Command Palette
Search for a command to run...
텍스트-영상 검색에서의 성능 정체기 이해: 포괄적인 경험적 및 언어학적 분석
텍스트-영상 검색에서의 성능 정체기 이해: 포괄적인 경험적 및 언어학적 분석
Maria-Eirini Pegia Dimitrios Stefanopoulos Björn Þór Jónsson Anastasia Moumtzidou Ilias Gialampoukidis Stefanos Vrochidis Ioannis Kompatsiaris
초록
텍스트-비디오 검색은 사용자가 자연어 쿼리를 활용해 관련 비디오 콘텐츠를 검색할 수 있도록 지원하는 기술로, 온라인 비디오의 급격한 확장과 함께 그 중요성이 커지고 있습니다. 지난 6년 동안 연구는 듀얼 인코더(dual encoders), 어텐션 기반 모델(attention-driven models), 그리고 멀티모달 융합 접근법(multimodal fusion approaches) 등 다양한 방법을 제시해 왔습니다. 그럼에도 불구하고 모델의 행동 양상, 데이터셋의 영향력, 그리고 쿼리의 난이도에 관한 근본적인 질문들은 아직 명확히 해소되지 않았습니다. 본 연구에서는 통합된 전처리 및 평가 프레임워크 하에서 14가지 최첨단 검색 방법을 3개의 널리 사용되는 데이터셋에서 평가합니다. 우리는 자막의 길이, 명확성, 의미적 카테고리, 그리고 액션(action) 대 장면(scene)의 균형과 같은 자막의 특성을 분석하고, 이러한 특성이 모델 성능과 어떻게 연관되는지 조사합니다. 결과 분석을 통해 단일 동작이나 색상 속성을 설명하는 등 짧고 명확하며 단순한 자막은 높은 재현율(recall)을 보이는 반면, 복잡한 사건, 다단계 활동, 세분화된 장면 설명 등은 기존 모든 모델에게 여전히 어려움을 안겨주고 있음을 확인했습니다. 어텐션 기반 아키텍처(attention-driven architectures)는 시간적 의존성이 있거나 다단계 쿼리를 더 효과적으로 처리하는 반면, 듀얼 인코더 및 멀티모달 융합 모델은 주로 단순하거나 단일 카테고리 자막에서 우수한 성능을 발휘합니다. 데이터셋 간 일반화 능력은 크고 다양한 자막 집합을 통해 향상되지만, 생성된 자막(generative captions)이 검색 정확도를 일관되게 향상시키지는 못했습니다. 전반적으로 본 연구의 소견은 중요한 데이터셋 요인, 벤치마크의 과제, 그리고 쿼리 내용과 모델 아키텍처 간의 상호작용을 부각시키며, 더 효과적인 텍스트-비디오 검색 시스템 개발을 위한 지침을 제공합니다.
One-sentence Summary
Through a comprehensive empirical and linguistic analysis evaluating fourteen state-of-the-art retrieval models across three datasets under a unified framework, this study demonstrates that attention-driven architectures outperform dual-encoder and multimodal fusion approaches on complex, temporally dependent queries, while short and semantically simple captions consistently yield higher recall across all evaluated systems.
Key Contributions
- Introduces a unified preprocessing and evaluation framework that systematically benchmarks fourteen state-of-the-art text-to-video retrieval models across three widely used datasets.
- Analyzes the correlation between query characteristics, including caption length, clarity, semantic category, and action versus scene balance, and overall retrieval performance.
- Demonstrates distinct architectural trade-offs, showing that attention-driven models excel at temporally dependent queries while dual-encoder and multimodal fusion approaches achieve higher recall on simpler, single-category captions.
Introduction
Text-to-video retrieval enables users to navigate massive video libraries using natural language, a capability that has become essential for semantic search, digital assistants, and personalized recommendation systems. Despite six years of architectural innovation, the field has stalled at a performance plateau while computational complexity continues to rise. Prior research suffers from inconsistent evaluation protocols, heavy reliance on aggregate metrics, and a fundamental lack of insight into how query difficulty, linguistic structure, and dataset composition actually drive retrieval outcomes. To address these gaps, the authors conduct a standardized evaluation of fourteen leading retrieval architectures across three major benchmarks, systematically isolating the impact of caption diversity, semantic categories, and temporal reasoning requirements. Their analysis reveals that model success hinges on query simplicity and dataset annotation quality, offering a clear framework for designing more rigorous benchmarks and next-generation retrieval systems.
Dataset

• Dataset Composition and Sources: The authors evaluate their method using three established video-text retrieval benchmarks sourced from public repositories: MSVD, MSRVTT, and LSMDC.
• Subset Details: MSVD (2012) and MSRVTT (2016) consist of short YouTube clips annotated with crowdsourced human captions. LSMDC (2015) contains movie clips from the 1990s to 2010s paired with professional audio descriptions. The LSMDC training split is filtered to 6,209 videos after removing corrupted files from the original 7,408. Each benchmark provides a fixed test set containing 1,000 queries for MSRVTT and LSMDC, and 670 queries for MSVD.
• Data Usage and Processing: The authors apply the default train and test splits provided by the original creators without modifying mixture ratios or training pipelines. To study caption diversity, they generate an extended LSMDC version by producing five additional captions per video using CLIP and Meta-Llama-3-8B-Instruct. The evaluation focuses on how models perform across different query distributions and dataset characteristics.
• Metadata Construction and Preprocessing: Textual queries are categorized into 10 semantic types using spaCy, NLTK, and sentence-transformers, with category expansions refined through Transformer similarity scores and WordNet synonyms. Queries that cannot be confidently assigned to a category are retained as unrecognized to prevent analysis noise. The authors do not implement custom cropping or frame extraction strategies, relying entirely on the original dataset preprocessing workflows and frame-splitting configurations.
Method
The authors leverage a comparative framework to analyze the relationship between textual query characteristics and video retrieval performance across multiple datasets and methods. The core of their methodology involves evaluating three distinct video retrieval architectures—LSMDC, MSVD, and MSRVTT—each representing a different model or dataset configuration. The evaluation is structured around a set of defined metrics and query difficulty classifications to assess performance under varying conditions.
Refer to the framework diagram 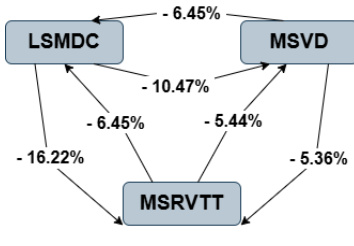 . The diagram illustrates the performance differences between the models, with percentage values indicating relative changes in retrieval performance. For instance, the MSVD model shows a 6.45% improvement over LSMDC, while MSRVTT exhibits a 16.22% improvement over LSMDC. These metrics are derived from the average ground-truth index of retrieved videos, which is used to define query difficulty. Queries are categorized into three levels based on their average rank: easy (rank < 200), medium (rank 401–600), and hard (rank > 800). This categorization enables a granular analysis of how each model handles queries of differing difficulty.
. The diagram illustrates the performance differences between the models, with percentage values indicating relative changes in retrieval performance. For instance, the MSVD model shows a 6.45% improvement over LSMDC, while MSRVTT exhibits a 16.22% improvement over LSMDC. These metrics are derived from the average ground-truth index of retrieved videos, which is used to define query difficulty. Queries are categorized into three levels based on their average rank: easy (rank < 200), medium (rank 401–600), and hard (rank > 800). This categorization enables a granular analysis of how each model handles queries of differing difficulty.
As shown in the figure below: 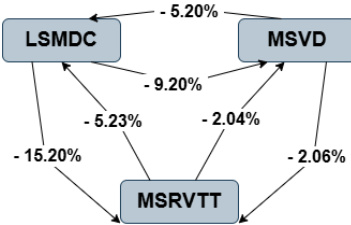 , the performance disparities among the models are further highlighted. The MSVD model again shows a 5.20% improvement over LSMDC, while MSRVTT demonstrates a 15.20% improvement. These differences are quantified through the relative performance gaps, which reflect the effectiveness of each model in retrieving relevant videos based on textual queries. The framework provides a systematic approach to understanding the impact of query composition and model architecture on retrieval outcomes.
, the performance disparities among the models are further highlighted. The MSVD model again shows a 5.20% improvement over LSMDC, while MSRVTT demonstrates a 15.20% improvement. These differences are quantified through the relative performance gaps, which reflect the effectiveness of each model in retrieving relevant videos based on textual queries. The framework provides a systematic approach to understanding the impact of query composition and model architecture on retrieval outcomes.
Experiment
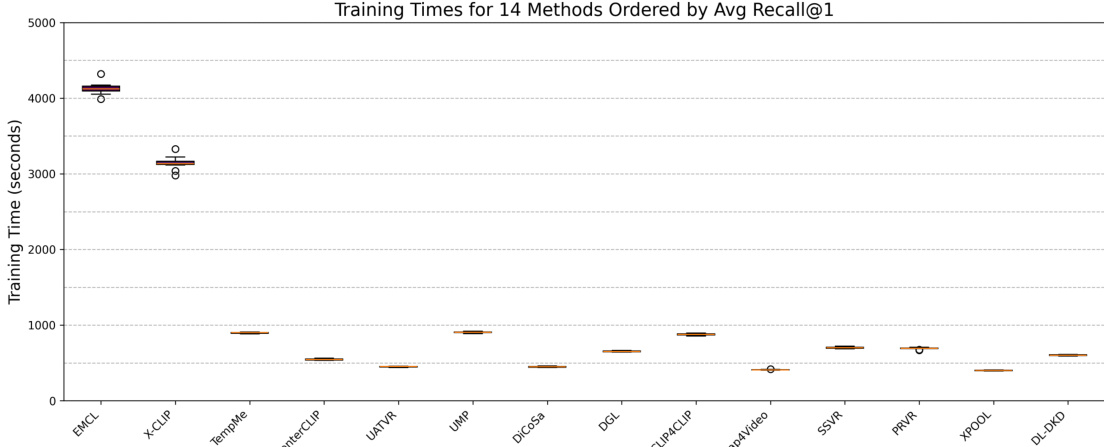
This study evaluates fourteen text-to-video retrieval models across three benchmark datasets under a unified training setup to assess architectural performance, training efficiency, and data sensitivity. The experiments validate how query semantics, caption diversity, and video preprocessing directly influence retrieval outcomes, revealing that success depends more on dataset characteristics than on model architecture. Clear, medium-length queries with concrete semantics consistently perform better, while abstract descriptions remain challenging, and models trained on multi-caption datasets demonstrate substantially improved cross-dataset generalization. Furthermore, sensitivity analyses confirm that aggressive compression or low frame rates reduce computational costs at the expense of retrieval accuracy, ultimately indicating that field progress has plateaued and highlighting the need for richer datasets and architectures capable of handling complex multimodal queries.
{"summary": "The authors evaluate 14 video-text retrieval methods using a consistent experimental setup across three benchmark datasets. The analysis reveals a trade-off between model performance and training efficiency, with some methods achieving high recall at the cost of significantly longer training times. The results also indicate that retrieval performance is influenced by factors such as query difficulty, caption quality, and dataset characteristics.", "highlights": ["Methods with higher average Recall@1 generally require longer training times, indicating a trade-off between performance and computational cost.", "Most methods exhibit similar training times, but a few top-performing models show substantially longer training durations.", "The evaluation highlights that model performance and efficiency are affected by dataset properties and query characteristics, not just model architecture."]
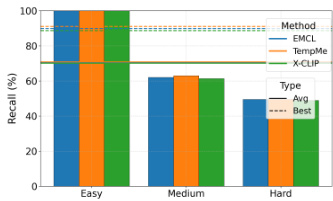
The authors analyze video-text retrieval performance across different query difficulty levels, showing that models achieve higher recall on easy queries compared to medium and hard ones. The results indicate that retrieval performance varies significantly with query difficulty, with the top-performing models demonstrating stronger performance on simpler queries. Models achieve higher recall on easy queries compared to medium and hard queries. Performance differences across difficulty levels are consistent across multiple retrieval methods. Top-performing models show stronger performance on easy queries, indicating a dependency on query simplicity.
{"summary": "The authors evaluate 14 video-text retrieval methods across three benchmark datasets, analyzing performance differences, task effects, and training efficiency under consistent settings. The study highlights that model performance is influenced by query characteristics such as length, clarity, and semantic type, as well as dataset properties like caption quantity and diversity, with datasets containing multiple captions enabling better generalization.", "highlights": ["Query characteristics such as length, clarity, and semantic type significantly affect retrieval performance, with medium-length and concrete queries performing better than complex or abstract ones.", "Datasets with multiple captions per video provide richer supervision and improve cross-dataset generalization compared to single-caption datasets.", "Top-performing models exhibit different strengths, with attention-based models handling complex queries better, while dual-encoder models perform well on simple or single-category queries."]
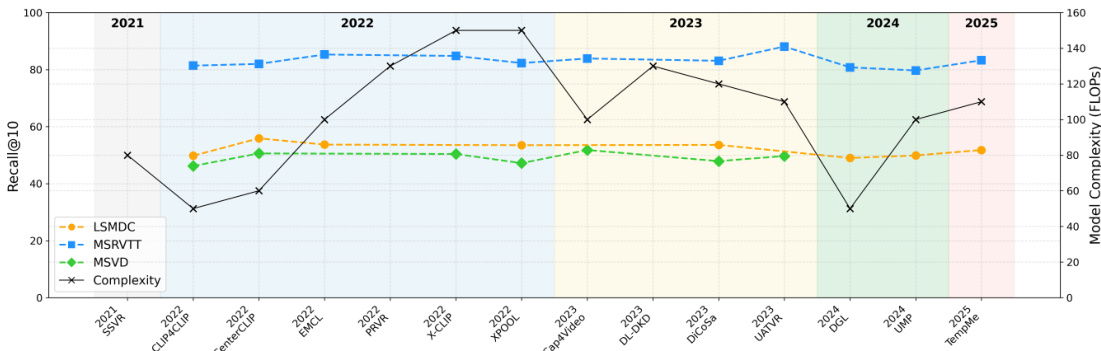
The authors analyze video-text retrieval models across multiple datasets and evaluate their performance based on recall metrics and model complexity. The results show that model performance varies significantly across datasets, with some methods achieving higher recall on certain datasets while others perform consistently. The analysis also highlights a trade-off between computational efficiency and retrieval accuracy, as more complex models tend to achieve better recall but require more training time. Performance varies across datasets, with some methods excelling on specific datasets while others maintain consistent results. There is a trade-off between model complexity and training efficiency, as more complex models achieve higher recall but require more computational resources. Model performance is influenced by dataset characteristics, including the number and quality of captions provided.
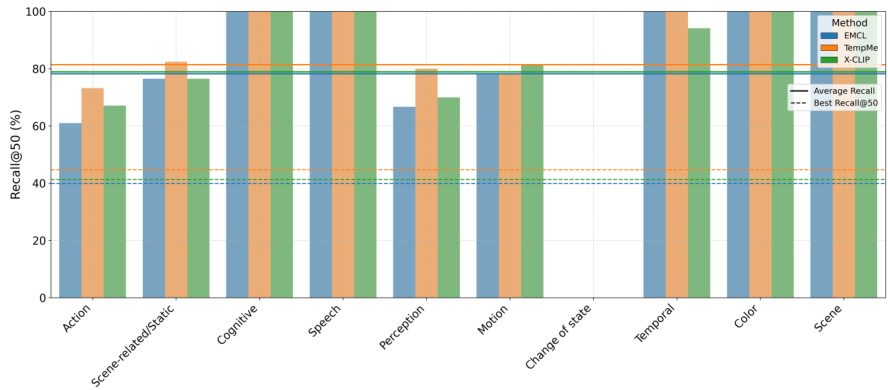
The authors analyze video-text retrieval models across different semantic categories, focusing on how query types influence performance. Results show that models achieve higher recall for concrete and simple queries such as Speech, Motion, and Color, while performance drops for more abstract or complex categories like Action and Scene-related/Static. The top-performing methods, EMCL, TempMe, and X-CLIP, exhibit varying strengths depending on the query type, with some showing consistent performance across categories and others being more sensitive to specific semantic types. Models achieve higher recall for concrete and simple query types such as Speech, Motion, and Color compared to abstract or complex categories. Performance varies significantly across semantic categories, with Action and Scene-related/Static queries being more challenging for retrieval. Top-performing methods show differing strengths across categories, indicating that model architecture influences sensitivity to query semantics.
The authors evaluate fourteen video-text retrieval methods across three benchmark datasets to assess overall performance, training efficiency, and sensitivity to input characteristics. The experiments validate that retrieval success depends heavily on query difficulty and semantic clarity, with models consistently outperforming on concrete queries compared to abstract ones, while datasets with multiple captions per video significantly improve generalization. Ultimately, the analysis reveals a clear trade-off between retrieval accuracy and computational cost, demonstrating that optimal model selection must balance architectural complexity with training efficiency and specific query demands.