Command Palette
Search for a command to run...
HERMES++: 3D 장면 이해 및 생성을 위한 통합 드라이빙 월드 모델의 실현
HERMES++: 3D 장면 이해 및 생성을 위한 통합 드라이빙 월드 모델의 실현
Xin Zhou Dingkang Liang Xiwu Chen Feiyang Tan Dingyuan Zhang Hengshuang Zhao Xiang Bai
초록
자동차 주행용 월드 모델은 환경 역학을 시뮬레이션함으로써 자율주행의 핵심 기술로 작용합니다. 그러나 기존 접근 방식은 주로 미래 장면 생성에 집중하여 포괄적인 3D 장면 이해를 간과하는 경향이 있습니다. 반면, 대규모 언어 모델(LLMs)은 뛰어난 추론 능력을 보여주지만 미래 기하학적 진화를 예측하는 능력은 부족하여, 의미론적 해석과 물리 시뮬레이션 사이에 중요한 격차가 존재합니다. 이 격차를 해소하기 위해 본 연구에서는 3D 장면 이해와 미래 기하학적 예측을 단일 프레임워크에 통합한 통합형 주행 월드 모델인 HERMES++를 제안합니다. 본 방법은 시너지 있는 설계를 통해 각 작업의 고유한 요구사항을 충족시킵니다. 먼저, BEV(Bird's-Eye View) 표현은 다중 뷰의 공간 정보를 LLM과 호환되는 구조로 통합합니다. 둘째, 이해(understanding) 브랜치에서의 지식 이행을 촉진하기 위해 LLM 강화 월드 쿼리를 도입합니다. 셋째, 시간적 간극을 해소하기 위해 Current-to-Future Link를 설계하여 기하학적 진화를 의미론적 맥락에 조건부 의존되게 만듭니다. 마지막으로, 구조적 무결성을 보장하기 위해 명시적 기하학적 제약조건과 잠재적 정규화(latent regularization)를 통합한 Joint Geometric Optimization 전략을 사용하여 내부 표현을 기하학적 정보 사전 지식(priors)과 정렬합니다. 여러 벤치마크에 대한 광범위한 평가를 통해 본 방법의 유효성이 검증되었습니다. HERMES++는 향후 포인트 클라우드 예측 및 3D 장면 이해 작업 모두에서 전문가 중심(approach) 모델들을 능가하는 강력한 성능을 입증했습니다. 모델과 코드는 https://github.com/H-EmbodVis/HERMESV2에서 공개될 예정입니다.
One-sentence Summary
The authors propose HERMES++, a unified driving world model integrating 3D scene understanding and future geometry prediction via BEV representation, LLM-enhanced world queries, a Current-to-Future Link, and Joint Geometric Optimization to bridge semantic interpretation with physical simulation, outperforming specialist approaches in both future point cloud prediction and 3D scene understanding tasks on multiple benchmarks.
Key Contributions
- This work presents HERMES++, a unified driving world model that integrates 3D scene understanding with future geometry prediction within a single framework. The approach consolidates multi-view spatial information into a structure compatible with large language models to bridge the disparity between semantic interpretation and physical simulation.
- Technical mechanisms include LLM-enhanced world queries for knowledge transfer and a Current-to-Future Link that conditions geometric evolution on semantic context. Structural integrity is enforced by a Joint Geometric Optimization strategy that aligns internal representations with geometry-aware priors using explicit constraints and latent regularization.
- Extensive evaluations on multiple benchmarks demonstrate that the model outperforms specialist approaches in both future point cloud prediction and 3D scene understanding tasks. The model and code are publicly released to support further research in interpretable and predictive autonomous driving.
Introduction
Autonomous driving systems rely on world models to simulate environmental dynamics for safety-critical tasks like risk assessment and motion planning. However, current research often separates these capabilities, where generation-centric models predict future geometry without semantic reasoning, while language-based models understand the present scene but cannot anticipate spatial evolution. This disparity limits the holistic awareness required for reliable autonomous decision-making. To bridge this gap, the authors propose HERMES++, a unified framework that integrates 3D scene understanding with future point cloud prediction. They leverage a Bird's-Eye View representation to consolidate multi-view data for LLM compatibility and introduce a Joint Geometric Optimization strategy to ensure structural integrity. By connecting semantic context with geometric evolution through LLM-enhanced world queries, the model achieves superior performance across both understanding and generation benchmarks.
Dataset
The authors utilize five datasets to support geometric learning, instruction tuning, and vision-language alignment.
- NuScenes: Serves as the primary benchmark for geometric representation and unified training using multi-view images and synchronized point clouds. Evaluation focuses on future scene consistency within a Region of Interest defined by x, y in [-51.2m, 51.2m] and z in [-3m, 5m] using bidirectional Chamfer Distance.
- OmniDrive-nuScenes: Applied during the refinement phase and for unified instruction tuning. This subset enriches NuScenes with high-quality scene descriptions and visual question-answering pairs to test reasoning about object interactions. Performance is measured via CIDEr, METEOR, and ROUGE-L.
- NuScenes-QA: A large-scale visual question-answering benchmark containing approximately 460k pairs constructed from 3D detection annotations. It evaluates the model's ability to interpret spatial relationships with top-1 accuracy.
- DriveLM: Introduces Graph Visual Question Answering on selected NuScenes keyframes to mimic human-like reasoning. It links perception, prediction, and planning questions through logical dependencies assessed by hybrid metrics.
- NuInteract: Provides approximately 1.5M diverse annotations including dense captions. The authors use this dataset to establish initial alignment between BEV visual features and the LLM semantic space during vision-language pre-training.
Method
The authors propose HERMES++, a unified driving world model designed to seamlessly integrate language-based reasoning with geometric generation. Unlike traditional approaches that treat scene understanding and future prediction as separate tasks, this framework leverages a shared Bird's-Eye View (BEV) representation to bridge perception and prediction. Refer to the framework diagram for a conceptual comparison of the proposed unified model against isolated generation and understanding systems. The model accepts multi-view images and textual instructions to generate both natural language descriptions and future 3D point cloud evolutions.
The core pipeline, illustrated in the detailed architecture diagram, begins with a visual tokenizer that transforms multi-view observations into a BEV representation. This process involves encoding perspective features from multiple cameras and projecting them into a top-down BEV grid using spatial cross-attention. To ensure compatibility with the Large Language Model (LLM), the high-dimensional BEV features are downsampled and flattened into visual tokens. These tokens, along with text tokens derived from user instructions, are fed into the LLM. The LLM processes this multimodal input to perform scene understanding tasks, such as answering questions about the current environment.
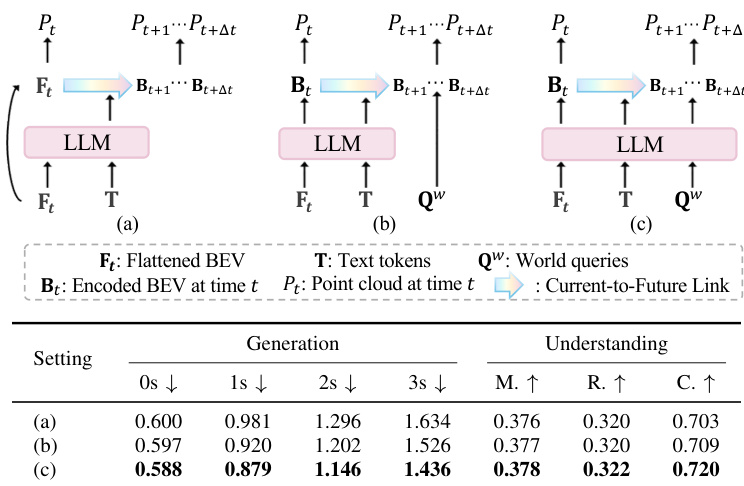
To facilitate knowledge transfer from the reasoning process to geometric prediction, the model introduces world queries. These learnable tokens act as latent placeholders that aggregate semantic context from both visual and textual inputs within the LLM. The enriched world queries, combined with ego-motion embeddings, are then passed to a Current-to-Future Link. This module propagates the encoded BEV features from the current timestamp to future time steps, conditioned on the semantic guidance provided by the world queries and text embeddings. This mechanism ensures that the predicted future scenes are semantically consistent with the current context and the vehicle's planned trajectory.
Finally, a shared Render module decodes the predicted BEV features into 3D point clouds. This renderer operates on the BEV features by upsampling them to their original resolution and expanding them into a volumetric representation. Using a neural rendering technique based on implicit signed distance functions, the model reconstructs the 3D geometry by querying the volumetric features along LiDAR rays. To strictly enforce structural integrity during training, the authors employ a Joint Geometric Optimization strategy. This strategy combines explicit geometric constraints on the rendered point clouds with implicit geometric regularization on the latent manifold, utilizing a frozen geometry extractor to align predicted features with geometry-aware priors. The entire system is trained using a composite objective that jointly optimizes language understanding, geometric rendering, and structural alignment.
Experiment
Comprehensive evaluations on NuScenes and OmniDrive-nuScenes benchmarks validate that HERMES++ effectively unifies understanding and generation tasks, outperforming specialist models without requiring auxiliary supervision. Qualitative analysis reveals that the framework preserves fine-grained semantic cues and maintains structural integrity during future scene prediction, while ablation studies confirm the necessity of BEV representations and joint geometric optimization for accurate spatial reasoning. Furthermore, the model demonstrates robust generalization across motion planning and additional datasets, with performance consistently improving as language model scale increases.
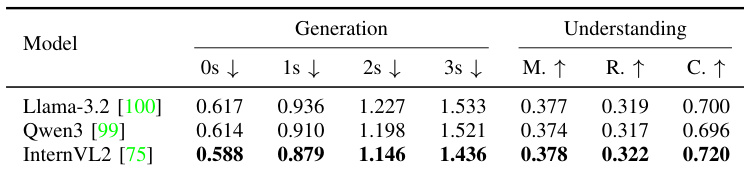
The authors evaluate the HERMES++ framework using different LLM backbones to verify its adaptability across various architectures. Results demonstrate that the InternVL2 backbone delivers superior performance in both geometric prediction and semantic understanding compared to Llama-3.2 and Qwen3. InternVL2 achieves the best generation accuracy across all time horizons from 0 to 3 seconds. The model utilizing InternVL2 attains the highest scores in understanding metrics such as CIDEr and METEOR. Comparative analysis reveals a consistent performance lead for InternVL2 over the other tested language models.
The authors analyze the integration of world queries to unify scene understanding and generation tasks. The results demonstrate that processing world queries directly through the LLM achieves superior performance compared to baselines that rely on textual injection or bypass the LLM. This full integration strategy leads to the lowest generation error and highest understanding scores among the tested configurations. Processing world queries through the LLM yields the best results for both future prediction and scene understanding. Separated unification baselines perform worse than methods that incorporate world queries. Intermediate strategies improve upon the baseline but do not match the fully integrated approach.
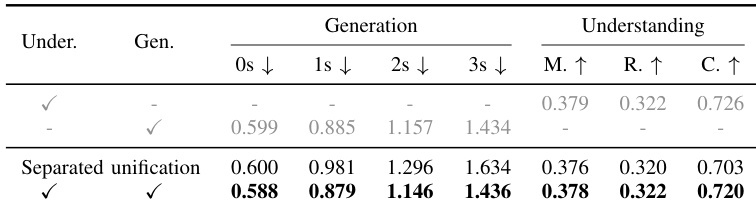
The experiment investigates the impact of task unification by comparing a separated baseline against a fully integrated framework. Results demonstrate that jointly optimizing understanding and generation tasks yields performance comparable to single-task specialists while significantly improving upon the separated unification baseline. The unified framework significantly outperforms the separated unification baseline across generation and understanding metrics. Joint task interaction reduces generation error at the 3-second horizon compared to the separated approach. The model achieves high understanding scores while maintaining precise future scene generation capabilities in a single architecture.
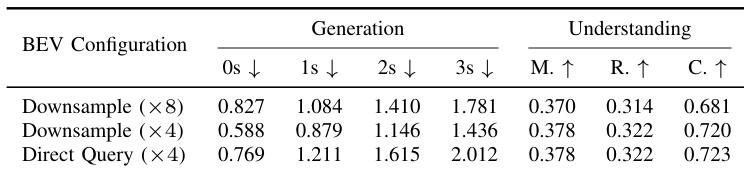
The authors investigate the impact of BEV spatial resolution on model performance by comparing different downsampling strategies against direct coarse querying. The results indicate that downsampling from a high-resolution feature map provides a superior balance between geometric accuracy and semantic understanding compared to other configurations. Specifically, moderate downsampling preserves essential structural details while avoiding the information loss associated with direct coarse queries or excessive compression. Downsampling from fine-grained features significantly outperforms direct coarse querying in future scene generation tasks. Excessive downsampling creates an information bottleneck that degrades both generation and understanding metrics. The configuration with moderate downsampling achieves the optimal trade-off, yielding the best generation accuracy and competitive understanding scores.
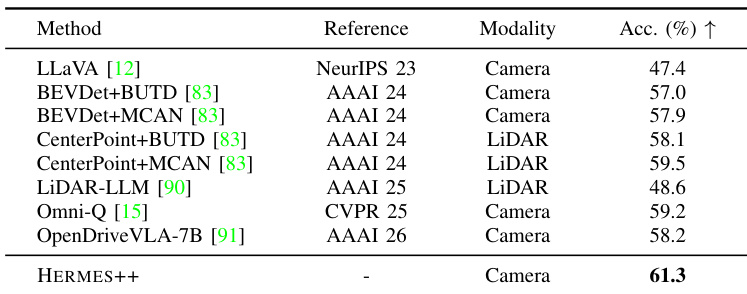
The authors evaluate the generalization capability of HERMES++ on the NuScenes-QA dataset for 3D spatial perception. The results demonstrate that the proposed framework achieves state-of-the-art performance, outperforming both generalist vision-language models and specialized LiDAR-based methods. HERMES++ achieves the highest accuracy among all compared methods. The camera-based approach outperforms LiDAR-based specialist models. The method significantly improves over other camera-based baselines.
The authors validate the HERMES++ framework through experiments on backbone selection, query integration, task unification, and spatial resolution. Comparative analysis reveals that the InternVL2 backbone and a fully unified approach processing world queries directly through the LLM yield superior performance compared to separated baselines. Additionally, optimizing BEV resolution via moderate downsampling and demonstrating state-of-the-art performance on the NuScenes-QA dataset confirms the model's robustness and generalization capabilities.