Command Palette
Search for a command to run...
추론 집약적 검색 재고찰: 에이전트 검색 시스템에서의 검색기 평가 및 발전
추론 집약적 검색 재고찰: 에이전트 검색 시스템에서의 검색기 평가 및 발전
Yilun Zhao Jinbiao Wei Tingyu Song Siyue Zhang Chen Zhao Arman Cohan
초록
추론 집약적 검색(Reasoning-intensive retrieval)의 목적은 단순한 주제 유사성 매칭을 넘어, 하류 추론 작업을 지지하는 증거를 발견하는 것이다. 이 능력은 검색 및 분석 과정을 반복적으로 수행하며 상호 보완적인 증거를 제공해야 하는 에이전트 기반 검색(Agentic search) 시스템에서 점점 더 중요해지고 있다. 그러나 기존 연구는 평가와 훈련 양면에서 제한적이다. BRIGHT와 같은 벤치마크는 좁은 범위의 정답(Gold) 집합만을 제공하며 검색기를 분리된 상태로 평가한다. 또한, 합성 훈련 데이터(Synthetic training corpora)는 종종 단편적 문서 단위의 관련성(Single-passage relevance) 최적화에 치우쳐, 증거 포트폴리오 구축(Evidence portfolio construction)을 고려하지 않는 경향이 있다.우리는 BRIGHT-PRO를 소개한다. 이는 전문가가 주석(Annotate)을 단 벤치마크로, 각 쿼리(Query)에 다각적 정답 증거(Multi-aspect gold evidence)를 확대하여 정적(Static) 검색과 에이전트 기반 검색 프로토콜(Agentic search protocol) 하에서 모두 검색기를 평가한다. 추가로 우리는 측면 분해(Aspect-decomposed) 합성 코퍼스인 RTriever-Synth를 구축하여 상호 보완적인 긍정 샘플(Complementary positives)과 긍정 조건부 하드 부정 샘플(Positive-conditioned hard negatives)을 생성한다. 이를 기반으로 Qwen3-Embedding-4B에서 파생된 RTriever-4B 모델에 LoRA 파인튜닝(LoRA fine-tune)을 적용한다. 어휘 기반(Lexical), 범용(General-purpose), 추론 집약적(Reasoning-intensive) 검색기들에 대한 실험 결과는 측면 인식(Aware) 및 에이전트 기반 평가가 기존 표준 지표로 숨겨지는 모델의 행동을 드러내며, RTriever-4B가 베이스 모델(Base model) 대비 유의미한 성능 향상을 달성함을 보여준다.
One-sentence Summary
Addressing limitations in existing evaluation and training for reasoning-intensive retrieval, the authors introduce BRIGHT-PRO, an expert-annotated benchmark evaluating retrievers under static and agentic search protocols with multi-aspect gold evidence, and RTriever-Synth, an aspect-decomposed synthetic corpus generating complementary positives and positive-conditioned hard negatives to LoRA fine-tune RTriever-4B from Qwen3-Embedding-4B, which substantially improves over its base model for evidence portfolio construction in agentic search systems.
Key Contributions
- BRIGHT-PRO is introduced as an expert-annotated benchmark that extends BRIGHT with multi-aspect evidence and evaluates retrievers under both static and agentic search settings.
- RTriever-Synth is presented as an aspect-decomposed synthesis pipeline that generates complementary positives from reference-answer reasoning and positive-conditioned hard negatives for training retrievers.
- RTriever-4B is trained by LoRA fine-tuning Qwen3-Embedding-4B on RTriever-Synth to specialize in reasoning-intensive evidence selection. Experiments show that aspect-aware and agentic evaluation expose behaviors hidden by standard metrics while the model substantially improves over its base version.
Introduction
Reasoning-intensive retrieval is essential for agentic search systems where models must gather diverse evidence to support complex multi-step reasoning. However, prior benchmarks like BRIGHT rely on narrow gold sets and evaluate retrievers in isolation, while training data often optimizes for single-passage relevance rather than constructing a complete evidence portfolio. To address these gaps, the authors introduce BRIGHT-PRO, an expert-annotated benchmark that evaluates retrievers under both static and agentic search protocols with multi-aspect supervision. They further develop RTriever-Synth, a synthetic corpus designed to teach models to select complementary evidence, which they use to fine-tune RTriever-4B for significantly improved performance in reasoning-intensive tasks.
Dataset
- The authors build the BRIGHT-PRO benchmark upon the BRIGHT dataset, selecting the StackExchange subset to focus on open-domain natural language reasoning rather than domain-specific coding or theorem tasks.
- Positive passages are collected by tracing hyperlinks in accepted answers, while negative samples are generated via Google Search using post titles or LLM keywords to find topically related but irrelevant pages.
- Field-specific experts decompose queries into reasoning aspects and assign importance weights using a 1 to 5 Likert scale that is normalized to sum to 1.
- Original positive passages undergo re-auditing for topical fidelity and are merged if they overlap or come from the same URL to preserve context and reduce redundancy.
- New documents are acquired through web or AI-assisted search and processed with the FireCrawl framework to strip boilerplate content like advertisements and navigation menus.
- Extracted text is manually refined to remove noise and segmented into aspect-specific portions when a document supports multiple reasoning needs.
- Independent second-annotator reviews verify aspect coverage and document evidence, achieving a weighted Cohen’s kappa of 0.742 for weight reliability.
- The dataset serves as a unified retrieval corpus for evaluating reasoning-intensive retrieval systems, with detailed statistics on query and document counts provided in Table 1.
Method
The authors leverage a specialized synthesis pipeline to construct high-quality training bundles for the RTriever model. As shown in the figure below, the framework, specifically the RTriever Training module on the right, operates through two primary stages: Query Synthesis and Passage Synthesis, culminating in the fine-tuning of the retriever.
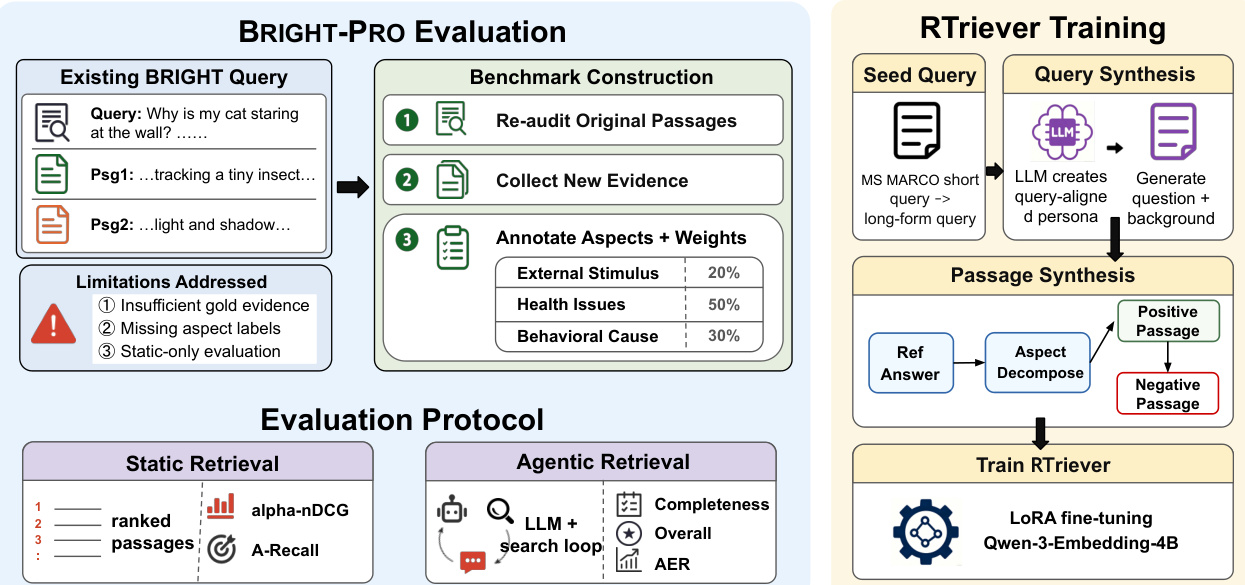
Query and Passage Synthesis Pipeline The data construction process is designed to create realistic deep-research queries and complementary evidence sets. Refer to the detailed workflow below:
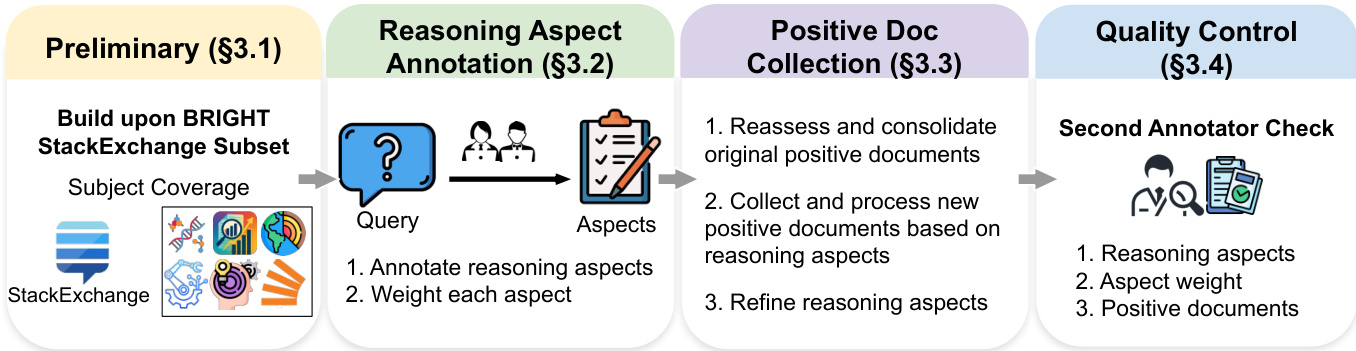
The pipeline initiates with a preliminary phase building upon the BRIGHT StackExchange subset. It then proceeds to Reasoning Aspect Annotation, where queries are annotated with key aspects and weights. Following this, Positive Document Collection involves reassessing original documents and collecting new evidence based on the reasoning aspects. Finally, a Quality Control step ensures the validity of the aspects, weights, and documents through a second annotator check.
Specifically, the synthesis involves three key components:
- Realistic Query Surface: Starting from MS MARCO seeds, the authors sample personas from PersonaHub and prompt an LLM to rewrite the seed into a DeepResearch-style post with a question and background. A classifier then labels the query as factual or analytical.
- Aspect-Decomposed Gold Passages: For analytical queries, a strong LLM first produces a comprehensive reference answer. A second LLM call decomposes this answer into two to three non-overlapping reasoning aspects. For each aspect, a blueprint is generated containing the rationale, passage type, and a TL;DR. These blueprints are then instantiated as full positive passages. This ensures that every positive passage is load-bearing and complementary to others in the bundle.
- Positive-Conditioned Hard Negatives: After fixing positive blueprints, the system synthesizes an equal number of hard negatives. These are conditioned on the query and positive summaries, designed to share topical cues but fail the information need by omitting specific aspects required by the positives.
RTriever Training Details The training utilizes the synthesized bundles, filtering them down to 140K complete sets from an initial sample of 140K queries. The authors obtain RTriever-4B by LoRA fine-tuning the Qwen3-Embedding-4B model. The LoRA adapters are attached to all linear projection layers with a rank of r=16 and a scaling factor of α=32, while the original embedding parameters remain frozen.
The optimization targets a contrastive InfoNCE objective with a temperature of τ=0.02. In each training step, a query is paired with one randomly sampled positive passage and one synthesized hard negative, with other documents in the batch serving as in-batch negatives. The model is trained for 5 epochs with a peak learning rate of 1×10−5, a 5% linear warm-up, and bf16 mixed-precision optimization. The effective batch size is 768, processed over 2 NVIDIA B200 GPUs, with sequences truncated to 2,048 tokens.
Experiment
The study employs a dual evaluation protocol comprising a static setting that measures aspect coverage diversity and an agentic setting that tests retrievers within iterative deep-research workflows. Findings demonstrate that reasoning-intensive retrievers outperform general-purpose models in static tasks, yet static rankings do not always translate to agentic success due to divergent search dynamics. Qualitative analysis reveals specific failure modes such as aspect tunnel vision and evidence deprivation, underscoring the need for evaluation frameworks that prioritize full evidence portfolios over single-passage relevance.
The authors evaluate retrievers within a fixed-round agentic search workflow where the agent iteratively searches and generates answers over three rounds. Results indicate that while static retrieval rankings translate loosely to the agentic loop, BGE-Reasoner-8B consistently outperforms other models in both retrieval quality and final answer quality across all rounds. BGE-Reasoner-8B consistently achieves the highest retrieval diversity and overall answer quality scores across all interaction rounds. The proposed RTriever-4B secures third place in overall answer quality, outperforming general-purpose embedders while remaining competitive with other reasoning-intensive models. Lower-tier models exhibit a divergence between retrieval effectiveness and final answer quality, with some baselines demonstrating improved retrieval diversity by the final round despite lower initial rankings.
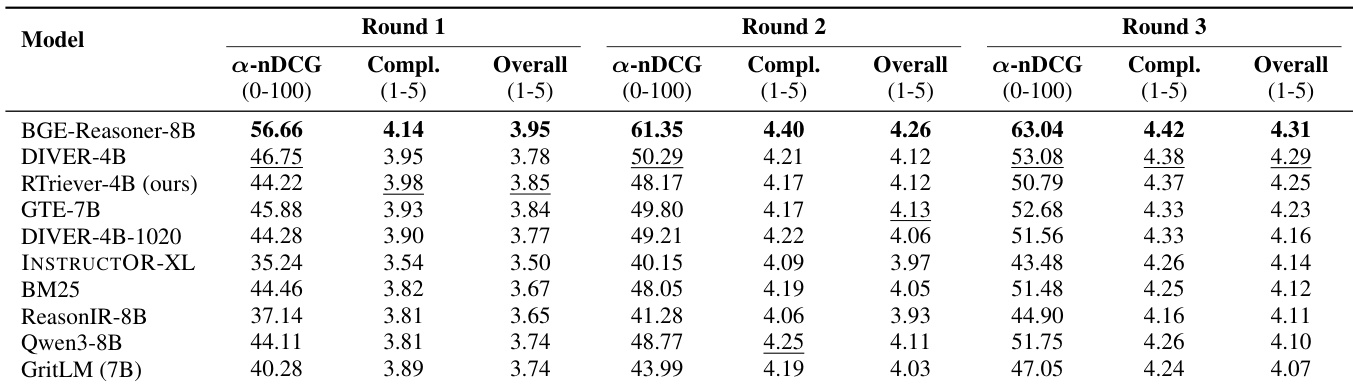
The the the table details retrieval statistics for a specific case study where the agent failed to cover all reasoning aspects due to repetition bias. It shows that the retriever frequently fetched the same non-gold documents related to primates and human monogamy, consuming a significant portion of the search budget. In contrast, relevant gold documents were retrieved much less often, indicating that the search loop became fixated on off-topic clusters. Retrievals of non-gold documents occurred significantly more often than retrievals of gold documents. The retriever repeatedly surfaced the same off-topic documents across multiple search rounds. Relevant gold documents appeared infrequently in the results, suggesting poor diversity in evidence gathering.

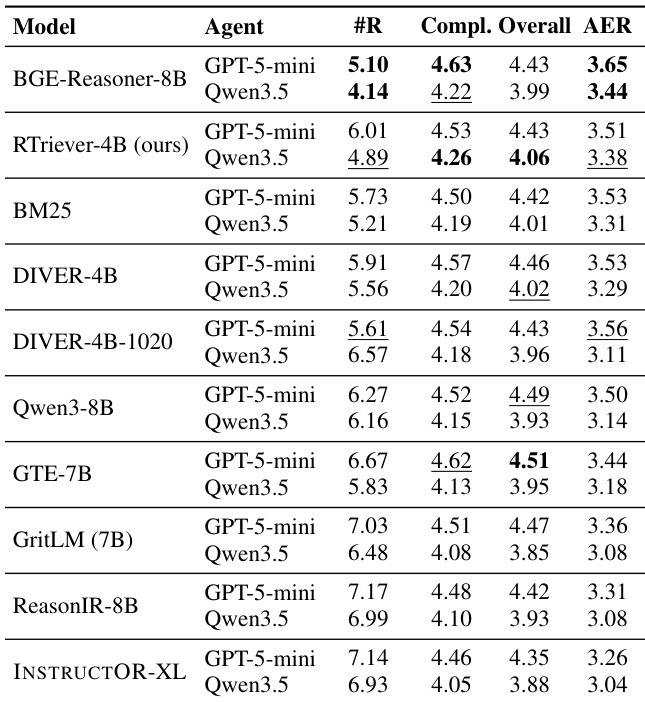
The authors evaluate retrievers in a static setting using the BRIGHT-PRO benchmark, which measures aspect-aware retrieval quality across seven expert domains. The results demonstrate a clear performance gap where reasoning-intensive retrievers consistently outperform general-purpose embedding models and classical baselines. The proposed RTriever-4B model achieves competitive results, ranking among the top performers despite having fewer parameters than some leading general-purpose models. Reasoning-intensive retrievers form a distinct upper tier in performance, significantly exceeding general-purpose embedders across all evaluated domains. The proposed RTriever-4B model demonstrates strong capability in specialized fields like Biology and Earth Science, competing closely with larger reasoning models. Classical lexical baselines and smaller embedding models occupy the lower ranks, underscoring the necessity of aspect-aware training for complex retrieval tasks.
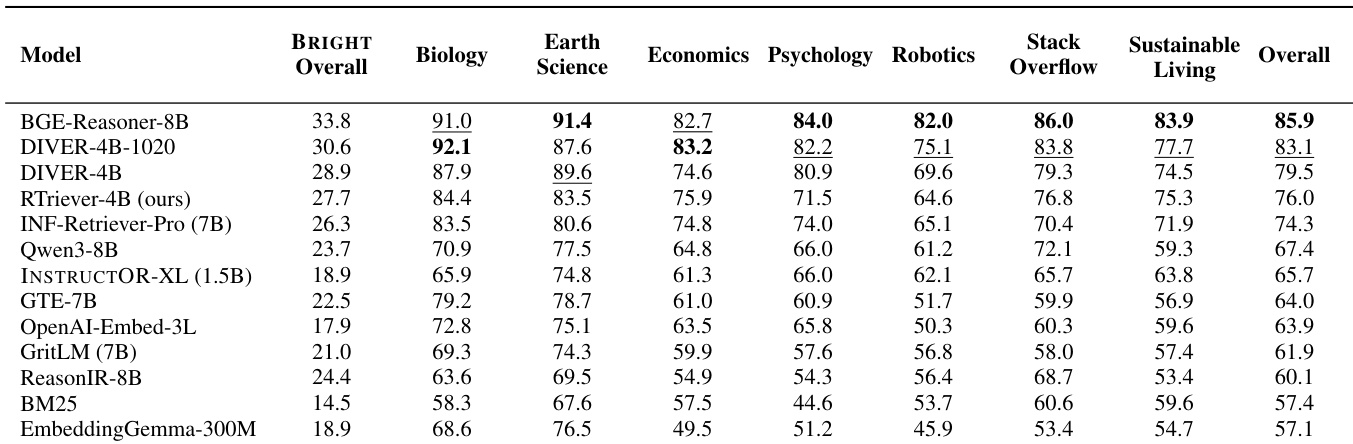
The authors evaluate retrievers in a static setting using aspect-aware metrics to assess coverage of reasoning aspects across multiple domains. Results indicate that reasoning-intensive models consistently outperform general-purpose embedding baselines, forming a distinct upper tier of performance. The proposed RTriever-4B model achieves strong results, ranking within the top group of specialized retrievers despite having fewer parameters than some competitors. Reasoning-intensive retrievers establish a clear performance tier significantly above general-purpose embedding models across all domains. BGE-Reasoner-8B achieves the highest scores across the majority of domains and the overall aggregate metric. RTriever-4B outperforms larger general-purpose baselines, demonstrating the effectiveness of its specific training objective over parameter count.
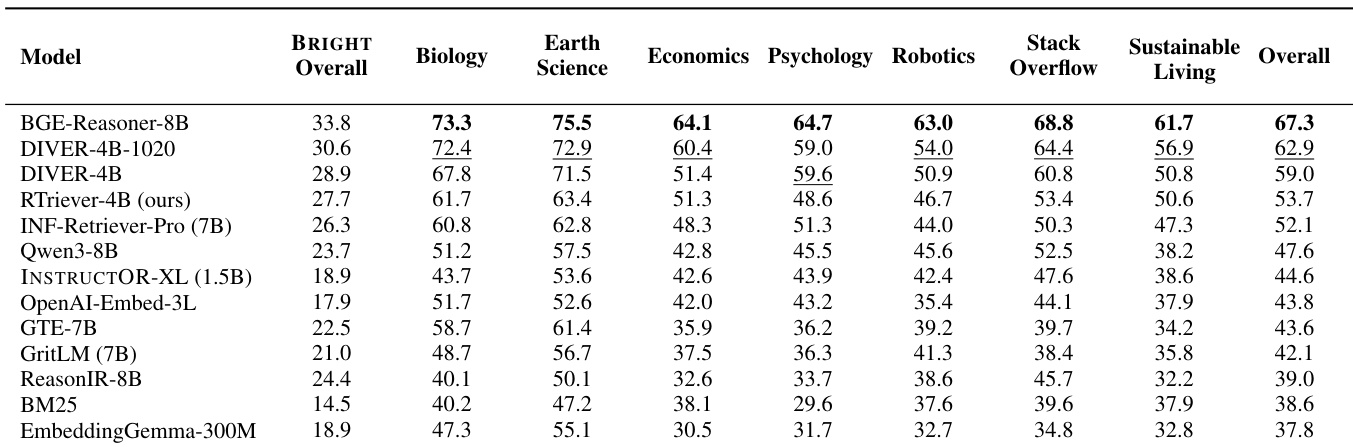
The the the table presents results from an adaptive-round agentic retrieval evaluation, measuring how efficiently different retrievers support LLM agents in deep-research workflows. It highlights a trade-off where the highest overall answer quality does not always correlate with the best efficiency score, as models requiring more search rounds incur a penalty in the Efficiency-Quality Reward metric. BGE-Reasoner-8B secures the highest efficiency score by converging on answers in the fewest search rounds. RTriever-4B maintains a consistent second-place ranking in efficiency across different agent backends, indicating robust performance with lower computational cost. Models like GTE-7B achieve the peak overall answer quality but are penalized in efficiency metrics due to their reliance on a higher number of retrieval rounds.
The authors evaluate retrievers across static benchmarks and agentic search workflows to assess aspect-aware retrieval quality and final answer generation. Reasoning-intensive models consistently form a distinct upper tier, outperforming general-purpose embedding baselines in retrieval diversity and answer accuracy, with BGE-Reasoner-8B converging in fewer search rounds. While weaker models often fail due to repetition bias, the proposed RTriever-4B remains a competitive alternative that demonstrates the effectiveness of specialized training over parameter count.