call volume across all experiments.

The evaluation assesses the VibeServe agent's resource consumption across six diverse serving scenarios to determine workload distribution among the Orchestrator, Implementer, Judge, and Performance Evaluator roles. Results demonstrate that the Implementer role consistently consumes the largest portion of execution time and call volume, whereas the Orchestrator maintains the lowest share across all scenarios. Overall, the experiments highlight that total agent efficiency varies by task complexity, with standard Llama-3.1 serving requiring the most resources while JSON constrained decoding proves the most efficient.