Command Palette
Search for a command to run...
LLM 기반의 소셜 미디어 상황 신호에 대한 위기 보고서 작성 시 불확실성 평가
LLM 기반의 소셜 미디어 상황 신호에 대한 위기 보고서 작성 시 불확실성 평가
Timothy Douglas Roben Delos Reyes Asanobu Kitamoto
초록
소셜 미디어는 재난 상황에서 상황 인식의 핵심 원천으로 자리 잡았으며, 진화하는 영향과 새롭게 대두되는 필요성에 대한 실시간 통찰력을 제공합니다. 대규모 위기 대응을 지원하기 위해 최근 연구들은 대규모 언어 모델(LLM)을 활용해 소셜 미디어 스트림에서 추출한 상황 정보를 자동으로 분류하고 요약하는 데 점점 더 많이 의존하고 있습니다. 그러나 기존 접근 방식은 위기 전개 과정에서 정보의 질이 현저히 달라짐에도 불구하고, 추출된 상황 주장들이 모두 동일한 정도로 타당하다고 암묵적으로 가정합니다.본 연구에서는 소셜 미디어 주장의 타당성을 명시적으로 고려하는 자동화 상황 인식 보고를 위한 불확실성 인식 프레임워크를 제안합니다. 먼저, 우리는 잘 정립된 상황 인식 스키마에 따라 소셜 미디어 게시물을 분류합니다. 둘째, 외부 프록시 데이터를 조건으로 주어 개별 상황 주장이 현실 조건을 타당하게 반영하는지 평가하고, 해당 판단에 대한 모델의 신뢰도를 명시적으로 도출하는 불확실성 평가 계층을 도입합니다. 셋째, 이러한 불확실성 평가를 활용하여 단순히 무엇을 보고하는지만 아니라 보고의 확신 정도까지 전달하는 위기 보고서를 생성합니다.우리는 이 프레임워크를 미국 지질조사국(USGS) PAGER의 영향 요약서를 대표적인 외부 프록시 데이터로 사용하여 20만 개가 넘는 지진 관련 트위터(X) 게시물에 적용했습니다. 우리는 불확실성을 명시적으로 표현하는 것이 시간적 압박 하에서 정보를 우선순위를 정하는 인간 위기 커뮤니케이터를 지원하며, 대규모 언어 모델 기반 상황 인식 파이프라인에 외부 프록시 데이터를 통합하기 위한 프레임워크를 제공한다고 주장합니다.
One-sentence Summary
Addressing the assumption that all extracted social media claims are equally reliable, the authors propose an LLM-based uncertainty-aware framework that classifies posts using a situational awareness schema, evaluates claim plausibility against external proxy data (USGS PAGER impact summaries) while explicitly eliciting model confidence, and generates crisis reports communicating both reported events and their associated certainty across over 200,000 earthquake-related Twitter/X posts.
Key Contributions
- This work presents an uncertainty-aware framework for automated situational awareness reporting that explicitly evaluates the plausibility of social media claims rather than assuming uniform reliability across disaster response streams.
- The framework integrates an uncertainty assessment layer that conditions claim plausibility on external proxy data to elicit model confidence, which subsequently drives a quadrant-based report generation process that communicates both situational information and associated certainty levels.
- Evaluation across six earthquake case studies validates the approach by processing over 200,000 Twitter/X posts and utilizing USGS PAGER impact summaries as external reference data to differentiate signal reliability.
Introduction
Social media has become a critical real-time source of situational awareness during disasters, enabling emergency responders to track evolving impacts and coordinate resources efficiently. Recent automated reporting pipelines leverage large language models to classify and summarize these social media streams, but they typically assume that all extracted claims are equally plausible once filtered. This limitation is problematic because disaster information is often fragmented, contradictory, or unverified, meaning that treating every signal uniformly can amplify noise or obscure genuine but atypical reports. To resolve this gap, the authors leverage an uncertainty-aware framework that conditions an LLM on both individual social media posts and external proxy data to evaluate claim plausibility. By explicitly eliciting model confidence alongside these plausibility scores, the system structures downstream crisis reports around distinct uncertainty profiles, allowing human analysts to triage information and prioritize actionable insights under time pressure.
Dataset
-
Dataset Composition and Sources
- The authors use short-form, user-generated posts from X (formerly Twitter) as the primary social media source.
- The core collection is a curated earthquake corpus originally compiled by Li et al., which has been widely adopted in crisis informatics benchmarks.
- External real-world proxy data is sourced from the USGS PAGER system and ShakeMap, providing near-real-time impact estimates and shaking intensity metrics.
-
Key Details for Each Subset
- The social media subset contains geolocated earthquake tweets spanning multiple events with varying magnitudes, geographic contexts, and impact profiles.
- The proxy data subset provides structured, quantitative impact indicators that align spatially with the events under study.
- No explicit size metrics or filtering rules are detailed, but the corpus relies on prior peer-reviewed curation and direct mapping to USGS intensity estimates.
-
Usage and Processing Workflow
- The authors feed the curated tweets and corresponding USGS proxy data into a zero-shot LLM prompting framework to evaluate claim plausibility during disaster response.
- Rather than relying on traditional training splits or mixture ratios, the data is used for direct evaluation and uncertainty modeling, with the framework explicitly designed to remain platform-agnostic.
- Processing involves aligning tweet-level situational reports with event-level contextual evidence, enabling the model to systematically cross-reference social media claims against independent physical impact estimates.
-
Metadata Construction and Output Formatting
- The processed dataset is structured into a standardized JSON schema per tweet.
- Each entry includes the original index, unique tweet ID, situational categories, a 1-to-5 likert plausibility score, a 0-to-100 confidence metric, a discrepancy assessment, and a brief reasoning alignment.
- The pipeline also supports synthetic or simulated social media streams, allowing for evaluation under constrained data conditions.
Method
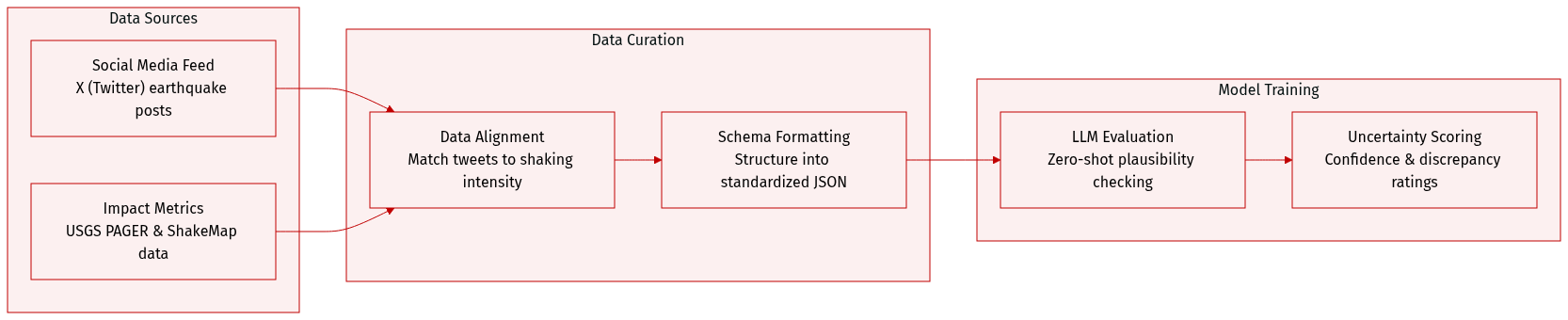
The proposed framework for uncertainty-aware crisis reporting operates as a modular pipeline designed to transform raw social media data into structured reports that explicitly convey the epistemic uncertainty of situational claims. The overall architecture consists of three sequential stages: situational awareness (SA) classification, uncertainty assessment, and report generation. As shown in the framework diagram, the process begins with data collection and the extraction of raw tweets, which are then processed by the SA classification model to assign one or more situational awareness labels. This step leverages zero-shot LLM prompting to treat classification as a multi-label task, allowing a single tweet to be associated with multiple SA categories, thereby capturing the multifaceted nature of crisis-related content. The output of this stage is a dataset of tweets enriched with SA labels. 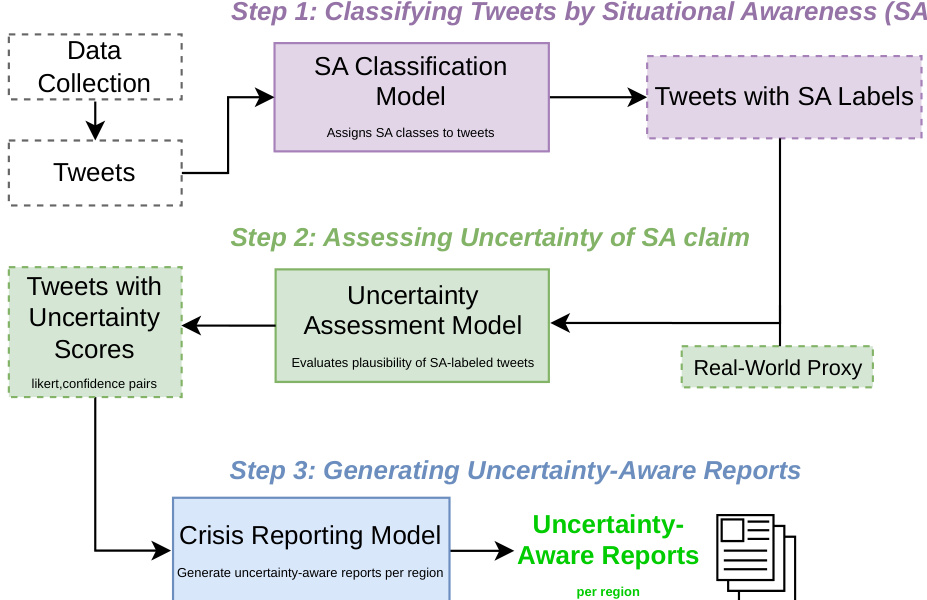
The second stage, uncertainty assessment, constitutes the core methodological contribution. This module evaluates the plausibility and confidence of each SA-labeled tweet. Plausibility is defined as the degree to which a tweet's situational claim is consistent with independently available, event-specific contextual evidence, while confidence reflects the model's self-expressed certainty in its own plausibility judgment. To perform this assessment, the framework incorporates structured external proxy data, which provides spatially aligned impact estimates for the crisis event. For each tweet, the model receives a prompt that combines the tweet's textual content, its assigned SA label, and a location-specific summary of the proxy data. This structured prompt enables the model to reason jointly over the claim and the external context. The uncertainty assessment is implemented using a confidence elicitation framework, which decomposes the task into three key components: a prompting strategy, a sampling strategy, and an aggregation strategy. The prompting strategy instructs the model to produce a graded plausibility score on a five-point Likert scale and a confidence score on a 0–100 scale. The sampling strategy generates multiple independent responses for each tweet to capture the variability in reasoning. Finally, the aggregation strategy combines these multiple responses to produce stable estimates of plausibility and confidence. The specific techniques for sampling and aggregation, such as Top-K and consistency-based methods, are adapted from prior work on confidence elicitation in LLMs. 
The output of the uncertainty assessment stage is a set of tweets, each annotated with a pair of scores representing plausibility and confidence. These scores are then fed into the final stage, the crisis reporting model, which synthesizes the uncertainty-aware situational claims into structured reports. The report generation process leverages the plausibility and confidence estimates to differentiate between information with varying degrees of certainty, allowing the system to produce summaries that not only state what is being claimed but also transparently communicate where uncertainty exists. This enables downstream users to prioritize information more effectively. The framework further operationalizes the plausibility-confidence space by partitioning it into four quadrants, which provides an interpretable structure for comparing and analyzing different types of situational signals. 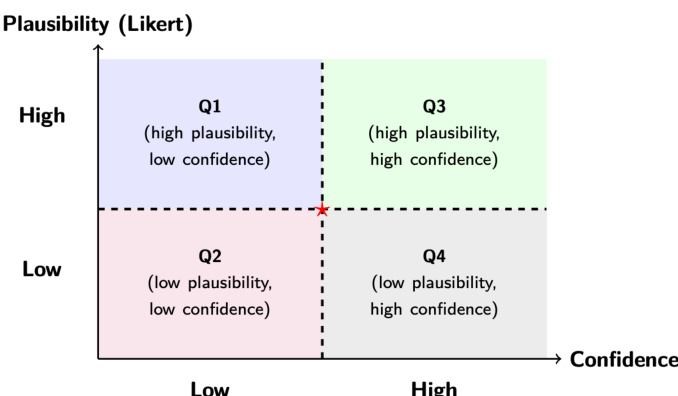
Experiment
The evaluation employs a large language model pipeline across six earthquake case studies to compare uncertainty-conditioned crisis reports against a uniform baseline. The first experiment validates whether the framework introduces structured epistemic differentiation by assigning graded plausibility and confidence scores to situational claims, successfully revealing measurable dispersion across distinct uncertainty profiles. The second experiment examines whether this tweet-level variation propagates into downstream report generation, demonstrating that uncertainty conditioning meaningfully alters semantic composition and internal coherence. Ultimately, the framework functions as a diagnostic tool that translates epistemic variation into structured narrative pathways, although dominant crisis themes can occasionally constrain downstream divergence.
The authors evaluate a framework that introduces uncertainty-aware structuring into situational awareness systems, assessing whether it creates measurable variation in situational claims and influences downstream report composition. Results show that the framework generates reports with distinct semantic characteristics, including differences in internal coherence and cross-report similarity, depending on the uncertainty profile of the input data. The framework introduces structured variation in uncertainty estimates at the tweet level, leading to differentiated situational claims. Reports generated from different uncertainty profiles exhibit measurable differences in internal coherence and semantic similarity. The impact of uncertainty conditioning varies across events, with some reports showing substantial divergence from baseline summaries.
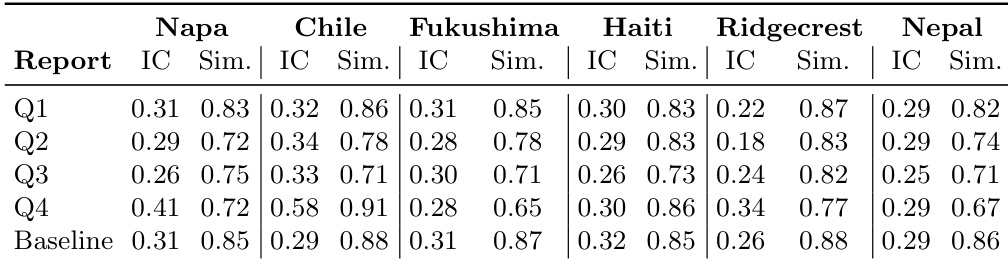
The authors evaluate a framework for uncertainty-aware situational awareness in crisis reporting by examining how uncertainty estimates at the tweet level influence downstream report composition. Results show that the framework introduces structured variation in epistemic assessments and leads to measurable differences in the semantic content and internal coherence of generated reports, though the extent of divergence varies across events. The framework introduces structured variation in uncertainty estimates at the tweet level, leading to differentiated situational claims. Reports generated from different uncertainty-conditioned tweet subsets exhibit measurable differences in semantic content and internal coherence. The impact of uncertainty on report generation varies by event, with some cases showing significant divergence and others maintaining similarity due to dominant crisis themes.
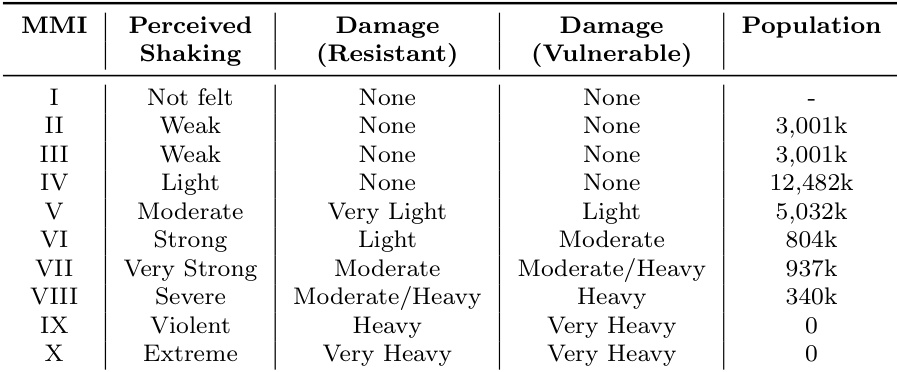
The authors evaluate a framework for uncertainty-aware situational awareness in crisis reporting, focusing on whether uncertainty estimates introduce structured variation in situational claims and whether this variation affects downstream report composition. The results show that the framework produces measurable differences in both the semantic content and internal coherence of generated reports across different uncertainty conditions. The framework introduces structured variation in uncertainty estimates at the tweet level, leading to differentiated situational claims. Reports generated under different uncertainty conditions exhibit measurable differences in semantic content and internal coherence. The impact of uncertainty on report composition varies by event, with some cases showing significant divergence and others maintaining similarity due to dominant crisis themes.
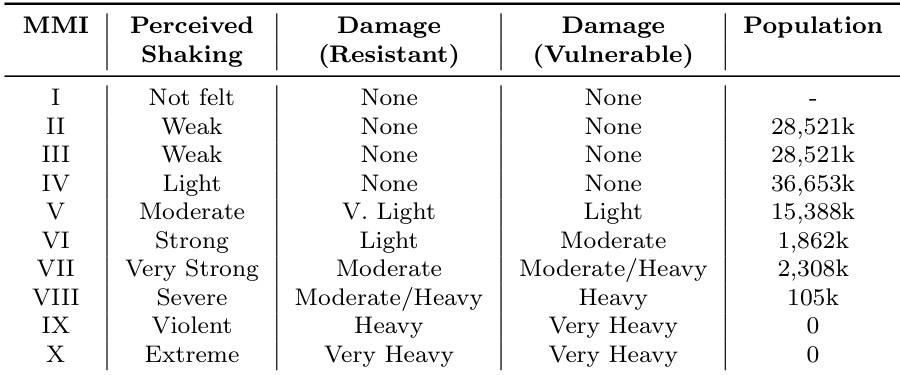
The authors evaluate an uncertainty-aware framework for situational awareness in crisis reporting by examining whether it introduces structured variation in situational claims and whether this variation affects the semantic composition of generated reports. Results show that the framework produces measurable differences in both the differentiation of uncertainty estimates at the tweet level and in the informational structure and internal coherence of downstream reports, with variation across events depending on the underlying data distribution. The framework introduces structured variation in uncertainty estimates at the tweet level, differentiating claims based on plausibility and confidence. Generated reports exhibit measurable differences in semantic content and internal coherence when conditioned on uncertainty profiles. The impact of uncertainty on report composition varies across events, with some showing distinct summaries and others maintaining similarity due to dominant thematic content.
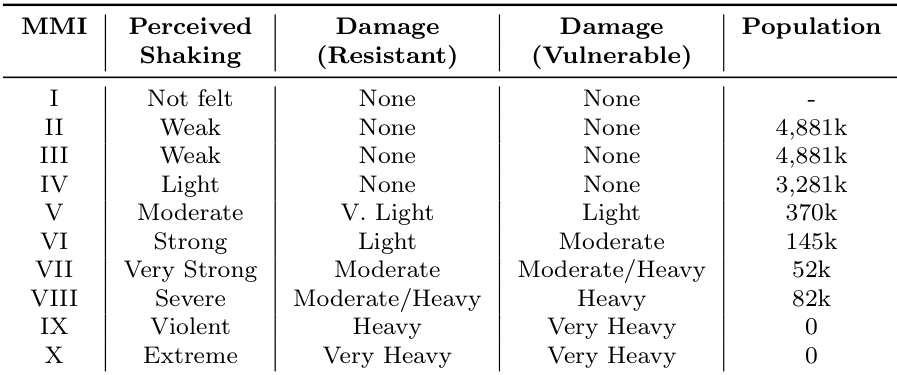
The authors evaluate a framework for uncertainty-aware situational awareness by examining whether uncertainty estimates introduce structured variation in situational claims and whether this variation affects the composition of generated crisis reports. Results show that the framework produces measurable differences in both the entropy of uncertainty estimates and the semantic structure of reports, with some reports exhibiting distinct content and higher internal coherence compared to baseline summaries. The uncertainty-aware framework introduces measurable variation in both plausibility and confidence estimates across different events. Reports generated from uncertainty-conditioned inputs show distinct semantic structures compared to baseline summaries. Some uncertainty-conditioned reports exhibit higher internal coherence, indicating more focused information organization.
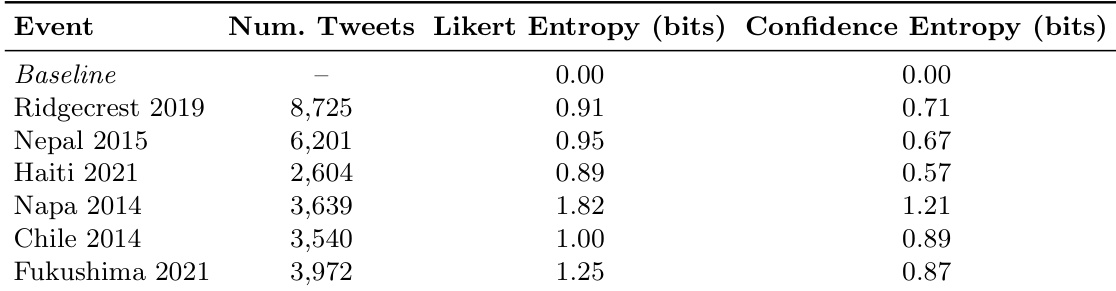
The authors evaluate an uncertainty-aware framework for crisis reporting by conditioning generated summaries on tweet-level uncertainty estimates to assess its impact on situational claims and downstream composition. The experiments validate whether integrating structured uncertainty profiles meaningfully alters the semantic content and organizational coherence of automated reports. Qualitative results demonstrate that uncertainty conditioning successfully differentiates claims and produces distinct semantic structures, though the degree of divergence from baseline summaries remains event-dependent and influenced by dominant thematic content.