Command Palette
Search for a command to run...
HEAVYSKILL: 에이전틱 하니스에서 내부 기술로서의 무거운 사고
HEAVYSKILL: 에이전틱 하니스에서 내부 기술로서의 무거운 사고
초록
다양한 에이전트들의 메모리, 기술 및 도구 사용을 조정하는 오케스트레이션 프레임워크와 결합된 에이전틱 헐리스(Agentic Harness)의 최근 발전은 복잡한 추론 작업에서 눈부신 성과를 거두었습니다. 그러나 이러한 성능을 실제로 이끄는 근본적인 메커니즘은 복잡다단한 시스템 설계 뒤에 가려져 있습니다. 본 논문에서는 HEAVYSKILL이라는 관점을 제안합니다. 이는 '헤비 씽킹(Heavy Thinking)'을 오케스트레이션 헐리스에서 최소 실행 단위로만 보지 않고, 오케스트레이터가 복잡한 작업을 해결하도록 촉진하는 모델 파라미터 내부에 내재화된 내부 기술로 바라봅니다. 우리는 이 기술을 병렬 추론 후 요약이라는 두 단계 파이프라인(pipeline)으로 식별하며, 이는 어떤 에이전틱 헐리스에서도 하부에서 작동할 수 있습니다. 우리는 다양한 도메인에서 HEAVYSKILL에 대한 체계적인 실증 연구를 제시합니다. 우리 연구 결과는 이 내부 기술이 기존의 Best-of-N (BoN) 전략보다 일관되게 더 뛰어난 성능을 발휘함을 보여줍니다. 특히, 더 강력한 LLM은 Pass@N 성능에 근접할 수도 있음을 확인했습니다. 결정적으로, 우리는 학습 가능한 기술로서의 헤비 씽킹의 깊이와 너비를 강화 학습(reinforcement learning)을 통해 추가로 확장할 수 있음을 입증함으로써, 취약한 오케스트레이션 계층에 의존하지 않고 복잡한 추론을 내부화하는 자기 진화형 LLM(Self-evolving LLMs)으로 나아가는 유망한 경로를 제시했습니다.
One-sentence Summary
The authors propose HEAVYSKILL, a perspective framing heavy thinking not merely as a minimal execution unit but as an inner skill internalized within model parameters and identified as a two-stage pipeline of parallel reasoning and summarization, demonstrating through systematic empirical study that it outperforms traditional Best-of-N strategies and allows stronger LLMs to approach Pass@N performance while scaling via reinforcement learning to offer a path toward self-evolving LLMs without relying on brittle orchestration layers.
Key Contributions
- This work introduces HEAVYSKILL, a training-free framework that reproduces heavy thinking for complex reasoning tasks through a two-stage pipeline of parallel reasoning and sequential deliberation.
- A comprehensive empirical study across diverse model scales and task domains establishes the effectiveness of this approach, showing it consistently outperforms traditional Best-of-N strategies.
- Systematic analyses demonstrate that reinforcement learning from verifiable rewards can scale the depth and width of heavy thinking to improve reasoning metrics like Heavy-Mean@k and Pass@k.
Introduction
Recent advances in agentic harnesses coordinate multiple agents to solve complex reasoning tasks, yet the mechanisms driving this performance remain obscured by intricate system designs. Existing parallel reasoning methods often depend on static schedules or hand-crafted heuristics that lack adaptivity and rely heavily on brittle orchestration layers. To address this, the authors introduce HEAVYSKILL, a perspective that treats heavy thinking as an inner skill internalized within the model's parameters rather than just an execution unit. They propose a two-stage pipeline involving parallel reasoning followed by sequential deliberation that operates beneath any agentic harness. Systematic empirical studies demonstrate that this approach consistently outperforms traditional Best-of-N strategies and can be scaled via reinforcement learning to improve reasoning depth and width without external orchestration.
Method
The Heavy Thinking framework operates through a structured inference pipeline designed to scale reasoning capabilities at test time. As shown in the figure below, the architecture decomposes the process into two distinct phases: parallel reasoning and sequential deliberation.
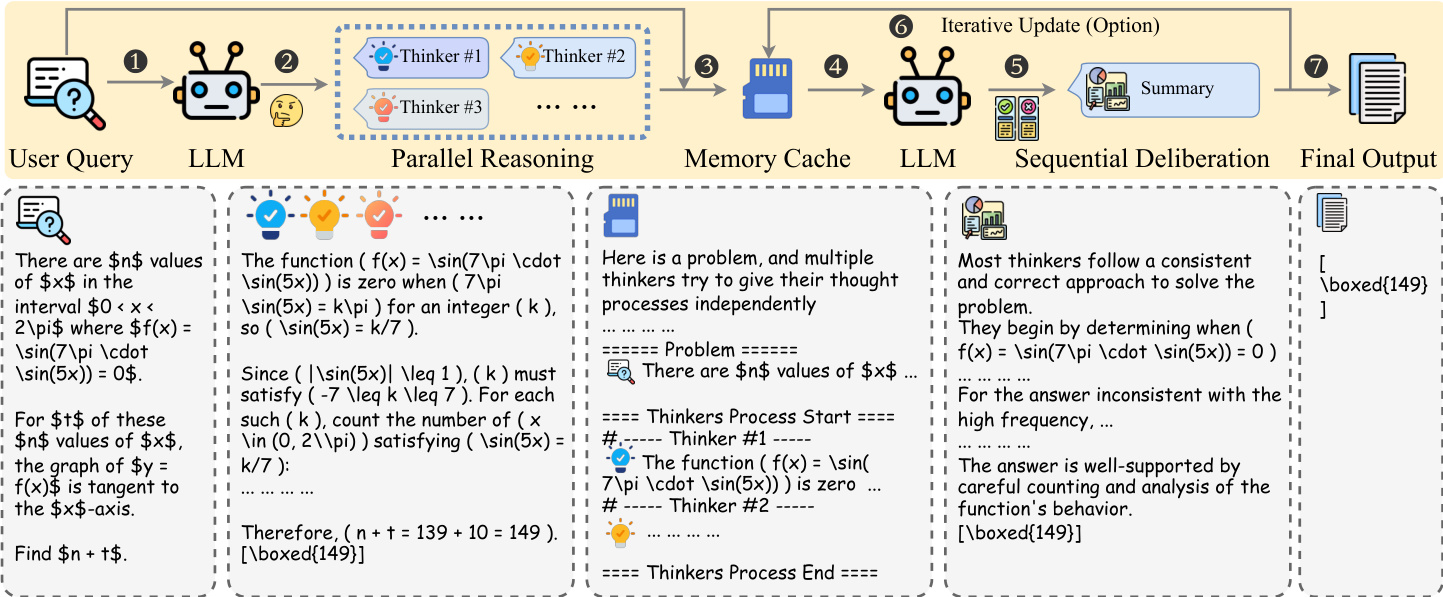
In the first phase, parallel reasoning, the system aims to generate multiple independent trajectories for a given problem q. Formally, the model πθ produces a set of trajectories Tπθ(q,K)={y1,⋯,yK}, where K represents the number of parallel agents. Each trajectory yi is generated autoregressively. This stage encourages diverse problem-solving strategies without the agents sharing context or seeing each other's work.
To facilitate the transition to the next stage, the framework employs a serialized memory cache mechanism. Since full reasoning traces can exceed context limits, the trajectories are pruned and shuffled to create a serialized context C(xc). This ensures the subsequent model does not develop positional bias and can process the information within token constraints.
The second phase, sequential deliberation, involves a separate LLM πϕ that aggregates the information from the cache. This model acts as a meta-reasoner, tasked with synthesizing the independent thought processes. The prompt structure used for this deliberation is illustrated in the image below.

The deliberation prompt explicitly instructs the model to analyze the reasoning quality of each thinker rather than relying on simple majority voting. It requires the model to identify logical errors, cross-validate approaches, and apply professional skepticism. If the model determines that all provided trajectories are flawed, it is instructed to re-think the problem independently to derive the correct answer.
The implementation of this workflow is further detailed in the readable skill documentation shown in the following image.

This documentation outlines specific protocols for the orchestrator, such as spawning parallel agents and managing the deliberation process. It emphasizes that the final output should contain only the synthesized answer in the appropriate format (e.g., boxed for math) rather than the meta-analysis itself.
Furthermore, the skill definition includes key principles for effective execution, as seen in the subsequent image.

These principles mandate that parallel agents remain independent and that deliberation focuses on synthesis rather than voting. For particularly challenging problems, the framework supports an optional iterative refinement loop. In this mode, the result from the sequential deliberation is fed back into the memory cache as an additional expert trajectory, allowing the system to re-run the deliberation phase until convergence is reached.
Experiment
The evaluation utilized diverse models across STEM and general reasoning benchmarks to compare a heavy thinking framework against standard baselines such as majority voting. Experiments validate that sequential deliberation consistently outperforms single-trajectory attempts, particularly on objective tasks where it synthesizes correct solutions beyond the raw reasoning potential of individual trajectories. While the framework demonstrates robust test-time scaling and compatibility with agentic tool use, findings indicate a trade-off between iterative depth and information consistency, with performance gains varying based on task subjectivity.
The authors evaluate a heavy thinking framework on various STEM benchmarks using both closed and open-weights models. Results indicate that combining parallel reasoning with sequential deliberation consistently yields higher performance than standard metrics like mean accuracy and majority voting. Furthermore, the framework demonstrates the ability to approach or exceed the intrinsic reasoning potential of the models, particularly on complex tasks. Heavy thinking metrics consistently outperform the average accuracy of parallel trajectories across all tested models. Sequential deliberation proves more effective than heuristic voting strategies, especially on challenging benchmarks. The potential of the deliberation process often matches or surpasses the raw pass rate of parallel sampling, indicating synthesized reasoning gains.
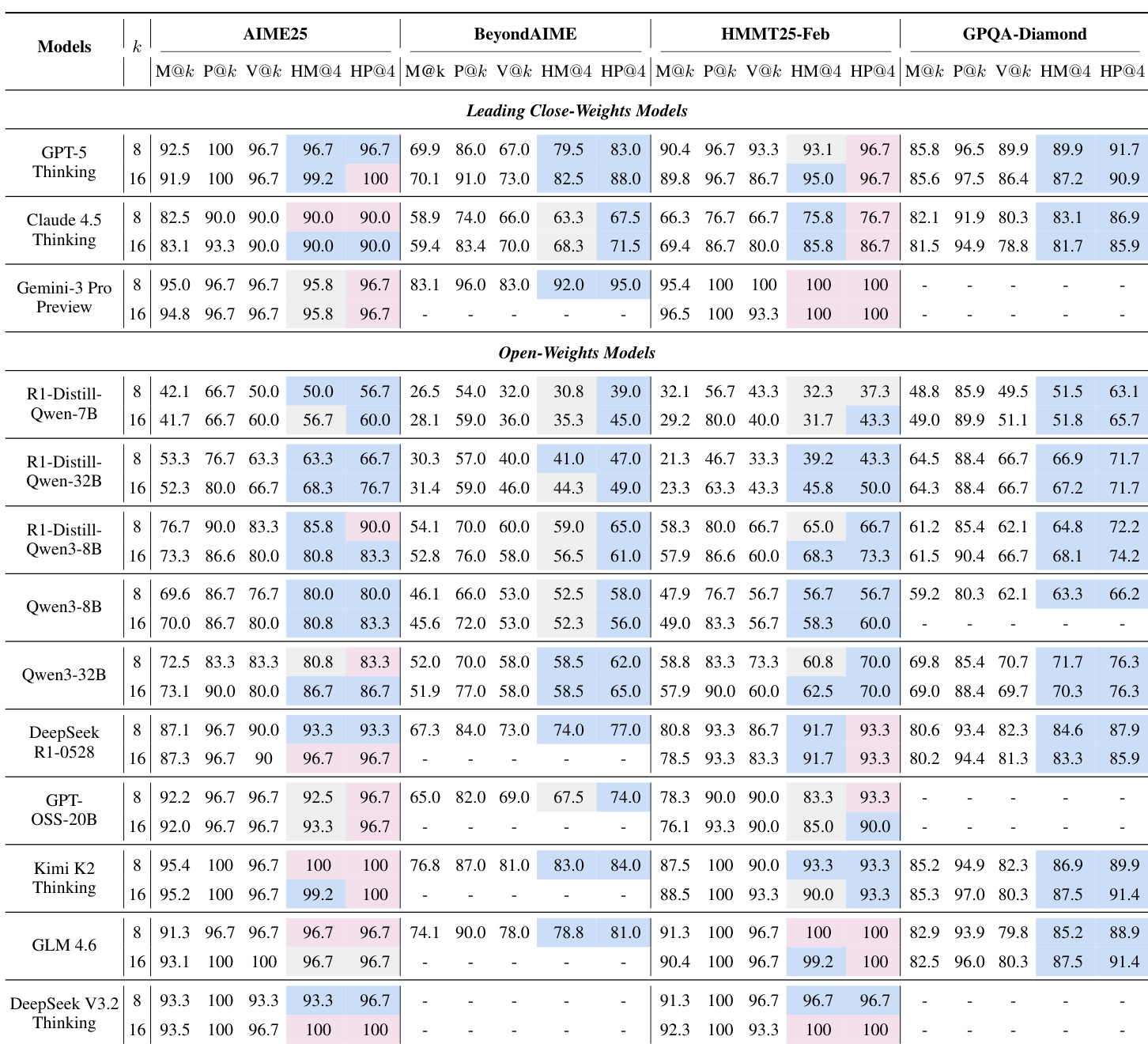
The authors evaluate a heavy thinking framework combining parallel reasoning with sequential deliberation on STEM benchmarks. Results indicate that the heavy thinking metric consistently surpasses standard metrics like majority voting and mean accuracy, demonstrating the effectiveness of synthesizing multiple reasoning paths. Furthermore, larger models achieve higher performance, with the framework helping them approach their theoretical reasoning limits. Heavy thinking consistently outperforms heuristic majority voting strategies across all evaluated models. Sequential deliberation provides a significant boost over the average accuracy of parallel reasoning trajectories. Larger models exhibit superior performance, with heavy thinking scores approaching the intrinsic potential of the raw trajectories.
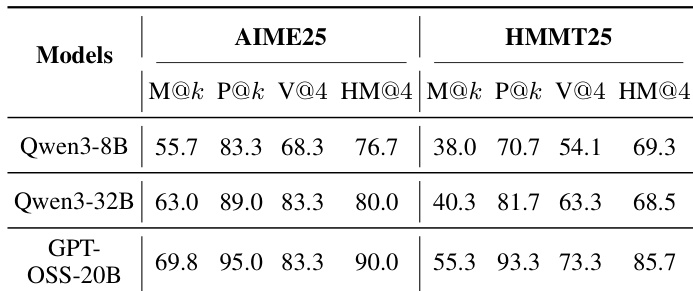
The authors evaluate a heavy thinking framework that combines parallel reasoning with sequential deliberation across various models and benchmarks. The results demonstrate that this approach yields substantial improvements on objective tasks involving coding and instruction following, while showing more limited benefits on subjective preference alignment. Furthermore, the deliberation process consistently unlocks higher performance potential than the initial parallel sampling alone. Sequential deliberation yields substantial performance gains on objective benchmarks like LiveCodeBench and IFEval compared to standard parallel reasoning. The framework provides marginal or inconsistent improvements on subjective tasks such as Arena-Hard where preference alignment is key. The deliberation phase consistently achieves higher potential pass rates than the raw parallel trajectories, indicating an ability to synthesize new correct solutions.
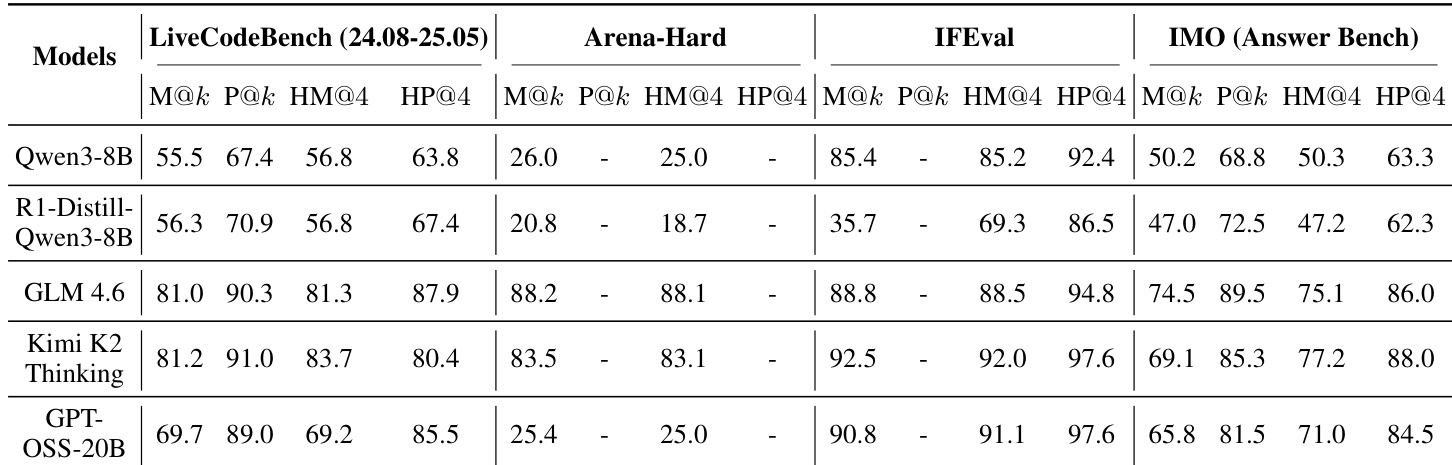
The authors evaluate a heavy thinking framework integrating parallel reasoning with sequential deliberation across diverse models and benchmarks including STEM, coding, and instruction following. Experiments demonstrate that sequential deliberation consistently outperforms standard heuristic voting strategies, unlocking higher performance potential than parallel sampling alone on objective tasks. While larger models approach their intrinsic reasoning potential with this method, the framework yields only marginal improvements on subjective preference alignment benchmarks.