Command Palette
Search for a command to run...
D-OPSD: 연속적으로 튜닝된 Step-Distilled Diffusion Models를 위한 온-폴리시 자가 증류
D-OPSD: 연속적으로 튜닝된 Step-Distilled Diffusion Models를 위한 온-폴리시 자가 증류
초록
고성능 이미지 생성 모델의 현황은 현재 비효율적인 다단계 모델에서 효율적인 소수 단계 Few-step 모델을 중심으로 빠르게 변화하고 있습니다(예: Z-Image-Turbo, FLUX.2-klein). 그러나 이러한 모델들은 직접적인 지속적인 Supervised Fine-Tuning(SFT) 수행에 상당한 과제를 제시합니다. 예를 들어, 일반적으로 사용되는 파인튜닝 기법을 적용하면 모델이 가진 본연의 소수 단계 Few-step 추론 Capability가 저해될 수 있습니다. 이러한 문제를 해결하기 위해 본 연구에서는 단계 압축 Distilled Diffusion Models를 위한 온-폴리시 On-Policy 학습을 가능하게 하는 새로운 학습 패러다임인 D-OPSD를 제안합니다.우리는 최신 Diffusion 모델에서 LLM이나 VLM이 Encoder로 활용될 경우, 해당 Encoder의 인-컨텍스트 In-Context Capability를 계승할 수 있음을 발견했습니다. 이 사실을 바탕으로 본 연구는 학습 과정을 온-폴리시 Self-Distillation 프로세스로서 접근합니다. 구체적으로, 학습 중 모델은 서로 다른 Context를 사용하여 교사-학생 Teacher-Student 구조에서 양쪽 역할을 모두 수행합니다. 이때 Student 모델은 텍스트 Feature에만 Conditioning되며, Teacher 모델은 텍스트 프롬프트와 타겟 이미지의 멀티모달 Feature 모두에 Conditioning됩니다. 학습 과정은 Student의 Own Roll-outs에 대한 두 예측 분포를 최소화하는 방식으로 진행됩니다.D-OPSD는 모델 자신의 Trajectory를 최적화하고 모델 자신의 Supervision 하에 학습을 진행함으로써, 원래의 Few-step Capacity를 희생하지 않고도 새로운 개념이나 스타일 등을 학습할 수 있게 합니다.
One-sentence Summary
The authors propose D-OPSD, a training paradigm for step-distilled diffusion models that enables continuous supervised fine-tuning via on-policy self-distillation by minimizing predicted distributions over the student's own roll-outs while conditioning the student on the text feature and the teacher on the multimodal feature of both the text prompt and the target image to preserve inherent few-step inference capability.
Key Contributions
- The paper introduces D-OPSD, a training paradigm for step-distilled diffusion models that enables on-policy learning during supervised fine-tuning.
- The framework utilizes the emergent in-context capabilities of modern encoders to facilitate self-distillation, where the model acts as both teacher and student under different multimodal and text-only conditions.
- Experiments across LoRA adaptation and full fine-tuning demonstrate that the method effectively learns new concepts and styles while preserving the original few-step generation ability.
Introduction
Text-to-image diffusion models have advanced significantly, yet their iterative sampling processes incur high computational costs that step-distillation techniques aim to mitigate. However, continually fine-tuning these efficient models poses significant challenges because conventional supervised fine-tuning disrupts learned few-step dynamics through a train-test mismatch. Online reinforcement learning offers a solution but demands reward functions that are often impractical for developers. The authors address these issues with D-OPSD, a novel on-policy self-distillation framework that leverages the emergent in-context capabilities of modern LLM-based encoders. By enabling the model to act as both a student and a teacher during training, this method allows for supervised adaptation on the model's own rollouts without external rewards. Consequently, new concepts are learned while preserving the original few-step inference capability.
Method
The authors propose D-OPSD, a training paradigm designed to enable on-policy learning for step-distilled diffusion models. This approach addresses the challenge where standard supervised fine-tuning compromises the inherent few-step inference capability of modern efficient models. The core idea leverages on-policy self-distillation, where the model acts as both a teacher and a student under different contextual conditions.
Refer to the framework diagram for a visual overview of the method.
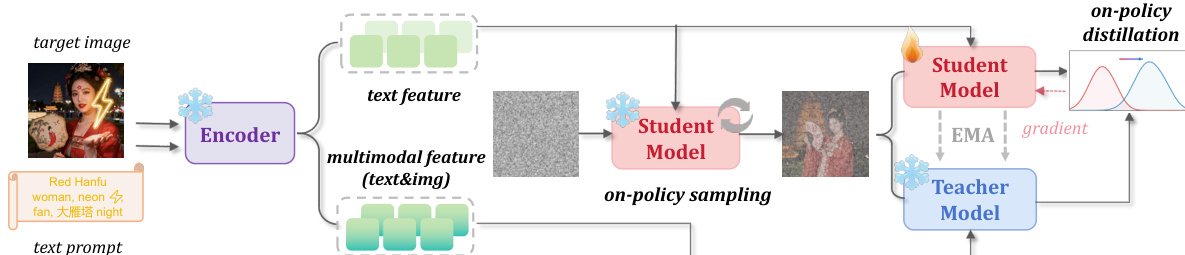
The process begins with an encoder that processes the input text prompt and the target image. For each training pair, the system constructs two distinct conditioning vectors. The student condition cs is derived solely from the text prompt, ensuring the student branch follows the original text-to-image generation pathway. In contrast, the teacher condition ct incorporates multimodal features from both the text prompt and the target image. This multimodal context allows the teacher to provide stronger supervision regarding the target concept or style without disrupting the student's sampling trajectory.
During training, the student model generates an on-policy trajectory by sampling from Gaussian noise using a few-step solver. Let xtks denote the latent state at step k. The student predicts the velocity field uks=vθ(xtks,tk,cs). Simultaneously, the teacher model, parameterized by an exponential moving average (EMA) of the student weights, predicts the velocity ukt=vθˉ(xtks,tk,ct) on the exact same states generated by the student. This setup ensures that the supervision is computed on the model's own trajectory rather than an external offline distribution.
The optimization objective minimizes the mean squared error between the student's velocity predictions and the teacher's predictions on these shared states. The loss function is formulated as:
LD-OPSD=E(x0,y)[K1k=1∑Kuks−sg(ukt)22]where sg(⋅) denotes the stop-gradient operation. By aligning the student's conditional generation dynamics with the teacher's stronger multimodal guidance, the model learns new concepts or styles while preserving the original few-step sampling behavior. After training, the teacher branch is discarded, and inference proceeds using the standard few-step pipeline conditioned only on text.
Experiment
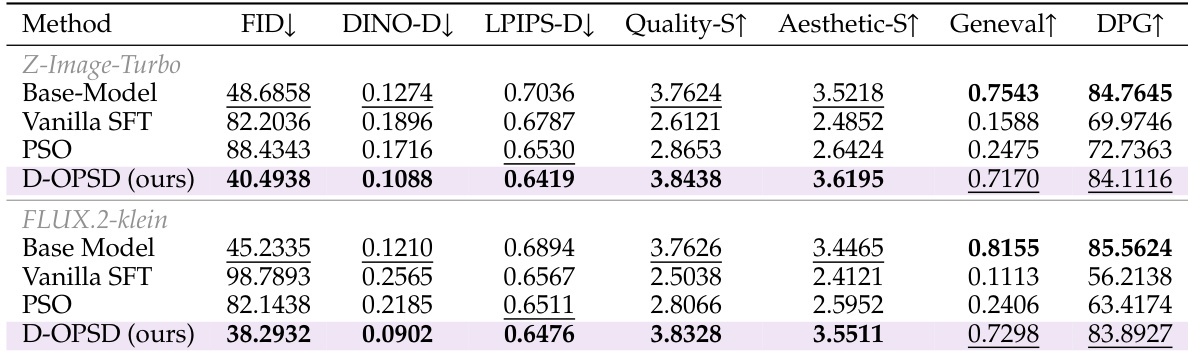
The evaluation utilizes Z-Image-Turbo and FLUX.2-klein models to compare the proposed method against baselines like Vanilla SFT and Dreambooth across small-scale LoRA and large-scale full finetuning scenarios. Experimental results demonstrate that while standard training approaches often compromise few-step generation quality or suffer from overfitting, the proposed method effectively learns new concepts and adapts to new domains without catastrophic forgetting. Furthermore, ablation studies validate that on-policy self-distillation is essential for maintaining high generation quality and achieving faster convergence compared to off-policy variants.
The authors compare the proposed D-OPSD method against baselines like Vanilla SFT and PSO across Z-Image-Turbo and FLUX.2-klein architectures. Results indicate that D-OPSD achieves superior alignment with target images while preserving the model's original few-step generation quality and general knowledge retention. In contrast, baseline methods suffer from significant degradation in image quality and capability retention. D-OPSD achieves lower error rates in image similarity metrics compared to Vanilla SFT and PSO. The proposed method preserves few-step sampling capacity with quality scores close to or exceeding the base model. Baseline methods exhibit significant drops in general knowledge benchmarks, whereas D-OPSD retains these capabilities.
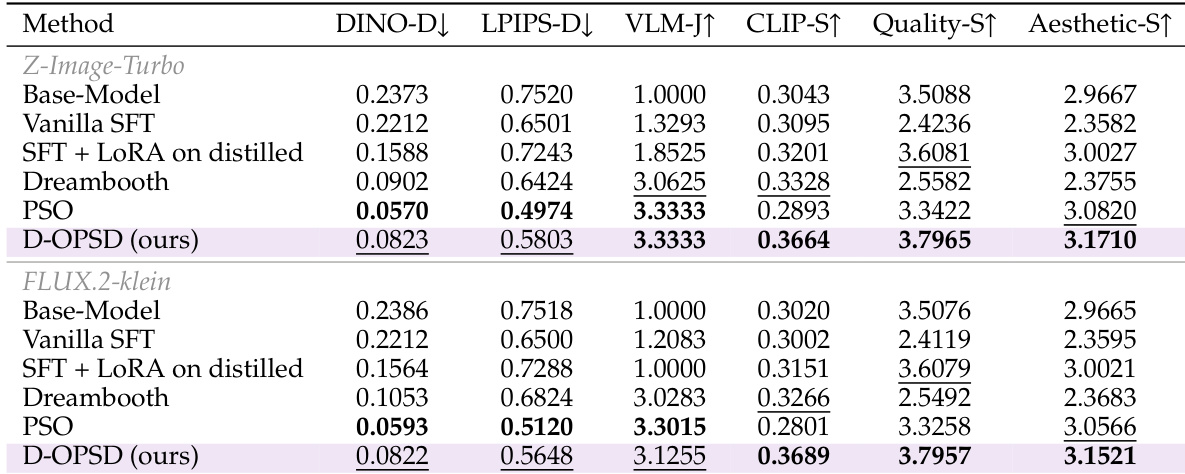
The authors compare their proposed D-OPSD method against several baselines including Vanilla SFT, Dreambooth, and PSO using Z-Image-Turbo and FLUX.2-klein models. The results demonstrate that D-OPSD effectively balances learning new concepts with maintaining high image quality and aesthetic standards, outperforming methods that degrade generation capabilities. D-OPSD achieves the highest Quality-S and Aesthetic-S scores in both model configurations, indicating it preserves few-step sampling capacity better than SFT and Dreambooth. The proposed method attains the highest CLIP-S scores and ties for the top VLM-J score, demonstrating strong generalization and subject consistency. While PSO achieves low distance metrics suggesting strong target alignment, D-OPSD avoids overfitting by maintaining significantly higher generalization and quality scores.
The the the table contrasts the proposed D-OPSD method with standard SFT, offline RL, and online RL baselines based on their supervision signals and training properties. It demonstrates that D-OPSD uniquely combines on-policy training with self-distilled velocity to ensure the training distribution matches the inference distribution without needing an external reward model. D-OPSD is the only method listed that achieves a match between training and inference conditions. The approach utilizes on-policy sampling with self-distilled velocity rather than ground truth or external rewards. Unlike online RL methods, D-OPSD does not require a separate reward model for supervision.

The authors evaluate D-OPSD against various baselines including Vanilla SFT and PSO across Z-Image-Turbo and FLUX.2-klein architectures to assess alignment and capability retention. Results indicate that the proposed method effectively balances learning new concepts with maintaining high image quality and general knowledge, whereas baseline methods suffer from significant degradation or overfitting. Additionally, the method uniquely aligns training and inference distributions through on-policy sampling without requiring external reward models.