Command Palette
Search for a command to run...
의미적 유사성을 넘어서: 직접 코퍼스 상호작용을 통한 에이전트 검색을 위한 검색 방식 재고찰
의미적 유사성을 넘어서: 직접 코퍼스 상호작용을 통한 에이전트 검색을 위한 검색 방식 재고찰
초록
현대 검색 시스템은 어휘 기반이든 의미 기반이든, 추론 전에 단일 상위-k(top-k) 검색 단계로 접근 방식을 압축하는 고정된 유사성 인터페이스를 통해 코퍼스를 노출합니다. 이러한 추상화는 효율적이지만, 에이전트 기반 검색(agentic search)에서는 병목 현상으로 작용합니다. 정확한 어휘 제약 조건, 희소한 단서들의 결합, 지역적 맥락 검증, 그리고 다단계 가설 정교화 과정은 기성 오프더 shelf(retriever)를 호출하는 방식으로 구현하기 어렵습니다. 또한 조기에 필터링된 증거는 이후 강력한 추론 단계에서도 복원할 수 없습니다. 에이전트 작업은 이러한 한계를 더욱 악화시키는데, 이는 에이전트가 중간 개체 발견, 약한 단서 결합, 부분적 증거 관찰 후 계획 수정 등 여러 단계를 조율해야 하기 때문입니다. 이러한 한계를 극복하기 위해, 본 연구에서는 일반적인 터미널 도구(예: grep, 파일 읽기, 셸 명령어, 경량 스크립트)를 사용하여 임베딩 모델, 벡터 인덱스 또는 검색 API 없이 원시 코퍼스를 직접 탐색하는 직접 코퍼스 상호작용(Direct Corpus Interaction, DCI)을 연구합니다. 이 접근 방식은 오프라인 인덱싱이 필요 없으며 진화하는 지역 코퍼스에도 자연스럽게 적응합니다. 정보 검색(IR) 벤치마크와 에지투엔드(end-to-end) 에이전트 기반 검색 작업에서, 이러한 단순한 설정은 여러 BRIGHT 및 BEIR 데이터셋에서 강력한 스파스(sparse), 딘스(dense), 리랭킹(reranking) 기반 접근법보다 현저히 우수한 성능을 보이며, BrowseComp-Plus 및 다중 홉(multi-hop) QA 작업에서 기존 의미 기반 검색기를 사용하지 않고도 높은 정확도를 달성했습니다. 본 결과에 따르면, 언어 에이전트의 성능이 향상됨에 따라 검색의 질은 추론 능력뿐만 아니라 모델이 코퍼스와 상호작용하는 인터페이스의 해상도(resolution)에도 좌우되며, DCI는 에이전트 기반 검색을 위해 더 넓은 인터페이스 설계 공간을 열어줍니다.
One-sentence Summary
The authors propose Direct Corpus Interaction, an agentic search framework that replaces fixed similarity interfaces with direct terminal-based queries against raw corpora, utilizing general-purpose terminal tools instead of vector embeddings to enable iterative multi-step reasoning, recover early-filtered evidence, and adapt to evolving local datasets without requiring offline indexing.
Key Contributions
- This paper formalizes direct corpus interaction (DCI) as an alternative retrieval paradigm that replaces fixed top-k similarity interfaces with direct agent access to raw corpora using general-purpose terminal tools such as grep and shell commands.
- Eliminating offline indexing requirements enables fine-grained pattern matching and precise evidence localization, allowing agents to iteratively verify clues and adapt to evolving local datasets.
- Evaluations across ranking-oriented information retrieval, multi-hop question answering, and end-to-end agentic search benchmarks demonstrate that DCI achieves competitive performance. Trajectory-level analyses reveal that this advantage stems from retrieval-interface resolution, which converts surfaced evidence into higher-value local inspection and compositional search steps.
Introduction
Retrieval-augmented pipelines typically compress corpus access into a fixed top-k retrieval step using sparse or dense similarity models before reasoning begins. This abstraction becomes a critical bottleneck for agentic search, as agents require exact lexical constraints, sparse clue conjunctions, and local context verification that standard retrievers cannot support without discarding potentially valuable evidence early in the process. The authors introduce Direct Corpus Interaction (DCI), a paradigm where agents bypass conventional retrieval APIs and interact directly with the raw corpus using general-purpose terminal tools like grep and shell commands. This approach removes the need for offline indexing or embedding models, enabling agents to compose flexible search operations for precise evidence localization and iterative refinement while outperforming strong baselines across multiple benchmarks.
Dataset
-
Dataset Composition and Sources The authors use a curated collection of closed and open-domain benchmarks to evaluate retrieval-augmented reasoning. The Agentic Search suite relies on BrowseComp-Plus, a fixed corpus derived from BrowseComp queries and augmented with human-verified supporting documents and mined hard negatives. The Knowledge-Intensive QA suite combines six established datasets: NQ and TriviaQA for single-hop factual retrieval, alongside Bamboogle, HotpotQA, 2WikiMultiHopQA, and MuSiQue for multi-hop sequential inference. The IR Ranking suite incorporates BRIGHT across four scientific domains and two subsets from the heterogeneous BEIR benchmark.
-
Key Details for Each Subset BrowseComp-Plus features complex, multi-document synthesis questions requiring deep evidence retrieval. The QA datasets range from Wikipedia-derived single-hop tasks to manually constructed multi-hop challenges that enforce exact inferential steps or provide annotated reasoning chains. BRIGHT provides domain-specific queries for Biology (103), Earth Science (116), Economics (103), and Robotics (101). The BEIR evaluation samples 50 queries each from ArguAna (1,406 total) and SciFact (300 total). The authors explicitly filter out ambiguous questions and time-sensitive cases to prevent corpus drift.
-
Data Usage and Processing The benchmark data serves exclusively as an offline evaluation suite rather than a training corpus. Retrieval baselines construct a fixed search index using the official BrowseComp corpus paired with BM25 and Qwen3-Embedding-8B via FAISS. For the DCI agent, the authors bypass indexing entirely and grant direct terminal access to the same document store. The BEIR subsets are downsampled to maintain consistent computational overhead across benchmarks.
-
Metadata Construction and Formatting Strategies The authors track document statistics using mean whitespace-split word length to standardize corpus comparisons. Retrieval protocols are enforced through structured system prompts that mandate parallel grep and bash searches, exhaustive keyword variation, and mandatory confidence scoring. Output formatting requires ranked document lists with full relative paths, inline citations, and step-by-step reasoning chains to ensure transparent evaluation of retrieval quality and final answer generation.
Method
The authors leverage a dual-paradigm framework for agentic search, contrasting retriever-mediated access with direct corpus interaction (DCI). In the retriever-mediated paradigm, the agent submits a query to a deployed retriever that accesses a pre-built corpus index, returning a ranked list of top-k snippets. The agent's observations are constrained to these snippets and document identifiers, with all evidence filtered through the retriever's scoring and ranking interface. This approach relies on a separate index-building process and limits the agent's control over the retrieval interface.
In contrast, the DCI paradigm, which is the focus of the proposed method, enables the agent to bypass the retriever and directly interact with the raw corpus using a general-purpose command-line interface (CLI). As shown in the framework diagram, the agent issues tool calls such as grep, rg, find, glob, read, and python scripts to perform exact or regular-expression matches, navigate the file system, and inspect local context around matches. The resulting observations are tool outputs, including matched spans with surrounding context, file paths, counts, and metadata, rather than a fixed-format ranked list. This direct access provides a higher-resolution search interface, allowing the agent to probe specific terms, open full files, and extract new entities or constraints to ground subsequent search actions.
To manage the accumulation of potentially large amounts of tool output over long-horizon trajectories, the DCI-Agent-Lite system incorporates a lightweight runtime context-management layer, visualized in the figure below. This layer is built around three mechanisms: Truncation caps the text from each tool call before reinserting it into the live working context, preserving that an observation occurred while limiting per-turn verbosity. Compaction is an in-memory, zero-LLM operation that clears the contents of older tool-result turns once accumulated tool output exceeds a configured threshold, replacing those turns with short placeholders that preserve the tool-call structure. Summarization is a higher-intervention strategy that, under additional context pressure, replaces compacted history with a model-generated summary while keeping the most recent context intact. 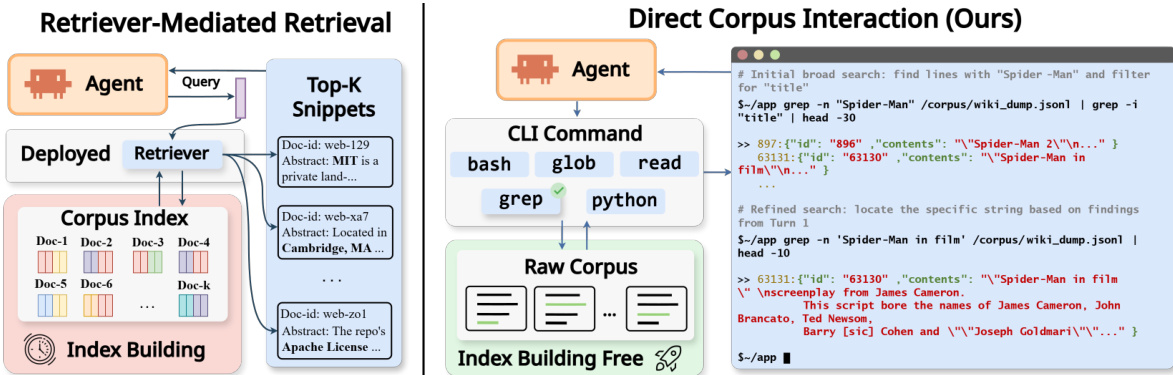 These mechanisms are implemented through a family of context-management policies, each enabling a different subset of these mechanisms with varying aggressiveness, allowing for controlled analysis of their impact on performance.
These mechanisms are implemented through a family of context-management policies, each enabling a different subset of these mechanisms with varying aggressiveness, allowing for controlled analysis of their impact on performance. 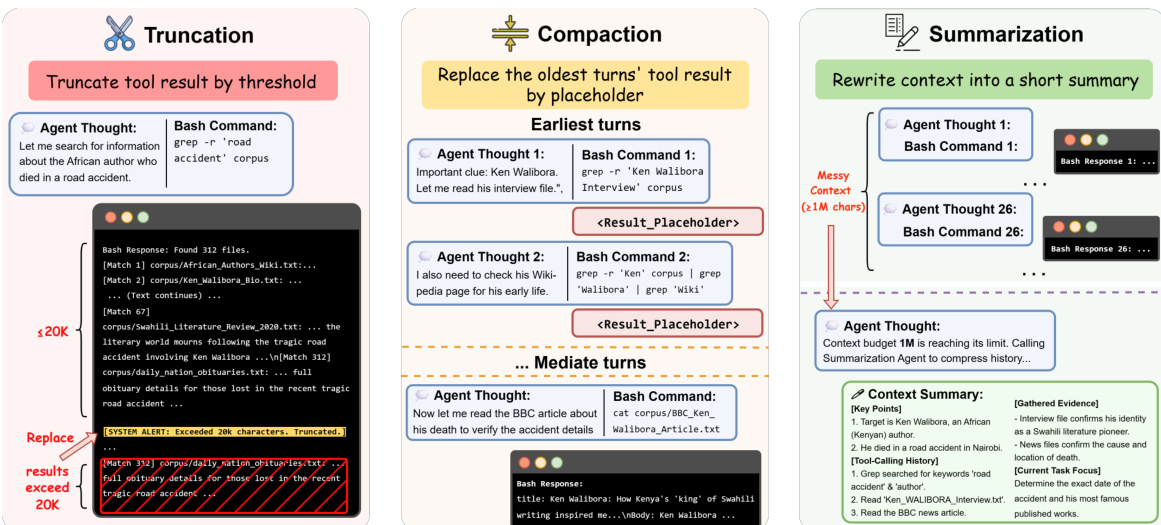
Experiment
The evaluation compares two DCI agent implementations against conventional retrieval baselines across agentic search, knowledge-intensive QA, and IR ranking benchmarks to validate the paradigm's overall effectiveness and operational mechanisms. Main results confirm that DCI consistently outperforms traditional pipelines in accuracy and cost efficiency by leveraging compositional bash interactions to iteratively narrow search spaces and verify precise evidence spans rather than relying on exhaustive document recall. Controlled ablations further validate that the approach trades broad corpus coverage for high-resolution local inspection, demonstrating strong scalability in search depth but significant degradation under extreme corpus breadth. Finally, tool and context management analyses reveal that minimal expressivity and selectively tuned compression policies capture most performance gains, underscoring DCI as a highly efficient direct corpus interaction framework.
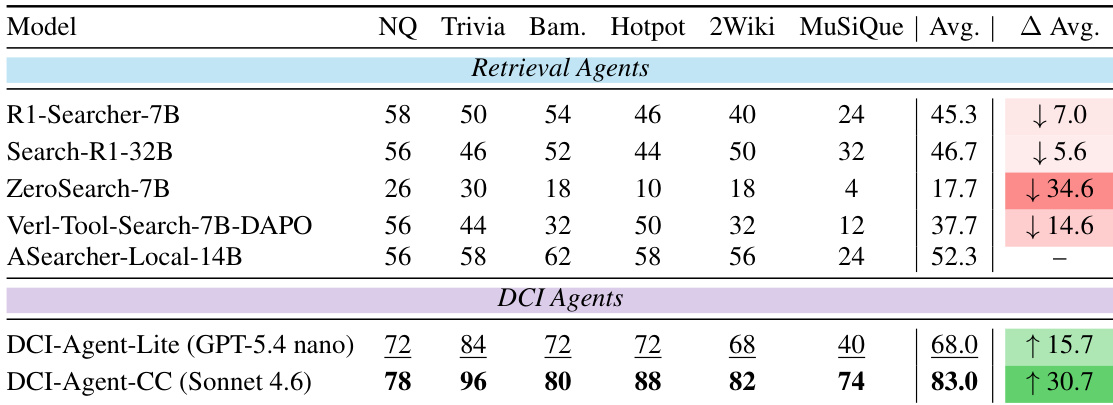
The authors compare DCI agents to retrieval-based baselines across knowledge-intensive QA tasks, showing that DCI agents achieve higher accuracy on multiple datasets. DCI-Agent-CC consistently outperforms all retrieval agents, while DCI-Agent-Lite also achieves competitive results despite using a minimal tool set. DCI agents significantly outperform retrieval-based baselines on knowledge-intensive QA tasks. DCI-Agent-CC achieves the highest accuracy across all evaluated datasets. DCI-Agent-Lite delivers strong performance with a minimal tool set, demonstrating efficiency and competitiveness.
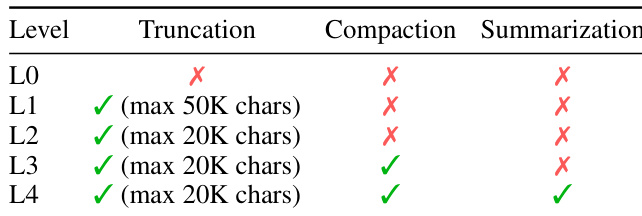
The authors evaluate different context-management policies for DCI-Agent-Lite by varying levels of truncation, compaction, and summarization. Results show that more aggressive context management does not consistently improve performance, and there is a non-monotonic relationship between policy intensity and accuracy, with an optimal balance achieved at intermediate levels. The best-performing policy combines truncation and compaction but not summarization. Context management policies exhibit a non-monotonic effect on performance, with intermediate levels outperforming both minimal and maximal strategies. The optimal policy combines truncation and compaction but does not include summarization. Higher context retention does not necessarily lead to better accuracy, indicating that selective forgetting can support sustained multi-step reasoning.
The authors evaluate DCI agents under two implementations, a minimal scaffold and a stronger one, across multiple benchmarks. Results show that DCI agents achieve high accuracy with fewer tools and lower cost compared to retrieval-based baselines, particularly in knowledge-intensive QA and information retrieval tasks. The minimal DCI-Agent-Lite variant performs competitively while using a constrained set of tools and maintaining cost efficiency. DCI agents achieve high accuracy with fewer tools and lower cost compared to retrieval-based baselines. DCI-Agent-Lite performs competitively on knowledge-intensive QA tasks despite using a minimal tool set and lower-cost model. The minimal DCI implementation outperforms retrieval agents in both accuracy and cost efficiency across multiple benchmarks.
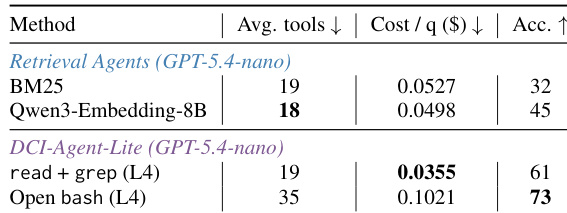
The authors evaluate two DCI agent implementations, a lightweight version and a stronger one, across multiple benchmarks including agentic search, knowledge-intensive QA, and IR ranking. Results show that both DCI agents achieve strong performance, with the stronger version outperforming retrieval-based baselines and the lightweight version offering a cost-efficient alternative. The lightweight agent achieves high accuracy at low cost, while the stronger agent demonstrates superior performance despite higher resource usage. DCI-Agent-CC achieves the highest accuracy among all evaluated agents, outperforming retrieval-based baselines and other strong models. DCI-Agent-Lite delivers strong accuracy at significantly lower cost, positioning it as a cost-efficient alternative. The lightweight DCI implementation achieves high performance with minimal tool usage, demonstrating effectiveness under strict budget constraints.
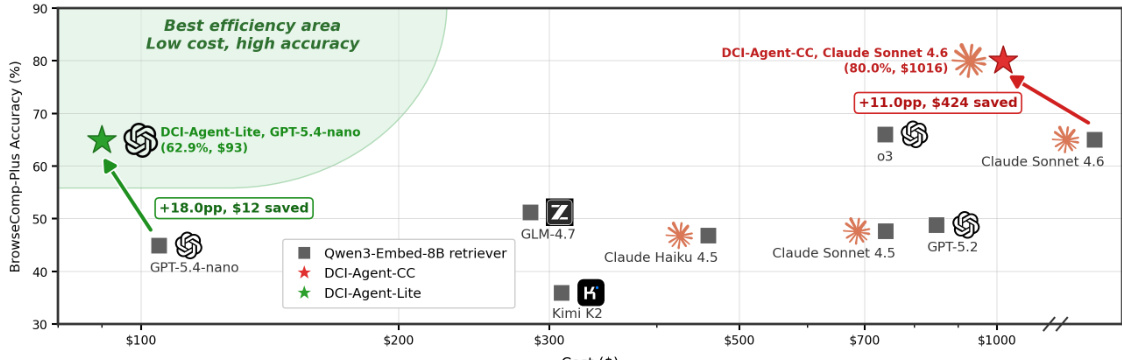
The authors compare DCI-Agent-Lite, a minimal terminal-based agent, with retrieval agents using conventional methods. DCI-Agent-Lite achieves higher accuracy and better localization while using more tools and incurring higher cost, indicating a trade-off between precision and efficiency. The results suggest that direct interaction with the corpus enables more effective evidence retrieval and reasoning compared to traditional retrieval approaches. DCI-Agent-Lite outperforms retrieval agents in accuracy and localization despite using more tools and higher cost. Direct interaction with the corpus leads to better evidence localization and higher accuracy compared to retrieval-based methods. The trade-off between tool usage and performance highlights the effectiveness of DCI in fine-grained evidence composition and verification.

The evaluation compares DCI agents against retrieval-based baselines across multiple knowledge-intensive QA, search, and information retrieval benchmarks, while also validating different context management strategies. Results indicate that direct corpus interaction enables superior evidence localization and reasoning, with the full DCI variant consistently achieving the highest accuracy and the lightweight variant delivering a highly competitive, cost-efficient alternative. The context policy experiments validate that moderate truncation and compaction without summarization optimally balance information retention with sustained multi-step reasoning. Overall, the findings establish that selective context handling and direct interaction outperform traditional retrieval methods in both precision and efficiency.