Command Palette
Search for a command to run...
GPU를 효율적으로 가속화한 그래프 수정 거리 계산
GPU를 효율적으로 가속화한 그래프 수정 거리 계산
Adel Dabah Andreas Herten
초록
그래프 표현(Graph representation)은 실제 세계의 객체와 관계를 추상화하는 강력한 수단이다. 그래프 간 그래프 편집 거리(Graph Edit Distance, GED) 계산은 생정보학, 머신러닝, 패턴 인식 등의 분야에서 매우 중요하다. GED는 하나의 그래프를 다른 그래프로 변환하는 데 필요한 최소한의 편집 연산 수를 측정한다. 그러나 최적 및 근최적 해를 찾는 방법들의 높은 계산 복잡성은 대규모 그래프에 대한 적용 가능성을 제한하므로, 고성능 병렬 GED 계산이 필수적이다. 이를 해결하기 위해 우리는 GPU 기반 GED 계산을 위한 빠르고 확장 가능한 오픈소스 프레임워크인 FAST-GED를 제안한다. FAST-GED는 GPU 친화적인 알고리즘 설계와 GPU 하드웨어로의 효율적인 매핑을 통해 높은 정확도와 빠른 실행 속도를 결합하고, 호스트-디바이스 간 통신을 최소화함으로써 기존 한계를 극복한다. 본 구현은 여러 GPU 아키텍처에서 최적화 및 테스트되었다. 우리는 다양한 크기와 밀도를 가진 실데이터와 합성 데이터셋을 사용하여 FAST-GED의 성능을 검증하였다. 결과적으로 FAST-GED는 Python의 NetworkX 라이브러리에 비해 수Orders의magnitude의 속도를 개선하며 대부분의 경우 최적해를 도달한다. 또한, 최신 근사 알고리즘(approximate methods)보다 정확도와 확장성 모두에서 우수함을 입증한다. 우리는 FAST-GED가 실제 응용 분야에서 GED 기반 솔루션의 광범위한 채택을 가능하게 함을 보인다.
One-sentence Summary
The authors propose FAST-GED, a GPU-accelerated framework that computes graph edit distance through GPU-friendly algorithmic design and efficient hardware mapping to minimize host-device communication, achieving orders-of-magnitude speedups over the Python NetworkX library, reaching optimal solutions in most cases, and outperforming state-of-the-art approximate methods in both accuracy and scalability across real and synthetic datasets with diverse graph sizes and densities.
Key Contributions
- FAST-GED is a novel GPU-accelerated framework that computes the Graph Edit Distance efficiently by leveraging parallel processing to overcome the scalability and accuracy constraints of existing K-Best methods.
- The framework implements a GPU-optimized K-Best tree search that executes specialized branching, ranking, and update kernels to minimize host-device communication while retaining only the top K nodes at each search level.
- Evaluations on real and synthetic datasets demonstrate that FAST-GED achieves optimal solutions in most cases, delivers order-of-magnitude speedups over the Python NetworkX library and up to 300× speedups over a 48-core AMD EPYC CPU baseline, and outperforms state-of-the-art approximate methods in both accuracy and scalability.
Introduction
Graph-based modeling is foundational to bioinformatics, machine learning, and cybersecurity, where Graph Edit Distance (GED) serves as a critical metric for measuring structural similarity between complex networks. Computing GED is inherently NP-hard, which forces practitioners to choose between exact algorithms that guarantee optimality but become computationally prohibitive on large datasets and approximate methods that scale better but consistently sacrifice accuracy. To bridge this gap, the authors present FAST-GED, a GPU-accelerated framework that integrates a K-Best search strategy with a highly parallelized execution pipeline designed to eliminate costly host-device data transfers. By mapping branching, ranking, and update operations directly to GPU hardware, the authors deliver a solution that maintains high accuracy while achieving speedups of several orders of magnitude over traditional CPU libraries and existing approximate baselines.
Method
The authors leverage a GPU-accelerated approach for computing graph edit distance (GED), termed FAST-GED, which is designed to efficiently approximate the GED between two attributed graphs. The overall framework operates as a modified breadth-first search (BFS) on a search tree, where each node represents a partial edit path. The algorithm proceeds iteratively through levels, with each level corresponding to a stage of the transformation process. At each level, all nodes are expanded to generate successor nodes, and their partial edit distances (PED) are evaluated. The best K nodes, based on their PED, are then selected to form the next level of the search tree. This selective exploration process aims to balance computational efficiency with approximation accuracy, as a larger K increases the likelihood of finding the optimal edit path.
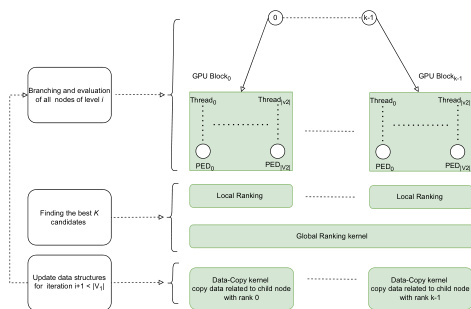
Refer to the framework diagram for a high-level overview of the process. The algorithm begins with an initial problem state and iteratively processes each level of the search tree. The core of the method is a two-phase parallelization strategy implemented on a GPU. The first phase, branching and evaluation, generates all successor nodes for the current level and computes their PED. Each GPU block is assigned a node from the current level, and the threads within that block are responsible for generating and evaluating one successor each. This involves mapping a vertex from the first graph g1 to a vertex in the second graph g2 using a substitution operation, or performing a deletion operation. The evaluation of a successor node requires calculating the cost of the new vertex edit operation and the implied edge operations. The implied edge costs are computed by analyzing the interaction between the newly mapped vertex and the vertices in the current edit path, considering all possible edge substitutions, insertions, and deletions.
The second phase, selection, identifies the best K nodes from the newly generated candidates to proceed to the next iteration. To efficiently find the top K candidates without the overhead of a full sort, the method employs a two-step ranking process. First, within each GPU block, the threads perform a local ranking to determine the best L candidates (e.g., L=5). These top candidates then update a global list of the best PED values using atomic operations. Second, a separate kernel assigns global ranks to the threads, identifying the top K candidates. This approach ensures that the selection process is scalable and suitable for GPU execution. The entire process repeats until the final level is reached, at which point the best path found is returned as the approximate GED solution.
The architecture is designed to maximize the utilization of GPU parallelism. The branching and evaluation phase is mapped to GPU blocks and threads, with each thread handling one successor node, enabling massive parallelization. The selection phase leverages the GPU's shared memory and atomic operations to efficiently perform local and global ranking. The framework's complexity analysis reveals that the time complexity is O(n2) for the parallelized version, where n is the maximum number of vertices in the two graphs, a significant improvement over the sequential O(Kn3) complexity. The space complexity is O(K⋅n), which is manageable due to the efficient use of GPU memory hierarchies.
Experiment
The evaluation setup tests FAST-GED against state-of-the-art CPU-based methods across small random and medium real-world datasets, while varying graph densities, GPU architectures, and search tree parameters. These experiments validate the framework's near-optimal accuracy and consistent scalability, demonstrating that GPU parallelism and memory optimizations effectively overcome the computational bottlenecks of traditional sequential approaches. Qualitatively, the results confirm that the method maintains reliable performance regardless of graph complexity while offering a tunable balance between precision and efficiency. Ultimately, FAST-GED proves highly practical for large-scale applications, enabling previously prohibitive tasks like graph classification and neural architecture search to be executed rapidly and accurately.
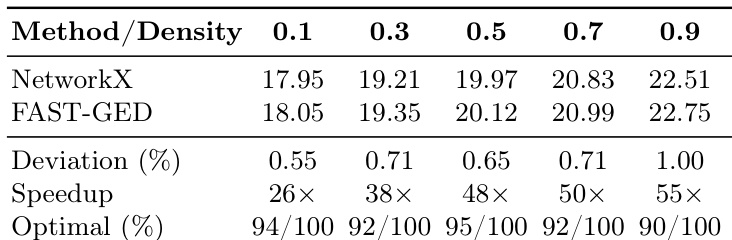
The authors evaluate FAST-GED against NetworkX on small random graphs, showing that FAST-GED achieves near-optimal results with minimal deviation and significant speedup. The performance remains consistent across different graph densities, demonstrating robustness and scalability. FAST-GED achieves less than 1% deviation from optimal results while providing substantial speedup compared to NetworkX. The speedup increases with graph density, and FAST-GED maintains consistent performance across varying graph structures. FAST-GED consistently reaches optimal edit distances in over 90% of cases for small random graphs.
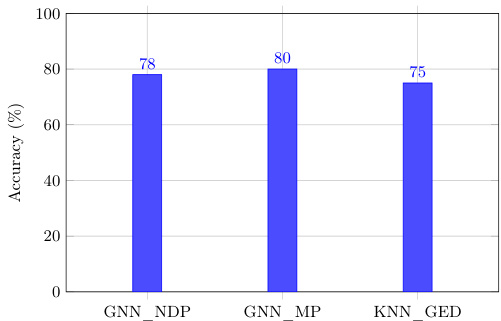
The authors evaluate the performance of FAST-GED, a GPU-accelerated graph edit distance method, against state-of-the-art approaches on various datasets and applications. Results show that FAST-GED achieves high accuracy and significant speedup compared to traditional methods, demonstrating its effectiveness in graph classification tasks. The method's performance is robust across different graph sizes and cost settings, with scalability maintained through GPU parallelism. FAST-GED achieves high accuracy comparable to advanced graph neural networks while being interpretable and easy to implement. The method demonstrates substantial speedup over traditional approaches, enabling practical use for large-scale graph analysis. FAST-GED maintains consistent performance across different graph sizes and cost settings, with accuracy improving as the number of retained nodes increases.
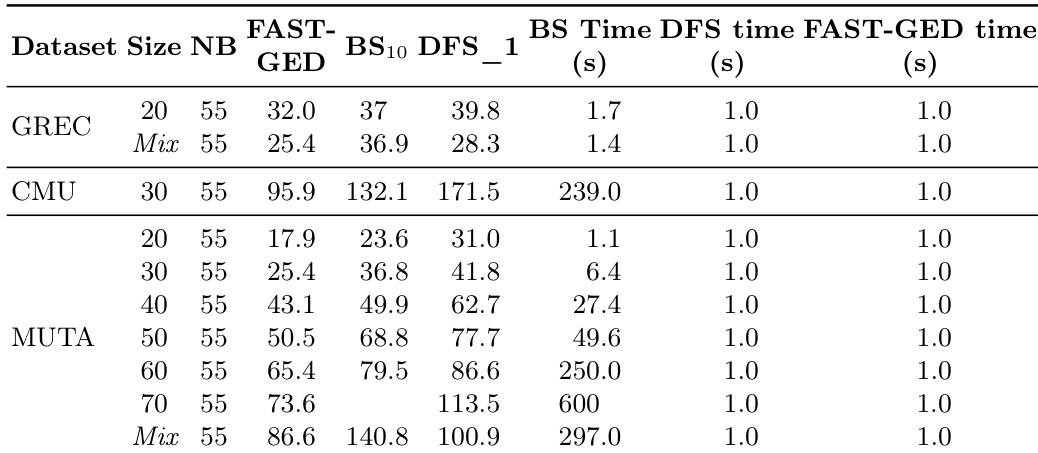
The authors evaluate FAST-GED against state-of-the-art approximate methods on medium-sized real-world datasets, demonstrating its superior accuracy and speed. Results show that FAST-GED achieves lower mean edit distances than baseline approaches across all datasets while maintaining execution times under one second. The method's performance is consistent across different graph sizes and scales efficiently with increasing graph complexity due to GPU parallelism. FAST-GED achieves lower mean edit distances than BS and DFS_1 across all datasets while maintaining execution times under one second. FAST-GED demonstrates consistent performance across different graph sizes and scales efficiently with increasing graph complexity due to GPU parallelism. The method's accuracy improves with increased node retention, showing a rapid improvement phase followed by a slow convergence to optimal edit distance.
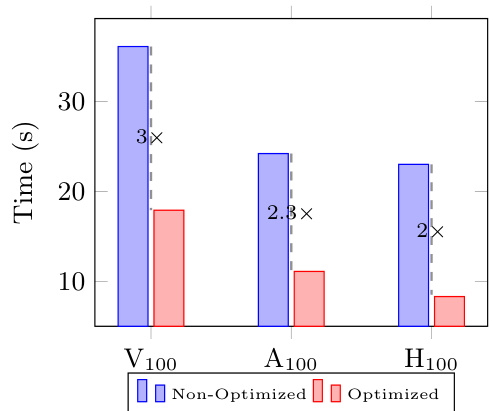
The authors evaluate the performance of FAST-GED on different GPU architectures, comparing optimized and non-optimized versions. Results show that the optimized version significantly reduces execution time across all GPU generations, with the performance improvement being more pronounced on older hardware. The optimized version achieves a consistent speedup over the non-optimized version, demonstrating the effectiveness of the proposed optimizations. The optimized version of FAST-GED achieves a significant speedup over the non-optimized version on all GPU architectures. The speedup improvement is most substantial on the V100 GPU, where the optimized version is three times faster. The optimized version reduces the runtime of the final data preparation step from 40% to 5% of the total runtime.
The experiments evaluate FAST-GED against traditional and approximate baselines across small random graphs, real-world datasets, and multiple GPU architectures to validate its computational efficiency, accuracy, and hardware adaptability. Results demonstrate that the method consistently achieves near-optimal edit distances while delivering substantial speedups, maintaining robust performance across varying graph densities, sizes, and algorithmic cost settings. Hardware evaluations further confirm that optimized GPU implementations significantly reduce execution times, particularly on older architectures, without compromising accuracy. Collectively, these findings establish FAST-GED as a highly scalable, interpretable, and practical solution for efficient large-scale graph analysis.